Kmeans算法:
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上的收敛速度较慢。
适用数据类型:数值型数据
算法原理:
k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
算法流程:
收集数据:需要聚类的数据集。
准备数据:需要数值新数据来计算距离,也可以将标称型数据映射为二值型数据再用于距离计算。
分析数据:散点图,可视化图。
训练算法:无监督算法无此过程。
测试算法:使用Kmeans算法进行聚类,观测结果。
使用算法:可适用于任何聚类应用场景。
首先我们先给出一个演示算法的数据集,为了能直观的观测数据,我们使用散点图进行显示
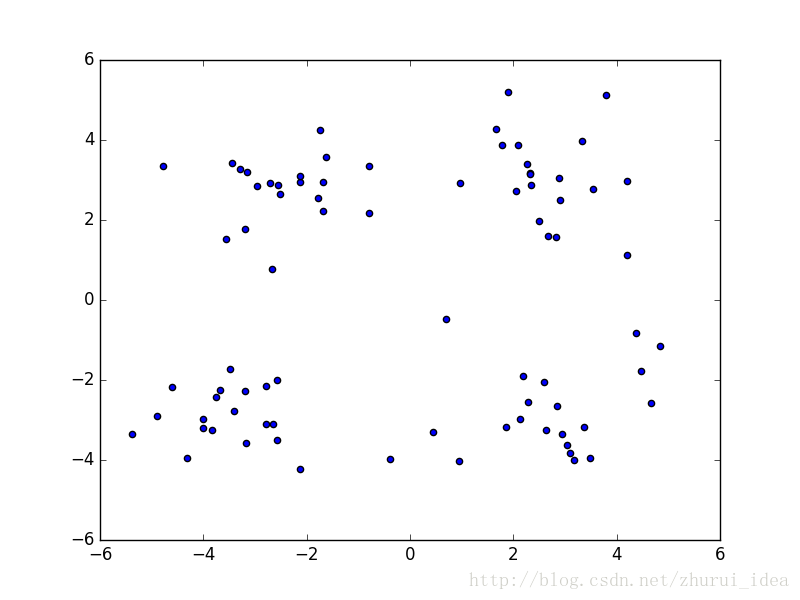
PS:感觉未经过训练的人类也能将这个数据集分成四类。。是不是有点太明显了。。
然后我们来使用我们的Kmean算法
首先我们要创建一个计算的程序
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #计算两点间距离def randCent(dataSet, k):
n = shape(dataSet)[1] #一条数据的维度
centroids = mat(zeros((k,n))) #初始化质心矩阵
for j in range(n): #在数据区间范围内随机初始化质心
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
下面就可以编写Kmeans程序了
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent): #计算距离和创建质心都以函数引用传入
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2))) #数据分类分析矩阵
centroids = createCent(dataSet, k) #保存数据聚类的结果
clusterChanged = True #通过while循环更新质心,当数据分类不在变动就退出循环
while clusterChanged:
clusterChanged = False
for i in range(m): #数据开始进行归类
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j #数据归类
if clusterAssment[i,0] != minIndex: clusterChanged = True #判断数据分类是否不在变动
clusterAssment[i,:] = minIndex,minDist**2
print centroids
for cent in range(k): #根据新的数据变动更新质心
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
下面我们就可以使用Kmean来对我们的数据进行分类啦:
# -*- coding: utf-8 -*-
import kMeans as km
from numpy import *
import matplotlib.pyplot as plt
datMat = mat(km.loadDataSet('DataSet.txt')) #导入数据
myCentroids , clustAssing = km.kMeans(datMat,4) #进行kmeans计算
plt.scatter(myCentroids[:, 0], myCentroids[:, 1], s=300, marker='o', color='r') #显示质心
plt.scatter(datMat[:,0],datMat[:,1]) #显示数据点
plt.show()
结果如下图,为了方便大家理解Kmeans的计算过程,我标记了三次质心迭代的过程,并使用箭头指示了质心移动的方向。

是不是很有趣,其实Kmeans还能做更有趣的事情呢,例如,图像内容分割。。。
先让大家看看我们使用的两张原图:


-*- coding: utf-8 -*-
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
#将图标转行成一个三通道矩阵,并进行归一化
def convImage(file_path):
f = open(file_path, 'rb')
data = []
img = image.open(f)
m, n = img.size
for i in range(m):
for j in range(n):
x, y, z = img.getpixel((i,j))
data.append([x/256.0, y/256.0, z/256.0])
f.close()
return np.mat(data), m, n
#处理图片
imageData, row, col = convImage('rawImage.png')
k = 5 #聚类个数
result = KMeans(clusters=k).fit_predict(imageData)
result = result.reshape([row, col])
#重新绘制结果图片
resultImage = image.new("L",(row, col))
for i in range(row):
for j in range(col):
resultImage.putpixel((i, j), int(256/(result[i][j]+1)))
#保存图片
resultImage.save('resultImage.png')
看出什么来了吗?再看看第二张,我分别领k=2到12。。。

看出来了么,其实聚类的k的数量越接近原图色彩的种类和原图越像,不过。。好像没什么卵用。。没有原图好看。。。(作为一个顶级帅哥,我是外貌协会啦!!)