目录
首先给出本次学习的参考教程 :
作者: ML小菜鸟
链接: ML神器:sklearn的快速使用
一、安装scikit-learn库
安装pip install -U scikit-learn
二、Python之回归模型学习
1、利用python的sklearn库自带的函数(线性回归,lasso回归,岭回归,弹性网络算法)对给定数据集进行预测分析。
2、分析线性回归算法的实现流程
3、分析代价函数的构造、梯度下降的实现、回归算法的构建过程;
4、根据算法描述编程实现算法,调试运行;
5、对所给数据集进行验算,得到分析结果。
(一)数据集读入
1.1导入sklearn数据集
参考教程:鸢尾花为例
1.2 创建数据集

from sklearn.datasets.samples_generator import make_classification
X, y = make_classification(n_samples=6, n_features=5, n_informative=2,
n_redundant=2, n_classes=2, n_clusters_per_class=2, scale=1.0,
random_state=20)
# n_samples:指定样本数
# n_features:指定特征数
# n_classes:指定几分类
# random_state:随机种子,使得随机状可重
for x_, y_ in zip(X, y):
print(y_, end=': ')
print(x_)
(二)数据预处理,根据需要进行标准化,归一化处理
2.1归一化:

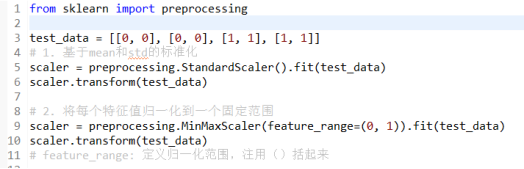
from sklearn import preprocessing
test_data = [[0, 0], [0, 0], [1, 1], [1, 1]]
# 1. 基于mean和std的标准化
scaler = preprocessing.StandardScaler().fit(test_data)
scaler.transform(test_data)
# 2. 将每个特征值归一化到一个固定范围
scaler = preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(test_data)
scaler.transform(test_data)
# feature_range: 定义归一化范围,注用()括起来
2.2正则化:


from sklearn import preprocessing
X = [[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]]
X_normalized = preprocessing.normalize(X, norm='l2')
print(X_normalized)
2.3one-hot编码是一种对离散特征值的编码方式
data = [[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]
encoder = preprocessing.OneHotEncoder().fit(data)
enc.transform(data).toarray()
(三)将数据集划分为训练集与测试集
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42)
X:输入特征,
y:输入标签,
random_state:随机种子,
test_size:测试样本数占比,为默认为0.25
[X_train, y_train] 和 [X_test, y_test]是一对,分别对应分割之后的训练数据和训练标签,测试数据和训练标签

# 作用:将数据集划分为 训练集和测试集
# 格式:train_test_split(*arrays, **options)
from sklearn import datasets
import numpy as np
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
X, y = np.arange(10).reshape((5, 2)), range(5)
print("X = ")
print(X)
print("list(y) = ")
print(list(y))
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
"""参数---
arrays:样本数组,包含特征向量和标签
test_size:
float-获得多大比重的测试样本 (默认:0.25)
int - 获得多少个测试样本
train_size: 同test_size
random_state:
int - 随机种子(种子固定,实验可复现)
shuffle - 是否在分割之前对数据进行洗牌(默认True)
返回
---
分割后的列表,长度=2*len(arrays),
(train-test split)
"""
#显示
print("X_train = ")
print(X_train)
print("X_test = ")
print(X_test)
print("y_train = ")
print(y_train)
print("y_test = ")
print(y_test)
(四)利用训练数据构建模型

4.1线性回归

4.2逻辑回归LR

4.3 朴素贝叶斯算法NB

4.4 决策树DT

4.5 支持向量机SVM
4.6 k近邻算法KNN

4.7 多层感知机(神经网络)

第四部分全部源码:
# 作用:将数据集划分为 训练集和测试集
# 格式:train_test_split(*arrays, **options)
from sklearn import datasets
from sklearn.datasets.samples_generator import make_classification # 引入数据集
import numpy as np
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split # 引入模型
"""
---------------第四节:7种回归模型---------------------------
"""
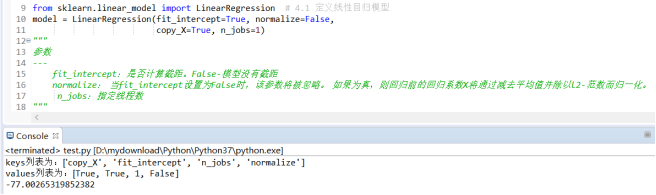
from sklearn.linear_model import LinearRegression # 4.1 定义线性回归模型
model = LinearRegression(fit_intercept=True, normalize=False,
copy_X=True, n_jobs=1)
"""
参数
---
fit_intercept:是否计算截距。False-模型没有截距
normalize: 当fit_intercept设置为False时,该参数将被忽略。 如果为真,则回归前的回归系数X将通过减去平均值并除以l2-范数而归一化。
n_jobs:指定线程数
"""
from sklearn.linear_model import LogisticRegression # 4.2 逻辑回归LR
model = LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100, multi_class='ovr',
verbose=0, warm_start=False, n_jobs=1)
"""
参数
---
penalty:使用指定正则化项(默认:l2)
dual: n_samples > n_features取False(默认)
C:正则化强度的反,值越小正则化强度越大
n_jobs: 指定线程数
random_state:随机数生成器
fit_intercept: 是否需要常量
"""
from sklearn import naive_bayes # 4.3朴素贝叶斯算法NB
model = naive_bayes.GaussianNB() # 高斯贝叶斯
model = naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
model = naive_bayes.BernoulliNB(
alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)
"""
文本分类问题常用MultinomialNB
参数
---
alpha:平滑参数
fit_prior:是否要学习类的先验概率;false-使用统一的先验概率
class_prior: 是否指定类的先验概率;若指定则不能根据参数调整
binarize: 二值化的阈值,若为None,则假设输入由二进制向量组成
"""
from sklearn import tree # 4.4决策树DT
model = tree.DecisionTreeClassifier(criterion='gini', max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=None, random_state=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
class_weight=None, presort=False)
"""参数
---
criterion :特征选择准则gini/entropy
max_depth:树的最大深度,None-尽量下分
min_samples_split:分裂内部节点,所需要的最小样本树
min_samples_leaf:叶子节点所需要的最小样本数
max_features: 寻找最优分割点时的最大特征数
max_leaf_nodes:优先增长到最大叶子节点数
min_impurity_decrease:如果这种分离导致杂质的减少大于或等于这个值,则节点将被拆分。
"""
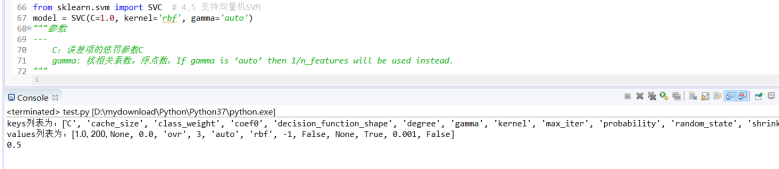
from sklearn.svm import SVC # 4.5 支持向量机SVM
model = SVC(C=1.0, kernel='rbf', gamma='auto')
"""参数
---
C:误差项的惩罚参数C
gamma: 核相关系数。浮点数,If gamma is ‘auto’ then 1/n_features will be used instead.
"""
from sklearn import neighbors # 4.6 k近邻算法KNN
# 定义kNN分类模型
model = neighbors.KNeighborsClassifier(n_neighbors=4, n_jobs=1) # 分类
model = neighbors.KNeighborsRegressor(n_neighbors=4, n_jobs=1) # 回归
"""参数
---
n_neighbors: 使用邻居的数目
n_jobs:并行任务数
"""
from sklearn.neural_network import MLPClassifier # 4.7 多层感知机(神经网络)
# 定义多层感知机分类算法
model = MLPClassifier(activation='relu', solver='adam', alpha=0.0001)
"""参数
---
hidden_layer_sizes: 元祖
activation:激活函数
solver :优化算法{‘lbfgs’, ‘sgd’, ‘adam’}
alpha:L2惩罚(正则化项)参数。
"""
"1读入数据"
X, y = make_classification(n_samples=6, n_features=5, n_informative=2,
n_redundant=2, n_classes=2, n_clusters_per_class=2, scale=1.0,
random_state=20)
"3数据集拆分"
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
# 拟合模型
model.fit(X_train, y_train)
# 模型预测
model.predict(X_test)
# 获得这个模型的参数
num = model.get_params()
# 通过list将字典中的keys和values转化为列表
keys = list(num.keys())
values = list(num.values())
# 结果输出
print("keys列表为:", end='')
print(keys)
print("values列表为:", end='')
print(values)
# 为模型进行打分
score = model.score(X_test, y_test) # 线性回归:R square; 分类问题: acc
print("score为:", end='')
print(score)
(五)用测试数据评价模型的性能

5.1交叉验证
from sklearn.model_selection import cross_val_score
cross_val_score(model, X, y=None, scoring=None, cv=None, n_jobs=1)"""参数
---
model:拟合数据的模型
cv : k-fold
scoring: 打分参数-‘accuracy’、‘f1’、‘precision’、‘recall’ 、‘roc_auc’、'neg_log_loss'等等"""
5.2 检验曲线
使用检验曲线,我们可以更加方便的改变模型参数,获取模型表现。

源码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
digits = load_digits()
X, y = digits.data, digits.target
param_range = np.logspace(-6, -1, 5)
train_scores, test_scores = validation_curve(
SVC(), X, y, param_name="gamma", param_range=param_range,
cv=5, scoring="accuracy", n_jobs=1)
"""参数
---
model:用于fit和predict的对象
X, y: 训练集的特征和标签
param_name:将被改变的参数的名字
param_range: 参数的改变范围
cv:k-fold
返回值
---
train_score: 训练集得分(array)
test_score: 验证集得分(array)
"""
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with SVM")
plt.xlabel(r"$\gamma$")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
lw = 2
plt.semilogx(param_range, train_scores_mean, label="Training score",
color="darkorange", lw=lw)
plt.fill_between(param_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color="darkorange", lw=lw)
plt.semilogx(param_range, test_scores_mean, label="Cross-validation score",
color="navy", lw=lw)
plt.fill_between(param_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color="navy", lw=lw)
plt.legend(loc="best")
plt.show()
(六)结果分析(可视化)
6.1 保存为pickle文件
import pickle
# 保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 读取模型
with open('model.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_test)
6.2 sklearn自带方法joblib
from sklearn.externals import joblib
# 保存模型
joblib.dump(model, 'model.pickle')
#载入模型
model = joblib.load('model.pickle')
三、模型训练
ex3data1.mat下载地址:ex3data1.mat

源码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
实现多类的逻辑回归算法
"""
import os
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
from scipy.optimize import minimize
from scipy.io import loadmat
# 定义Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义 cost函数
def costReg(theta, X, y, lambdas):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
h = X * theta.T
first = np.multiply(-y, np.log(sigmoid(h)))
second = np.multiply((1 - y), np.log(1 - sigmoid(h)))
reg = (lambdas / 2 * len(X)) * \
np.sum(np.power(theta[:, 1:theta.shape[1]], 2))
return np.sum(first - second) / (len(X)) + reg
# 梯度下降算法的实现, 输出梯度对权值的偏导数
def gradient(theta, X, y, lambdas):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
# 计算误差
error = sigmoid(X * theta.T) - y
grad = ((X.T * error) / len(X)).T + ((lambdas / len(X)) * theta)
grad[0, 0] = np.sum(np.multiply(error, X[:, 0])) / len(X)
return np.array(grad).ravel()
# 实现一对多的分类方法
def one_vs_all(X, y, num_labels, lambdas):
rows = X.shape[0]
params = X.shape[1]
# 每个分类器有一个 k * (n+1)大小的权值数组
all_theta = np.zeros((num_labels, params + 1))
# 增加一列,这是用于偏置值
X = np.insert(X, 0, values=np.ones(rows), axis=1)
# 标签的索引从1开始
for i in range(1, num_labels + 1):
theta = np.zeros(params + 1)
y_i = np.array([1 if label == i else 0 for label in y])
y_i = np.reshape(y_i, (rows, 1))
# 最小化损失函数
fmin = minimize(fun=costReg, x0=theta, args=(
X, y_i, lambdas), method='TNC', jac=gradient)
all_theta[i - 1, :] = fmin.x
return all_theta
def predict_all(X, all_theta):
rows = X.shape[0]
params = X.shape[1]
num_labels = all_theta.shape[0]
# 增加一列,这是用于偏置值
X = np.insert(X, 0, values=np.ones(rows), axis=1)
X = np.matrix(X)
all_theta = np.matrix(all_theta)
# 对每个训练样本计算其类的概率值
h = sigmoid(X * all_theta.T)
# 获取最大概率值的数组索引
h_argmax = np.argmax(h, axis=1)
# 数组是从0开始索引,而标签值是从1开始,所以需要加1
h_argmax = h_argmax + 1
return h_argmax
dataPath = os.path.join('data', 'ex3data1.mat')
# 载入数据
data = loadmat(dataPath)
print(data)
print(data['X'].shape, data['y'].shape)
# print(np.unique(data['y']))
# 测试
# rows = data['X'].shape[0]
# params = data['X'].shape[1]
#
# all_theta = np.zeros((10, params + 1))
#
# X = np.insert(data['X'], 0, values=np.ones(rows), axis=1)
#
# theta = np.zeros(params + 1)
#
# y_0 = np.array([1 if label == 0 else 0 for label in data['y']])
# y_0 = np.reshape(y_0, (rows, 1))
# print(X.shape, y_0.shape, theta.shape, all_theta.shape)
all_theta = one_vs_all(data['X'], data['y'], 10, 1)
print(all_theta)
# 计算分类准确率
y_pred = predict_all(data['X'], all_theta)
correct = [1 if a == b else 0 for (a, b) in zip(y_pred, data['y'])]
accuracy = (sum(map(int, correct)) / float(len(correct)))
print('accuracy = {0}%'.format(accuracy * 100))