前面写了分类和回归的一些算法,这些算法都属于监督学习,本篇的要讲的kmeans算法就属于非监督学习(unsupervised learning)中聚类问题的一个重要算法。
监督学习与非监督学习有什么区别呢?监督学习训练所用的数据样例都是有类别标记(class label)的,而非监督学习所用的数据则不需要类别标记。
先举个例子
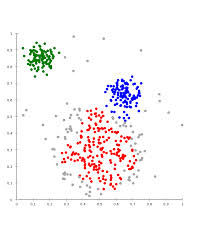
上图中有一些点,横纵坐标是其两个特征值,现在想要把这些点进行标记归类。我们不知道任何一个点的类别,但是我们可以根据它们的分布对其进行归类。毕竟距离近的一些点更有可能是同一类。Kmeans算法原理大概就是这样。
下面概括的讲一下kmeans算法是怎么工作的。
算法接受一个参数K,使得实现输入的n个数据对象被划分为k个聚类,并且有同一聚类中的对象相似度较高,不同聚类中的对象相似度较小。
算法的思想是以空间中的k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法逐次更新聚类中心,直到得到最好的聚类结果。
也就是,先在空间的对象中随机选择K个点作为K个类的初始中心,根据与这K个中心距离的远近将所有的样例点归为这K个类。然后利用均值等方法更新这K个中心,接着再次根据远近归类所有的点。通过这样不断迭代的方式最终就能将所有的点较好的分为K个聚类。这里中心点的更新主要是利用均值。下面通过例子详细的说明。
当迭代达到一定的次数,或者中心点的变化小于给定的阈值就可以停止迭代了。
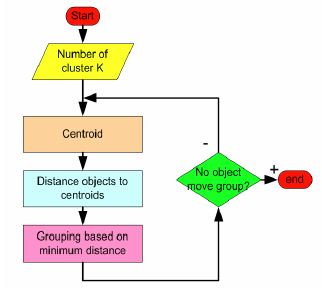
总的流程图如下。
下面举个具体的例子来详细说明。

表格中有4组数据,分别是A,B,C,D四个药的两个特征值X(weight),Y(pH),现在要根据上述的Kmeans算法将其分为两类。
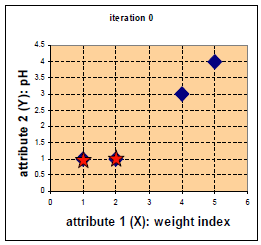
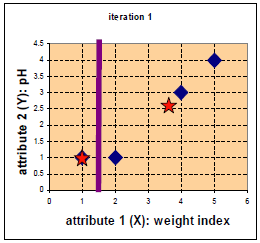
如上图,将4组数据的坐标点用蓝色的点画在上图中,因为要分为两类,所以随机选择两个中心点c1,c2,用红色的五角星表示。这里直接选择A,B两组数据的点作为中心点,所以将其标为五角星。然后计算4个点与这两个中心点的距离。
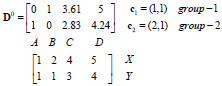
距离用矩阵D表示,为A,B,C,D个点与中心点c1,c2的距离。可以看出,A点归为中心点c1一类。B,C,D点与中心店c2距离更近归为第二类。
现在利用均值的方式更新中心点。
c1类只有一个点A所以不变,c2更变如下:
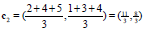
如图:
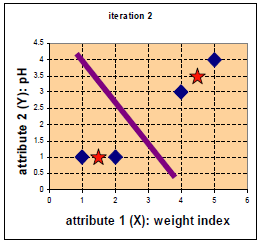
再次同样的方法计算距离,则可将A,B归为c1一类, C,D归为c2一类。
更新中心点过程略过如下图:
此时依然为A,B一类,C,D一类与前次结果相同,故终止迭代。结果如下。

至此Kmeans算法的计算就完成了。
Kmeans算法的优点是速度快,简单,缺点是最终的结果跟中心点的选择相关,容易陷入局部最优,而且需要输入一个K值,有些时候我们可能并不知道要分成多少个类比较好。
