版权声明:该版权归博主个人所有,在非商用的前提下可自由使用,转载请注明出处. https://blog.csdn.net/qq_24696571/article/details/89009650
- kmeans算法用于聚类,给事物打标签,例如音乐分为纯音乐,古典音乐,流行音乐…
- 我们甚至可能不知道我们要怎么分类,分什么类, 通过数据训练模型自动得出,所以kmeans算法用于知识发现而不是预测.
- 聚类是一种无监督(没有因变量)的机器学习任务.
- 数据与数据划分之后的量化距离表示数据之间的相似度,数据与中心点的距离来划分分类.
- 距离测度方式:
- 欧式距离测度
- 平方欧式距离测度
- 曼哈顿距离测度
- 余弦距离测度
- 谷本距离测度
- 加权距离测度
- 选择适当的聚类数
- 肘部法
- 聚类的原则
- 类的成员之间越相似越好
- 类之间的成员差异越大越好
- kmeans算法的思想:以空间中K个点为中心进行聚类,对最靠近他们的对象归类,通过迭代方法,逐渐更新各个聚类中心的值,来直到得到最好的聚类结果.
- 缺陷: 1.聚类中心个数k要事先给定,但是k值的选定很难估计.大部分时候,在事先不知道数据应该分多少类才最合适. 2.kmeans需要认为确定初始时的聚类中心 , 不同的初始聚类中心可能会导致完全不同的聚类结果.
案例
1️⃣数据样式:
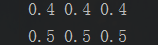
2️⃣代码:
package com.spark
import org.apache.spark.mllib.clustering._
import org.apache.spark.mllib.linalg
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object KMeans {
def main(args: Array[String]) {
//1 构建Spark对象
val conf = new SparkConf().setAppName("KMeans").setMaster("local")
val sc = new SparkContext(conf)
// 读取样本数据1,格式为LIBSVM format
val data = sc.textFile("F:\\code02\\sparkLearn\\src\\kmeans_data.txt")
// 数据切分后向量化成三维数据
val parsedData: RDD[linalg.Vector] = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// 聚类个数
val numClusters = 4
// 迭代次数
val numIterations = 100
// 创建kmeans对象
val model: KMeansModel = new KMeans().
//设置聚类个数
setK(numClusters).
//设置最大迭代次数
setMaxIterations(numIterations).
//数据导入运行 , 无监督没有因变量, 也不必测试集
run(parsedData)
val centers: Array[linalg.Vector] = model.clusterCenters
println("centers")
for (i <- 0 to centers.length - 1) {
//打印聚类中心
println(centers(i)(0) + "\t" + centers(i)(1) + "\t" + centers(i)(2))
}
// 计算误差 并打印
val WSSSE = model.computeCost(parsedData)
println("Errors = " + WSSSE)
//预测
println(model.predict(Vectors.dense(10, 10, 10)))
//保存模型
// val ModelPath = "KMeans_Model"
// model.save(sc, ModelPath)
// val sameModel = KMeansModel.load(sc, ModelPath)
}
}