一、概述
kNN算法的核心思想:如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
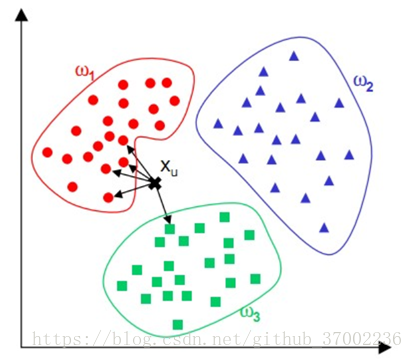
二、KNN算法
1.算法流程:
1)计算待分类点与已知类别的点之间的距离
2)按照距离递增次序排序
3)选取与待分类点距离最小的k个点
4)确定前k个点所在类别的出现次数
5)返回前k个点出现次数最高的类别作为待分类点的预测分类

2.算法模型关键点
1)距离向量:欧式距离、曼哈顿距离等
2)K值选择:K越小,分类边界曲线越曲折,偏差越小,方差越大;K越大,分类边界曲线越平坦,偏差越大,方差越小
3)分类决策规则:投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
3.算法实现
线性扫描在训练集非常大时,计算非常耗时。一般采用Kd树实现:
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
kd树生成规则:以中位数划分

4.KNN优缺点
优点:
1)简单,易于理解,易于实现,无需估计参数,无需训练;
2)适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型);
3)特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
缺点:
1)当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数,少数类容易分错。
2)需要存储全部训练样本。
3)计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
5.改进策略
kNN算法因其提出时间较早,随着其他技术的不断更新和完善,kNN算法的诸多不足之处也逐渐显露,因此许多kNN算法的改进算法也应运而生。
针对以上算法的不足,算法的改进方向主要分成了分类效率和分类效果两方面。
分类效率:事先对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
分类效果:采用权值的方法(和该样本距离小的邻居权值大)来改进,Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
三、KNN延申
1.快速搜索近邻
其基本思想是将样本集按邻近关系分解成组,给出每组的质心所在,以及组内样本至该质心的最大距离。这些组又可形成层次结构,即组又分子组,因而待识别样本可将搜索近邻的范围从某一大组,逐渐深入到其中的子组,直至树的叶结点所代表的组,确定其相邻关系。
这种方法着眼于只解决减少计算量,但没有达到减少存储量的要求。
2.剪辑近邻法
剪辑近邻法:其基本思想是,利用现有样本集对其自身进行剪辑,将不同类别交界处的样本以适当方式筛选,可以实现既减少样本数又提高正确识别率的双重目的。
剪辑的过程是:将样本集KN分成两个互相独立的子集:test集KT和reference集KR。首先对KT中每一个Xi在KR中找到其最近邻的样本Yi(Xi) 。如果Yi与Xi不属于同一类别,则将Xi从KT中删除,最后得到一个剪辑的样本集KTE(剪辑样本集),以取代原样本集,对待识别样本进行分类。
3.压缩近邻法
压缩近邻法:利用现有样本集,逐渐生成一个新的样本集,使该样本集在保留最少量样本的条件下,仍能对原有样本的全部用最近邻法正确分类,那末该样本集也就能对待识别样本进行分类,并保持正常识别率。
定义两个存储器,一个用来存放即将生成的样本集,称为Store;另一存储器则存放原样本集,称为Grabbag。其算法是:
1)初始化。Store是空集,原样本集存入Grabbag;从Grabbag中任意选择一样本放入Store中作为新样本集的第一个样本。
2)样本集生成。在Grabbag中取出第i个样本用Store中的当前样本集按最近邻法分类。若分类错误,则将该样本从Grabbag转入Store中,若分类正确,则将该样本放回Grabbag中。
3)结束过程。若Grabbag中所有样本在执行第二步时没有发生转入Store的现象,或Grabbag已成空集,则算法终止,否则转入第二步。