目录
介绍
K-最近邻(KNN)是一种简单的机器学习算法,其原理是计算测试对象和训练集之间的距离。然后,通过距离选择训练集中的对象以添加到K-NN集,直到K-NN集包括预定义数量的最近邻居,其可以表示为:

其中 ![]() 是KNN集,
是KNN集,![]() 由下式给出:
由下式给出:
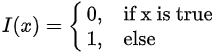
KNN模型
KNN模型由距离计算,选择K和分类组成。
距离计算
距离用于测量特征空间中两个对象之间的相似性。有许多方法可以计算两个物体之间的距离,例如欧几里德距离,余弦距离,编辑距离,曼哈顿距离等。最简单的方法是欧几里德距离,计算公式如下:
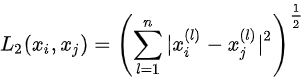
其中n特征维度。
由于特征值的不同尺度,较大的值对距离的影响较大。因此,所有特征都需要标准化。具体而言,有两种归一化方法。一个是最小——最大标准化,由下式给出:

def Normalization(self, data):
# get the max and min value of each column
minValue = data.min(axis=0)
maxValue = data.max(axis=0)
diff = maxValue - minValue
# normalization
mindata = np.tile(minValue, (data.shape[0], 1))
normdata = (data - mindata)/np.tile(diff, (data.shape[0], 1))
return normdata另一个是z -score标准化,由下式给出:
![]()
其中![]() 是
是![]() 的平均值而
的平均值而![]() 是
是![]() 的标准差。
的标准差。
def Standardization(self, data):
# get the mean and the variance of each column
meanValue = data.mean(axis=0)
varValue = data.std(axis=0)
standarddata = (data - np.tile(meanValue,
(data.shape[0], 1)))/np.tile(varValue, (data.shape[0], 1))
return standarddata标准化后,欧几里德距离的代码如下所示:
train_num = train_data.shape[0]
# calculate the distances
distances = np.tile(input, (train_num, 1)) - train_data
distances = distances**2
distances = distances.sum(axis=1)
distances = distances**0.5选择K
如果我们选择一个小K,则用一个小邻居学习该模型,这将导致小的“近似误差”和大的“估计误差”。总之,小K会使模型变得复杂并倾向于过度拟合。相反,如果我们选择一个大的K,则用一个大邻居学习该模型,这将导致大的“近似误差”和小的“估计误差”。总之,大K将使模型简单并且倾向于大量计算。
分类
确定K后,我们可以利用投票进行分类,这意味着少数人服从大多数人,其代码如下所示:
disIndex = distances.argsort()
labelCount = {}
for i in range(k):
label = train_label[disIndex[i]]
labelCount[label] = labelCount.get(label, 0) + 1
prediction = sorted(labelCount.items(), key=op.itemgetter(1), reverse=True)
label = prediction[0][0]在上面的代码中,我们首先使用argsorts()获取有序索引,然后计算前K个样本中的每种标签,最后labelCount进行排序以获得具有最多投票的标签,这是对测试对象的预测。整个预测功能如下所示:
def calcuateDistance(self, input_sample, train_data, train_label, k):
train_num = train_data.shape[0]
# calculate the distances
distances = np.tile(input, (train_num, 1)) - train_data
distances = distances**2
distances = distances.sum(axis=1)
distances = distances**0.5
# get the labels of the first k distances
disIndex = distances.argsort()
labelCount = {}
for i in range(k):
label = train_label[disIndex[i]]
labelCount[label] = labelCount.get(label, 0) + 1
prediction = sorted(labelCount.items(), key=op.itemgetter(1), reverse=True)
label = prediction[0][0]
return label结论与分析
KNN在本文中通过线性遍历实现。然而,存在更有效的KNN方法,如kd树。此外,应用交叉验证来获得更合适的K是有效的。最后,让我们将我们的KNN与Sklearn中的KNN进行比较,检测性能如下所示。

从图中可以看出,本文中的KNN在准确性方面优于sklearn knn。运行时几乎相同。
可以在MachineLearning中找到本文中的相关代码和数据集。
原文地址:https://www.codeproject.com/Articles/4044571/Step-by-Step-Guide-To-Implement-Machine-Learning-I