一.简介
SparkContext是Spark程序最主要的入口,用于与Spark集群连接。Spark集群的所有操作都通过SparkContext来进行,使用它可以在Spark集群上创建RDD、计数器以及广播变量。所有的Spark程序都必须创建一个SparkContext对象。进行流式计算时使用的StreamingContext以及进行SQL计算时使用的SQLContext也会关联一个现有的SparkContext或者隐式创建一个SparkContext对象。源码如下:
/** * Main entry point for Spark functionality. A SparkContext represents the connection to a Spark
* cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster. * * Only one SparkContext may be active per JVM. You must `stop()` the active SparkContext before * creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details. * * @param config a Spark Config object describing the application configuration. Any settings in * this config overrides the default configs as well as system properties. */ class SparkContext(config: SparkConf) extends Logging { // The call site where this SparkContext was constructed. private val creationSite: CallSite = Utils.getCallSite() // If true, log warnings instead of throwing exceptions when multiple SparkContexts are active private val allowMultipleContexts: Boolean = config.getBoolean("spark.driver.allowMultipleContexts", false) // In order to prevent multiple SparkContexts from being active at the same time, mark this // context as having started construction. // NOTE: this must be placed at the beginning of the SparkContext constructor. SparkContext.markPartiallyConstructed(this, allowMultipleContexts) val startTime = System.currentTimeMillis() private[spark] val stopped: AtomicBoolean = new AtomicBoolean(false) private[spark] def assertNotStopped(): Unit = { if (stopped.get()) { val activeContext = SparkContext.activeContext.get() val activeCreationSite = if (activeContext == null) { "(No active SparkContext.)" } else { activeContext.creationSite.longForm } throw new IllegalStateException( s"""Cannot call methods on a stopped SparkContext. |This stopped SparkContext was created at: | |${creationSite.longForm} | |The currently active SparkContext was created at: | |$activeCreationSite """.stripMargin) } } def this() = this(new SparkConf()) def this(master: String, appName: String, conf: SparkConf) = this(SparkContext.updatedConf(conf, master, appName)) def this( master: String, appName: String, sparkHome: String = null, jars: Seq[String] = Nil, environment: Map[String, String] = Map()) = { this(SparkContext.updatedConf(new SparkConf(), master, appName, sparkHome, jars, environment)) }
private[spark] def this(master: String, appName: String) = this(master, appName, null, Nil, Map()) private[spark] def this(master: String, appName: String, sparkHome: String) = this(master, appName, sparkHome, Nil, Map())
private[spark] def this(master: String, appName: String, sparkHome: String, jars: Seq[String]) = this(master, appName, sparkHome, jars, Map()) // log out Spark Version in Spark driver log logInfo(s"Running Spark version $SPARK_VERSION")
二.SparkConf配置
初始化SparkContext时,只需要一个SparkConf配置对象作为参数即可。保存配置的SparkConf类的定义在相同目录下的SparkConf.scala文件中,它最主要的成员是一个散列表,其中Key和value的类型都是字符串类型:

虽然SparkConf提供了一些简单的接口来进行配置,但其实所有的配置都以<key,value>对的形式保存在setting中,比如设置master方法就是设置了配置项spark.master。
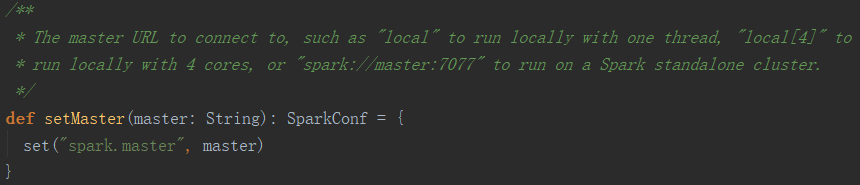
所以,使用配置文件中的spark.master配置项,或者参数列表中的--master选项,或者setMaster()方法,都可以设置Master地址,只是它们的优先级不同。
每个JVM只允许启动一个SparkContext,否则默认会抛出异常,比如在通过spark-shell启动的交互式编程环境下,已经默认创建了一个名为sc的SparkContext对象,如果直接创建一个StreamingContext对象,则会报错。一个简单的解决办法是先停止默认的sc。
当然,也可以通过设置spark.driver.allowMultipleContext为true来忽略这个错误,如下:

三.初始化过程
SparkContext在构造的过程中,已经完成了各项服务的启动。因为Scala语法的特点,所有构造函数都会调用默认的构造函数,而默认构造函数的代码直接在类定义中。除了初始化各类配置、日志之外,最重要的初始化操作之一是启动Task调度器和DAG调度器,代码如下:
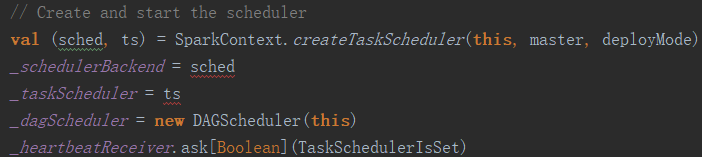
DAG调度与Task调度的区别是,DAG是高层次的调度,为每个Job绘制出一个有向无环图,跟踪各Stage的输出,计算完成Job的最短路径,并将Task提交给Task调度器来执行。而Task调度器只负责接受DAG调度器的请求,负责Task的实际调度执行,所以DAGScheduler的初始化必须在Task调度器之后。
DAG与Task这种分离设计的好处是,Spark可以灵活设计自己的DAG调度,同时还能与其他资源调度系统结合,比如YARN,Mesos等。
Task调度器本身的创建在createTaskScheduler函数中进行。根据Spark程序提交时指定的不同模式,可以启动不同类型的调度器。并且出于容错考虑,createTaskScheduler会返回一主一备两个调度器。以YARN cluster模式为例,主、备调度器对应 不同类的实例,但是加载了相同的配置。代码如下:
case masterUrl => val cm = getClusterManager(masterUrl) match { case Some(clusterMgr) => clusterMgr case None => throw new SparkException("Could not parse Master URL: '" + master + "'") } try { val scheduler = cm.createTaskScheduler(sc, masterUrl) val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler) cm.initialize(scheduler, backend) (backend, scheduler) } catch { case se: SparkException => throw se case NonFatal(e) => throw new SparkException("External scheduler cannot be instantiated", e) } }
四.其它功能接口
SparkContext除了可以初始化环境,连接Spark集群外,还提供了非常多的功能入口,具体如下:
1.创建RDD。所有的创建RDD的方法都在SparkContext中定义,比如parallelize和textFilenewAPIHadoopFile。
2.RDD持久化。RDD的持久化操作方法persistRDD、unpersistRDD也在SparkContext中定义。
3.创建共享变量。包括计数器和广播变量。
4.stop()。停止SparkContext。
5.runJob。提交RDD Action操作,这是所有调度执行的入口。