人工智能实战2019BUAA_第三次作业_刘星航(补)
1.导航
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 人工智能实战2019 |
| 这个作业的要求在哪里 | 这里 |
| 我在这个课程的目标是 | 理解并能应用一些常用的人工智能相关知识 |
| 这个作业在哪个具体方面帮助我实现目标 | 熟悉梯度下降过程 |
2.作业要求
- 使用minibatch的方式进行梯度下降
- 采用随机选取数据的方式
- batch size分别选择5,10,15进行运行
- 复习讲过的课程,并回答关于损失函数的 2D 示意图的问题:
3.具体代码实现
import numpy as np
import pandas as pd
from pathlib import Path
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (8, 8)
#两个数据文件
x_data_name = "TemperatureControlXData.dat"
y_data_name = "TemperatureControlYData.dat"
class CData(object):
def __init__(self, loss, w, b, epoch, iteration):
self.loss = loss
self.w = w
self.b = b
self.epoch = epoch
self.iteration = iteration
#进行数据读取
def ReadData():
Xfile = Path(x_data_name)
Yfile = Path(y_data_name)
if Xfile.exists() & Yfile.exists():
X = np.load(Xfile)
Y = np.load(Yfile)
return X.reshape(-1, 1),Y.reshape(-1, 1)
else:
return None,None
#进行数据的随机选取
def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X)//batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
#进行前向传播
def forward_prop(X, W, b):
return np.dot(X, W) + b
def backward_prop(X, y, y_hat):
dZ = y_hat - y
dW = 1/len(X)*X.T.dot(dZ)
db = 1/len(X)*np.sum(dZ, axis=0, keepdims=True)
return dW, db
def compute_loss(y_hat, y):
return np.mean(np.square(y_hat - y))/2
#进行学习率、epochs数、batch_size的设置
X, y = ReadData()
N, D = X.shape
learning_rate = 0.01
n_epochs = 50
batch_size = 10
W = np.random.randn(D, 1)
b = np.zeros(1)
best_loss = np.infty
W_lis = []
b_lis = []
loss_lis = []
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X, y, batch_size):
y_hat = forward_prop(X_batch, W, b)
dW, db = backward_prop(X_batch, y_batch, y_hat)
W = W - learning_rate*dW
b = b - learning_rate*db
W_lis.append(W[0, 0])
b_lis.append(b[0, 0])
loss = compute_loss(forward_prop(X, W, b), y)
loss_lis.append(loss)
if loss < best_loss:
best_loss = loss
plt.figure(figsize=(16, 10))
p5,=plt.plot(batch_result['5'])
p10,=plt.plot(batch_result['10'])
p15,=plt.plot(batch_result['15'])
plt.legend([p5,p10,p15],["batch_size=5","batch_size=10","batch_size=15"])
plt.ylim(0.004,0.01)
plt.xlim(0,1000)
plt.xlabel('epoch_times')
plt.ylabel('loss_MSE')
plt.show()4.运行结果
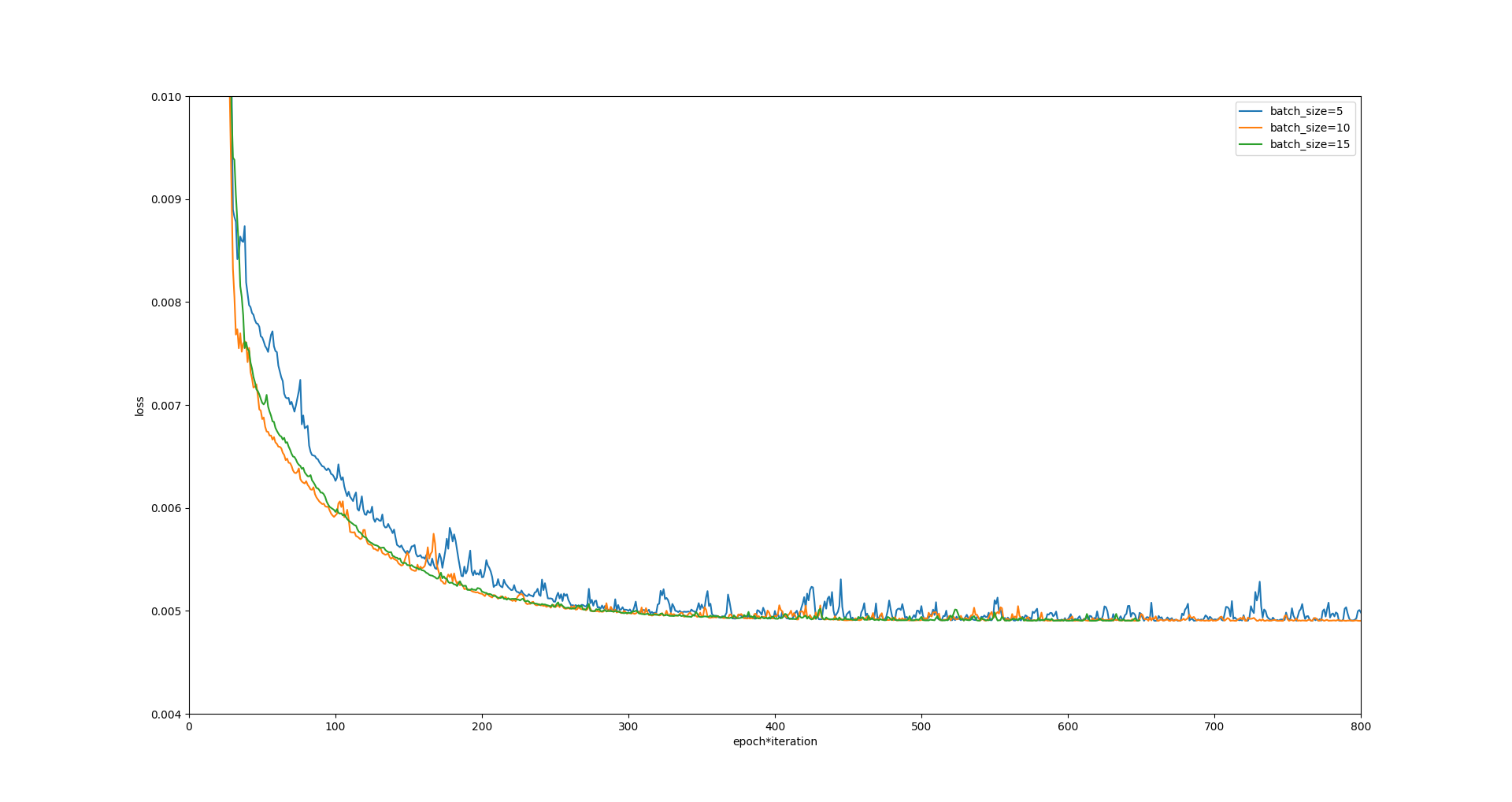
- eta=0.1
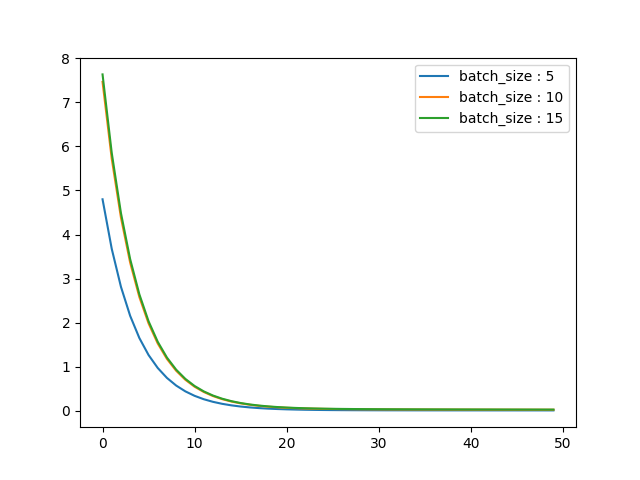
- eta=0.01
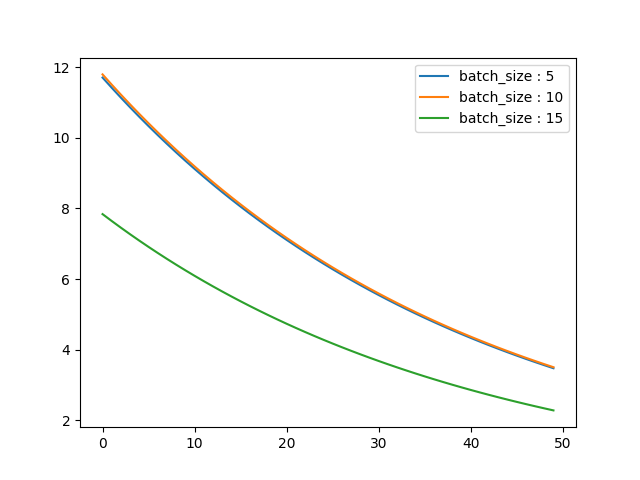
- eta=0.2

5. 总结与分析
- 随着学习率eta的增大,会在极值点附近产生跳跃,曲线波动增大,SGD的抖动也在逐渐增加
- batch size的的改变,会改变学习速度;batch size过大或过小都不利于提高学习速度
6. 思考题
1). 为什么是椭圆?
这个图形是由损失函数的特性导致的,如果需要画成圆,则需要将函数修改为类似于圆的函数
2). 为什么中心是个椭圆区域而不是一个点?
损失函数椭圆区域实际上是一堆离散的点,只是图被缩小,所以看上去像区域。
而且由于我们分析的(w, b)点对有限,所以很大可能并不存在全局最小的(w, b)点对,只能是区域。
同时我们的数据精度不够,导致原本不同的点由于精度的原因认为其相等。