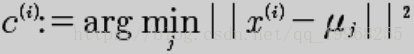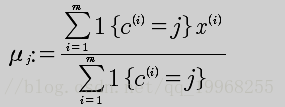object KmeansTest { val k=2 //类个数 val dim=2 //数据集维度 val shold=0.0000000001 //阀值用于判断聚类中心偏移量 val centers=new Array[Vector[Double]](k) //聚类中心点(迭代更新) /** * 数据 * 1.658985, 4.285136 * -3.453687, 3.424321 * 4.838138, -1.151539 * -5.379713, -3.362104 * * @param sc * @return */ def loadDataSet(sc:SparkContext): Array[Vector[Double]] ={ val file = sc.textFile("") val res=file.map(t=>{ val value=t.split(" ").map(x=>{x.toDouble}) var vector = Vector[Double]() for(i <- 0 until dim) vector ++= Vector(value(i)) vector }).collect() res }
/** * * 随机初始化聚类中心 * k个聚类中心 * 初始化中心点如下: 3 Vector(-5.379713, -3.362104) 初始化中心点如下: 4 Vector(0.972564, 2.924086) * */ def initialCenters(points:Array[Vector[Double]]): Unit ={ val pointsNum=points.length val random = new Random() var index=0 var flag=true var temp=0 val array=new ListBuffer[Int] while(index < k){ val temp: Int = random.nextInt(pointsNum) flag=true if(array.contains(temp)){ flag=false }else{ if(flag){ array.append(temp) index+=1 } } }
object KmeansTest2 { def main(args: Array[String]): Unit = { val sparkConf=new SparkConf().setAppName("KmeansTest2").setMaster("local[2]") val sc=new SparkContext(sparkConf)
val data=sc.textFile("")
val parsedData=data.map(s=>Vectors.dense(s.split(" ").map(_.toDouble)))
val numClusters=2 val numIterations=30 val model=KMeans.train(parsedData,numClusters,numIterations)
// 使用误差平方之和来评估数据模型 val cost = model.computeCost(parsedData) println("Within Set Sum of Squared Errors = " + cost)
// 使用模型测试单点数据 /*println("Vectors 7.3 1.5 10.9 is belong to cluster:" + model.predict(Vectors.dense("1.5 10.9".split(" ") .map(_.toDouble)))) println("Vectors 4.2 11.2 2.7 is belong to cluster:" + model.predict(Vectors.dense("11.2 2.7".split(" ") .map(_.toDouble)))) println("Vectors 18.0 4.5 3.8 is belong to cluster:" + model.predict(Vectors.dense("14.5 73.8".split(" ") .map(_.toDouble))))*/
// 返回数据集和结果 val result = data.map { line => val linevectore = Vectors.dense(line.split(" ").map(_.toDouble)) val prediction = model.predict(linevectore) line + " " + prediction }.collect.foreach(println)