代码下载于 github,使用分支是 origin/branch-2.4
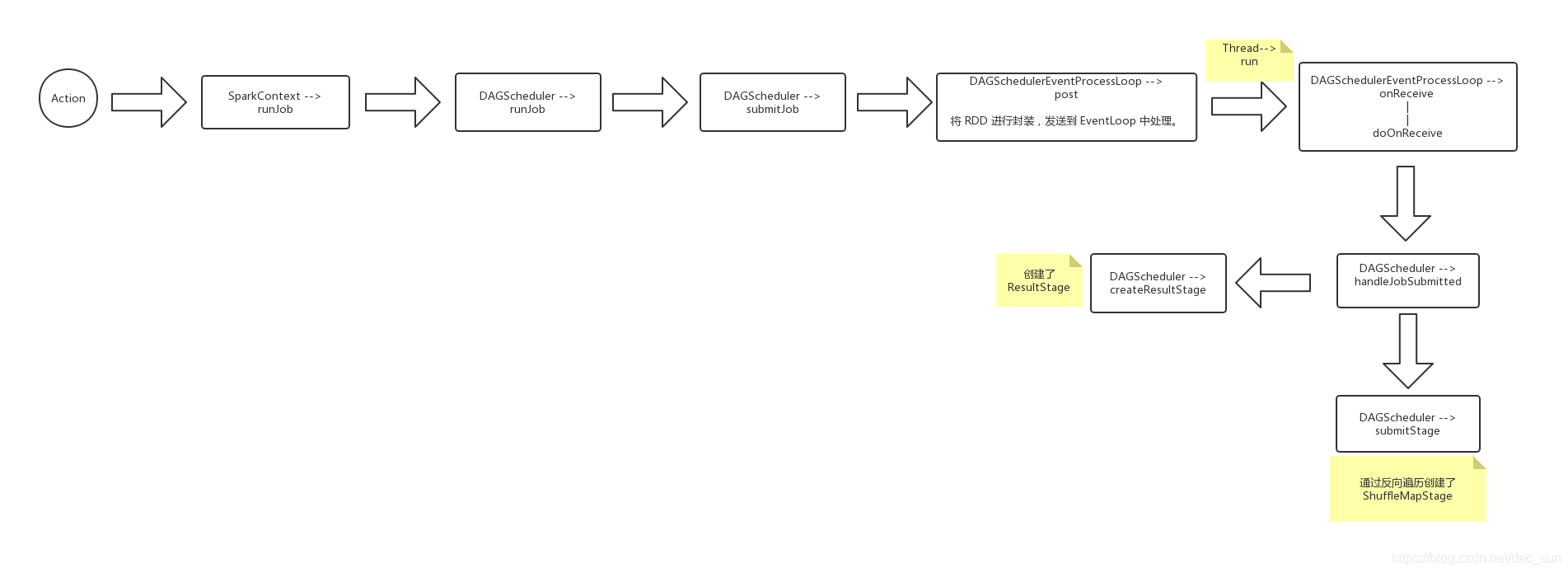
DAGScheduler 是实现了 面向 stage 的调度的高层次的调度层,它可以为每个 job 计算出一个 DAG,追踪 RDD和 stage 的输出是否被持久化,并且寻找到一个最优调度机制来运行 job,它会将 stage 作为 taskset 提交到底层的 TaskScheduler 来发送到集群上运行这些 task。此外它还决定了运行每个 task 的最佳位置,基于当前的缓存状态,将这些最佳位置提交给 底层的 TaskScheduler。兵器,它会处理由于 shuffle 输出文件丢失导致的失败,在这种情况下,旧的 stage 可能会被重新提交。一个 stage 内部的失败,如果不是由于 shuffle文件丢失导致的,会被 TaskScheduler 处理,它会被多次重试每一个 task,直到最后一个。实在不行,才会被取消整个 stage。
再次理解:Job、stage、TaskSet、Task
Job:当 Application 触发了一个 action,就会创建一个 job;
stage:一个 job 被拆分成多组任务来处理任务,每组任务由 stage 来封装;
TaskSet:一个 stage 就是一个 taskset。只是在不同阶段的名字而已;
Task:一个 taskSet 中包括多个 task,这是一个独立的任务单元。是由 TaskScheduler 发送到 Executore 上去执行。
知道了 DAGScheduler 所起的作用,现在就通过源码分析。由于 job 是从 action 才开始触发创建,那么就先看看 action 函数。
-- RDD.scala
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
// this 是执行 action 的 RDD
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
这里可以显然看到 调用了 runjob 函数.
-- SparkContext.scala
// 在RDD中的一组给定分区上运行函数,并将结果传递给给定的处理函数。这是Spark中所有操作的主要入
// 口点。
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
val callSite = getCallSite
val cleanedFunc = clean(func)
// 实际交由 DAGScheduler 来处理,rdd 是当前执行 action 的 RDD。
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
在 DAGScheduler 中进行被调用
-- DAGScheduler.scala
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
// 通过 submitJob 来提交 job 任务,并返回一个 waiter
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
}
}
这里通过调用 submitJob 来进行执行,并将返回结果给 waiter,通过判断 waiter 来确定任务是否成功。
-- DAGScheduler.scala
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// 检查确保我们没有在一个不存在的分区上启动 task
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
这里有 JobSubmitted( jobId, rdd, func2, partitions.toArray, callSite, waiter, SerializationUtils.clone(properties))。
需要注意的是:rdd 是执行 action 的RDD。
这里的 JobSubmitted 是一个在目标RDD上提交了一个生成结果的作业
-- DAGSchedulerEvent.scala
private[scheduler] case class JobSubmitted(
jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties = null)
extends DAGSchedulerEvent
同时 eventProcessLoop.post(JobSubmitted( jobId, rdd, func2, partitions.toArray, callSite, waiter, SerializationUtils.clone(properties))),这是调用 DAGSchedulerEventProcessLoop,而DAGSchedulerEventProcessLoop 是继承至 EventLoop, 这里就涉及到了多线程了。通过 post 将事件放入事件队列。
通过 start,启动线程,直接执行了 DAGSchedulerEventProcessLoop 中的方法,
-- DAGScheduler.scala
// DAG调度程序的主事件循环。
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}
// 由于跟踪的 JobSubmitted,所以进行往下查看
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
}
通过 handleJobSubmitted, 这里到了 DAGScheduler 中.
-- DAGScheduler .scala
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
这里首先创建了一个 finalStage,其实现过程为:
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 获取或创建给定 RDD 的父 stage 列表。将使用提供的 FirstJobID 创建新的 stage。
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
// createResultStage 最终调用,这个方法主要是帮助寻找到 job 中所有的 shuffle 依赖。
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ArrayStack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
// 这里只要知道目前是创建了 ResultStage 操作。我们还要思考如何创建 ShuffleMapStage
这里再回到 handleJobSubmitted, 其通过 finalstage,来提交 stage。
-- DAGScheduler.scala
// 循环的提交 stage。
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 该 stage 是 finalStage。
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
从 上述源码分析可知,DAGScheduler 将最后一个 RDD,命名为 finalRDD,反向遍历 Application 应用中的所有算子,如果遇到 shuffle,就划分成 ResultStage,然后再根据这个 ResultStage 继续反向遍历,遇到 shuffle 算子就划为一个 stage,直到无法再遍历。