原理
kNN(k近邻算法)的基本思想就是选择距离待分类点最近的K个点,统计这K个点中出现的分类的概率, 出现概率最高的分类即为待分类点的分类
源码
from numpy import *
import operator
def createDataSet(): # create data set
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group,labels
def classify0(inX, dataSet, labels, k): #k-NN classify
"""
:param inX: 用于分类的输入向量
:param dataSet: 输入的训练样本集
:param labels: 标签向量
:param k: 用于选择最近邻居的数目
:return:
"""
# 用欧氏距离计算当前点与样本集中所有点的距离
dataSetSize = dataSet.shape[0] #获取数组维度的长度 (列或行数)
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # tile是重复次数,如tile([0,0],(2,3)),是在重复行2次,列3次,结果是[[0 0 0 0 0 0] [0 0 0 0 0 0]]
sqDiffMat = diffMat ** 2 # 所有元素平方
sqDistances = sqDiffMat.sum(axis = 1) # axis = none 表示所有元素相加, axis = 0表示每一列所有元素相加, axis = 1表示每一行所有元素相加
distances = sqDistances**0.5 # 开方得到待求点到数据集中所有点的距离
sortedDistIndicies = distances.argsort() # 返回的是从小到大排序后的原数据的索引, 如原数据为[1, 5, 3, 0], 调用argsort()方法返回的是[3, 0, 2, 1]
classCount = {}
# 选择距离最小的k个点
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 得到前k个标签
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 统计label出现的次数,默认值为0
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 根据标签出现次数从高到低排序
return sortedClassCount[0][0]
if __name__ == "__main__":
group, labels = createDataSet()
result = classify0([0, 0], group, labels, 3)
print(result)加权kNN
有一个问题就是该算法给所有的近邻分配相等的权重,这个还可以这样改进,就是给更近的邻居分配更大的权重(你离我更近,那我就认为你跟我更相似,就给你分配更大的权重),而较远的邻居的权重相应地减少,取其加权平均。需要一个能把距离转换为权重的函数,gaussian函数是一个比较普遍的选择,下图可以看到gaussian函数的衰减趋势。
高斯函数
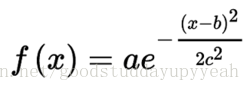
高斯函数的图形在形状上像一个倒悬着的钟。参数a指高斯曲线的峰值,b为其对应的横坐标,c即标准差(有时也叫高斯RMS宽值),它控制着“钟”的宽度。
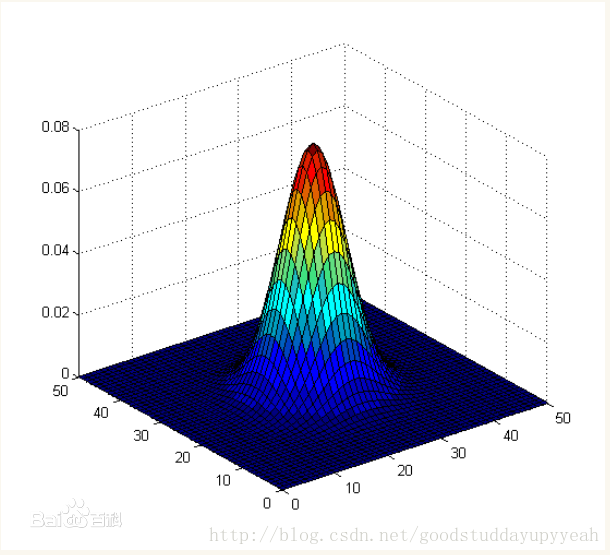
交叉验证
使用交叉验证进行算法模型评估以及k值的选取