一、机器学习以及scikit-learn
1. 机器学习基本步骤:
(1)定义一系列函数 => (2)定义函数的优劣 => (3)选择最优函数
2.什么是scikit-learn?
(1)面向python的免费机器学习库
(2)包含分类、回归、聚类算法,比如:SVM、随机森林、k-means等
(3)包含降维、模型选择、预处理等算法
(4)支持Numpy和Scipy数据结构
(5)用户
(6)安装:pip install scikit-learn
pip install scikit-learn
3.上手:
(1)加载数据集
iris
digits
(2)在训练集上训练模型
svm模型
.fit()训练模型
(3)在测试集上测试模型
.predict()进行预测
(4)保存模型
.pickle.dumps()
二、机器学习:问题描述
1.“学习”问题通常包含n个样本数据(训练样本),然后预测未知数据(测试样本)的属性
2.每个样本包含多个属性(多维数据)被称作“特征”
3.分类:
(1)监督学习,训练样本包含对应的标签,“如识别问题”
分类问题,样本标签属于两个或者多各类
回归问题,样本标签包括一个或者多个连续变量
(2)无监督学习,训练样本的属性不包含对应的“标签”,如聚类问题
(3)训练集vs验证集vs测试集
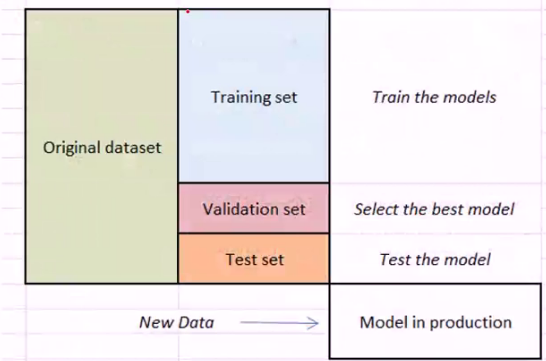
在没有生产的阶段,没有新的数据,通常会将原始数据集分为三部分:训练集、测试集和验证集,训练集用来训练模型,验证集用来选择最佳模型,调整参数,测试集用来测试模型