今晚去蹭了超强师姐的讲座,以下是今晚的笔记。
目前存在的目标检测可以分为以下几类:
- One-short, few-short, weakly supervised object detection:这类型的目标检测任务定义不明确;
- 显著性物体检测:数据集定义不明确,对于不同人来说,显著性的定义不一样;
- 关键点检测:要把关键点回归到几个pixel以内,要求严格;
- 通用目标检测,这是今晚的主题。
检测目前主要的问题有:小物体、正负样本比失衡、形变、定位准确度、关系和网络结构。
小物体检测
遇到的问题
小物体检测的问题主要是指在深层网络的高级语义信息中,常常会丢失掉这些小物体的信息,因此存在检测精度低的问题。

目前的解决方法
目前的检测工作基本都是在ImageNet上pretrain之后,作为COCO检测网络backbone的初始化;但ImageNe和COCO这两个数据集中存在一些gap,如图片大小不一样、object的size也不一样。
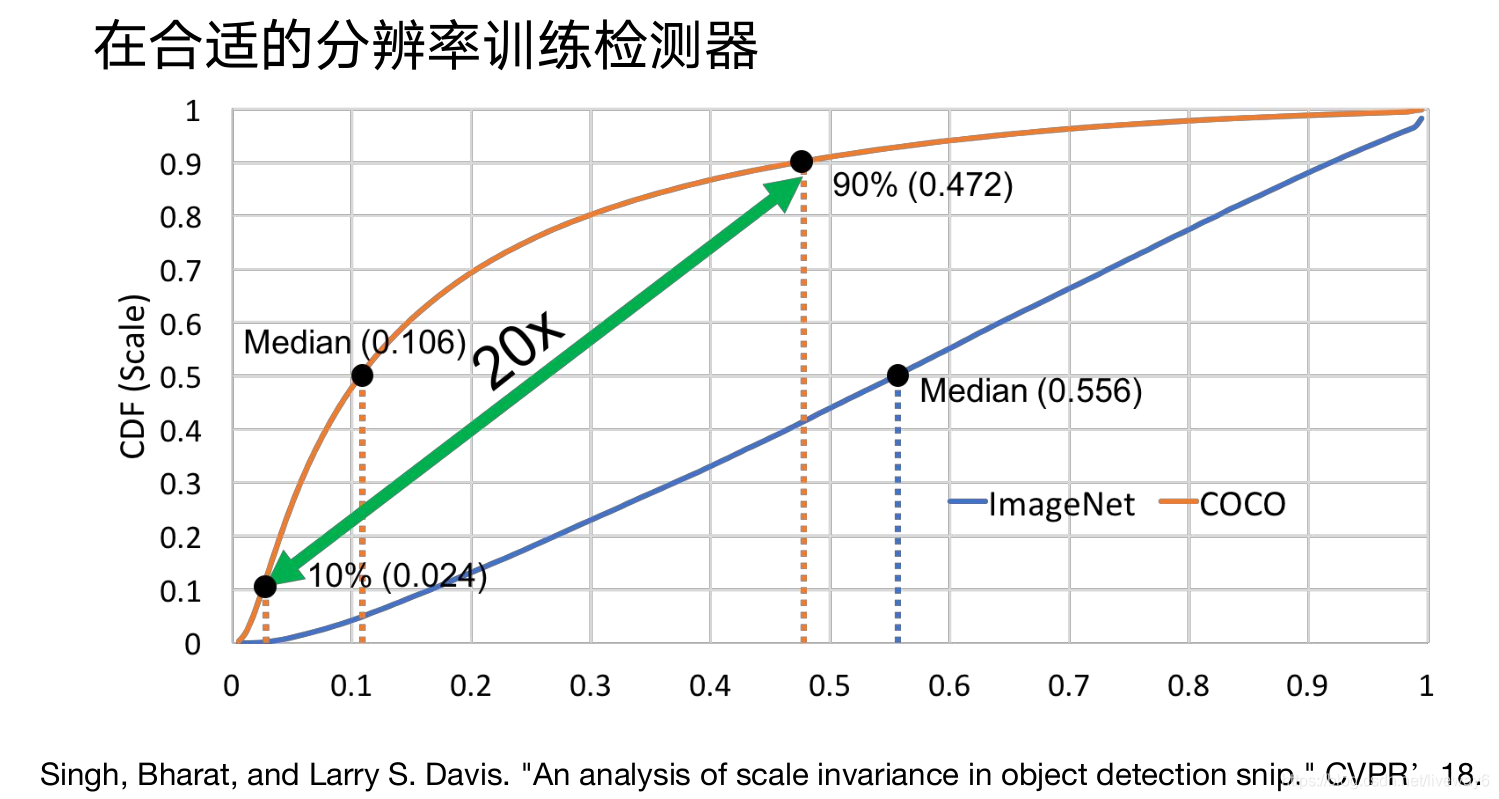
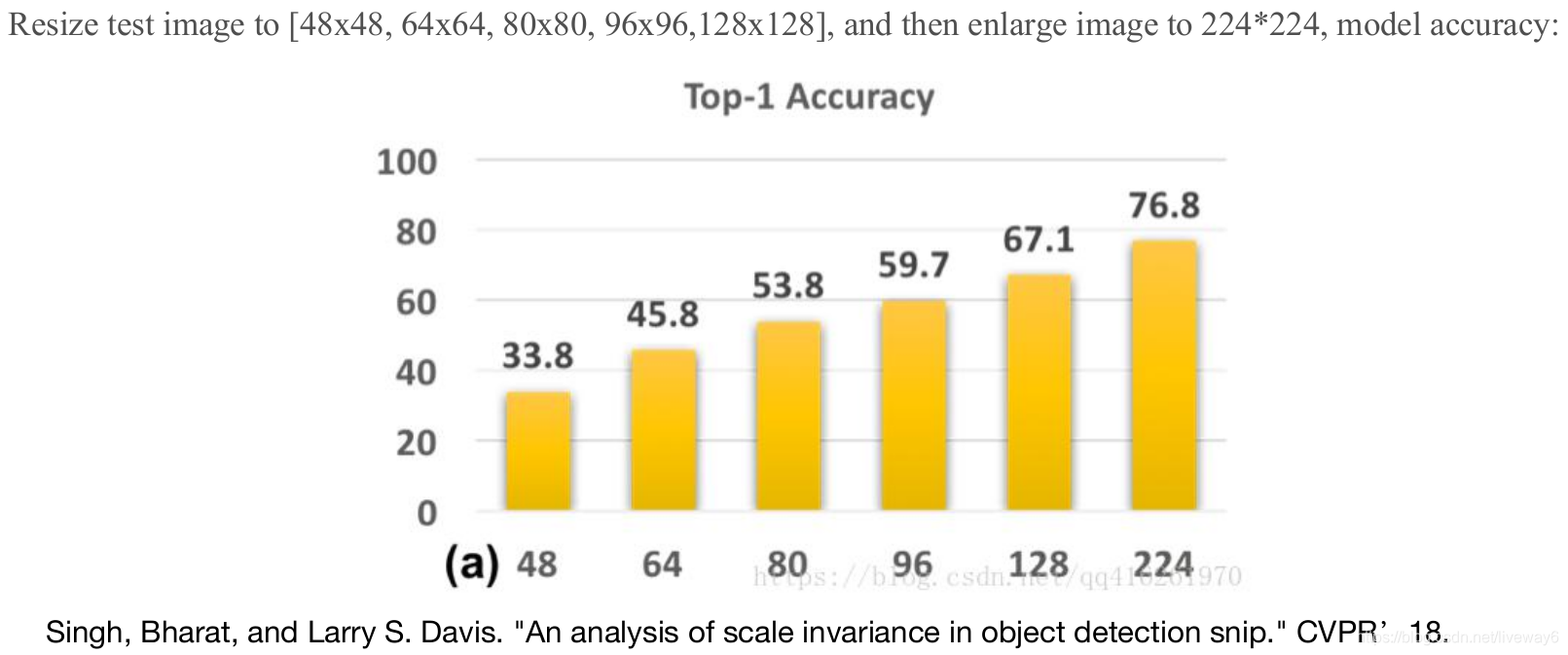
因此CVPR 18这篇SNIP就对数据做了一个实验,将这五个size的图片线性插值到224*224(ImageNet图片的size),可以看到结果都提升了,说明了分辨率对检测结果的影响。
于是作者提出了SNIP,主要idea是将一张图片resize到不同的大小,训练3个不同的检测器,分别为:对于大图保留小目标的检测、对于原图保留中等目标、对于小图保留大目标的检测结果,之后再把他们加起来。
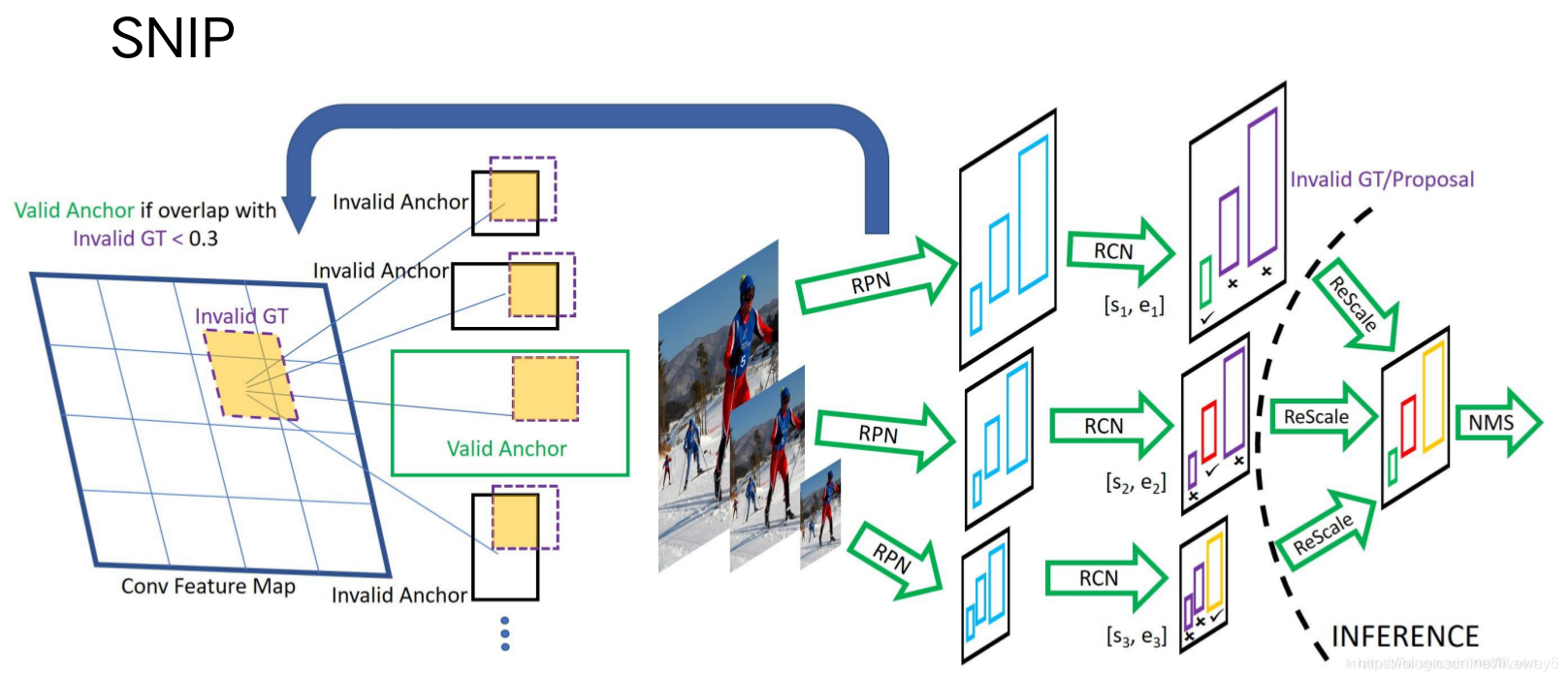
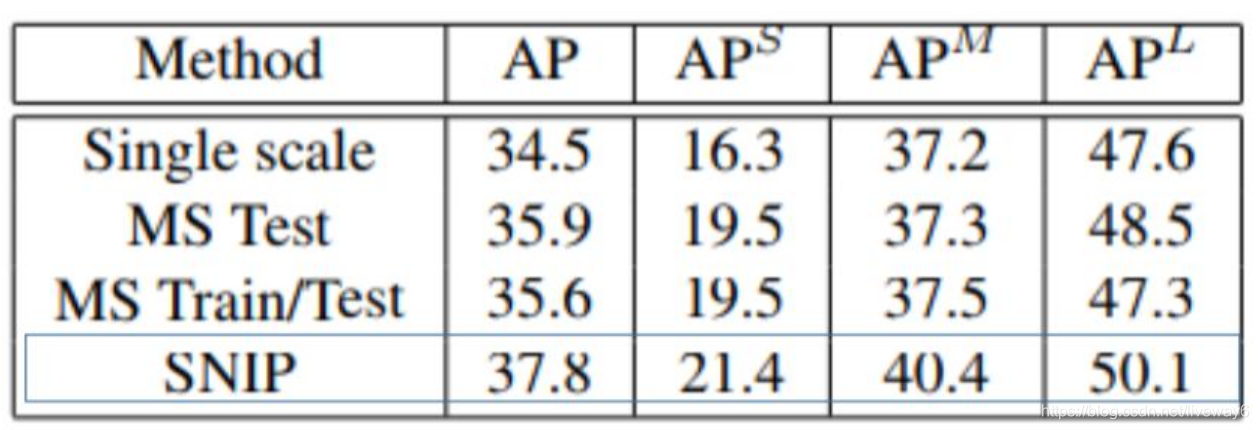
这个方法有一定的提升,但是因为需要训练3个检测器也会加大模型复杂度。因此有人在此基础上做了优化。SNIPER将原图裁剪为不同的正负样板分片,resize到一个scale之后再扔到网络中去。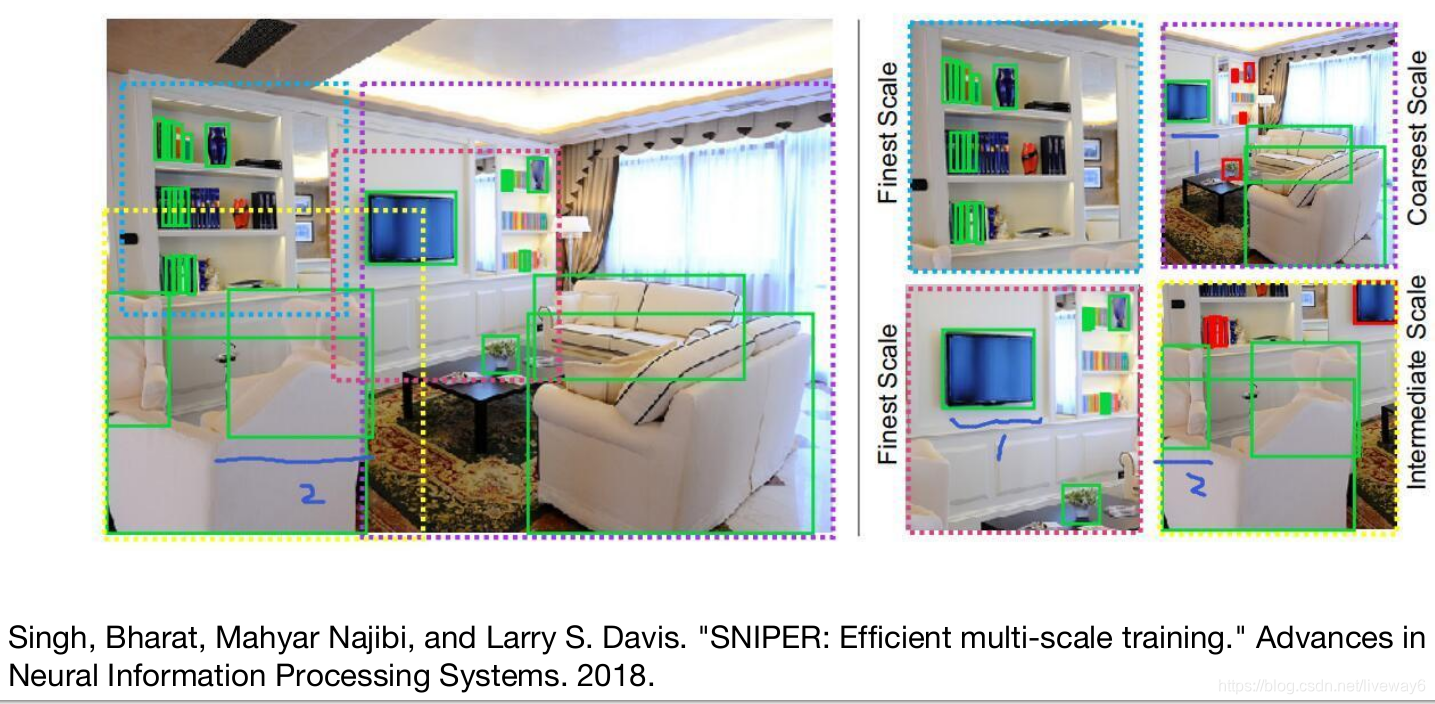
这样子,网络就只要训1个检测器了。但是在切分负样本那里比较复杂,follow他继续做的人也不多。不过它的结果还是很好的。

正负样本失衡问题
在传统的anchor-base的检测网络中,是在conv之后得到的feature map上逐个pixel的生成9个anchor,这样就会导致正负样本严重失衡。

解决办法
focal loss
kaiming提出了focal loss来解决这个问题。传统的交叉熵对所有样本的权值是一样的,但由于样本不均衡会导致趋向于易学习的样本而跳过难学习的样本。focal loss主要的idea是使越容易训练的样本权值越小,使loss主要来源于更难区分的样本。

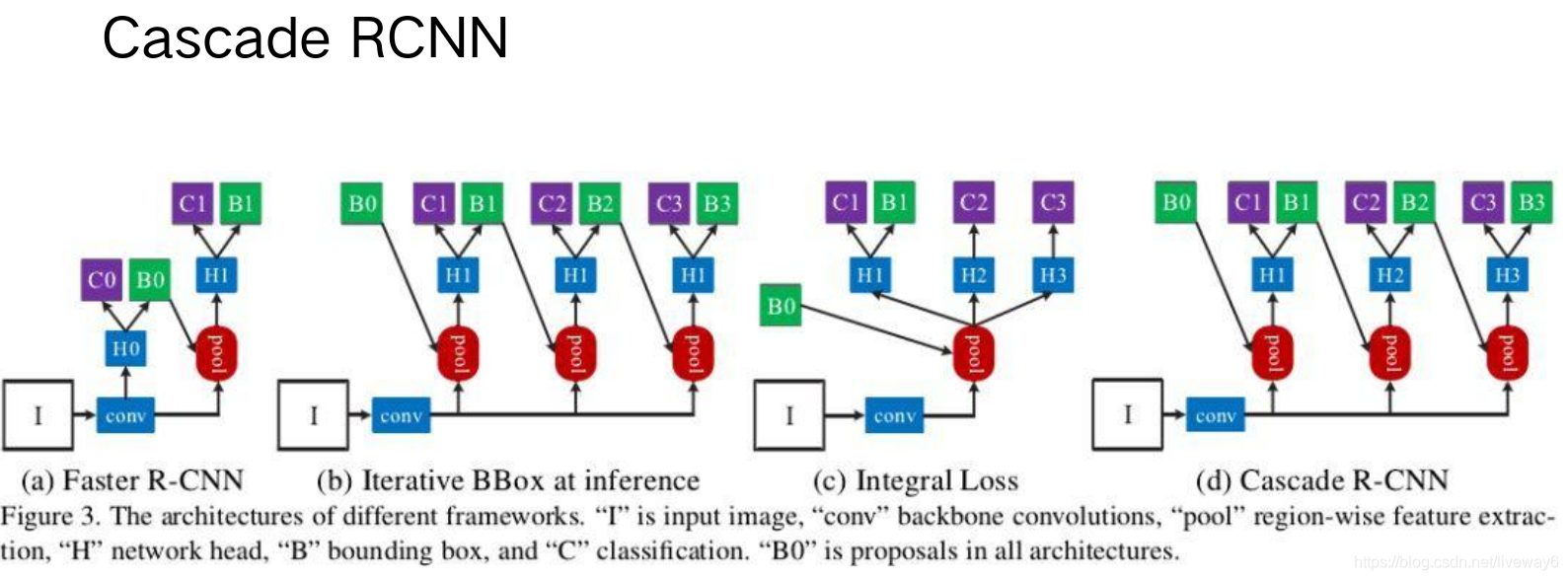
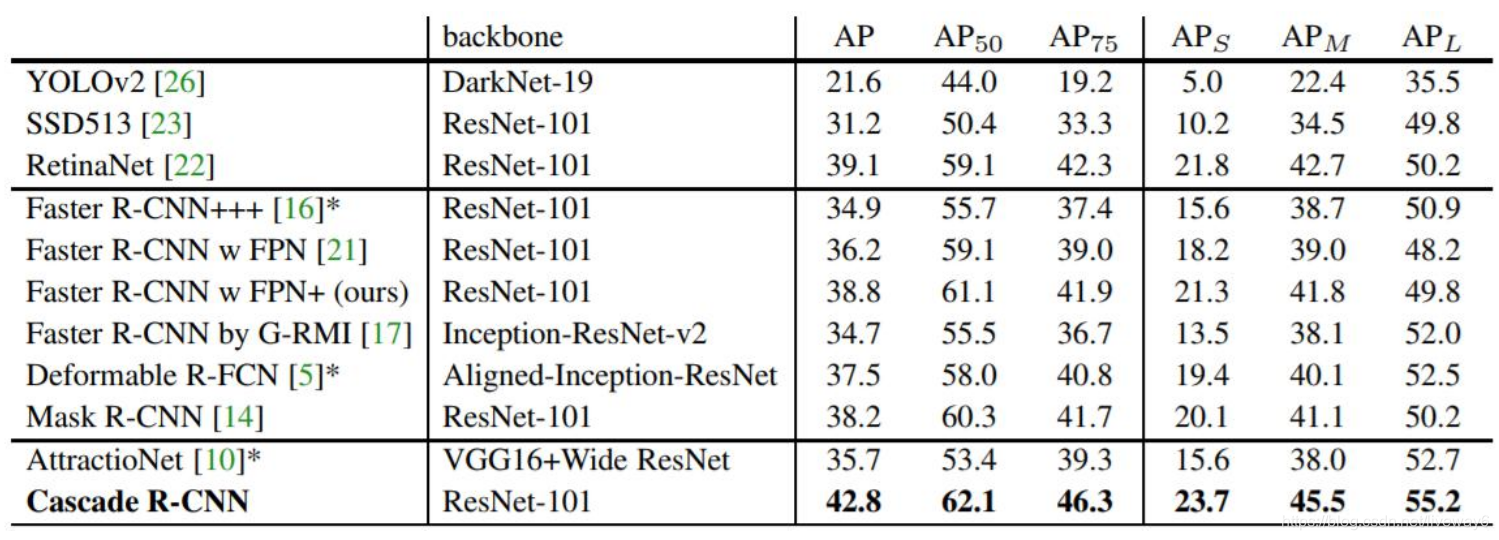
Cascade RCNN
在传统的NMS中,我们一般默认IoU阈值为0.5,但在浅层网络中目标的IoU会小于0.5,而在深层网络中目标的IoU会大于0.5.
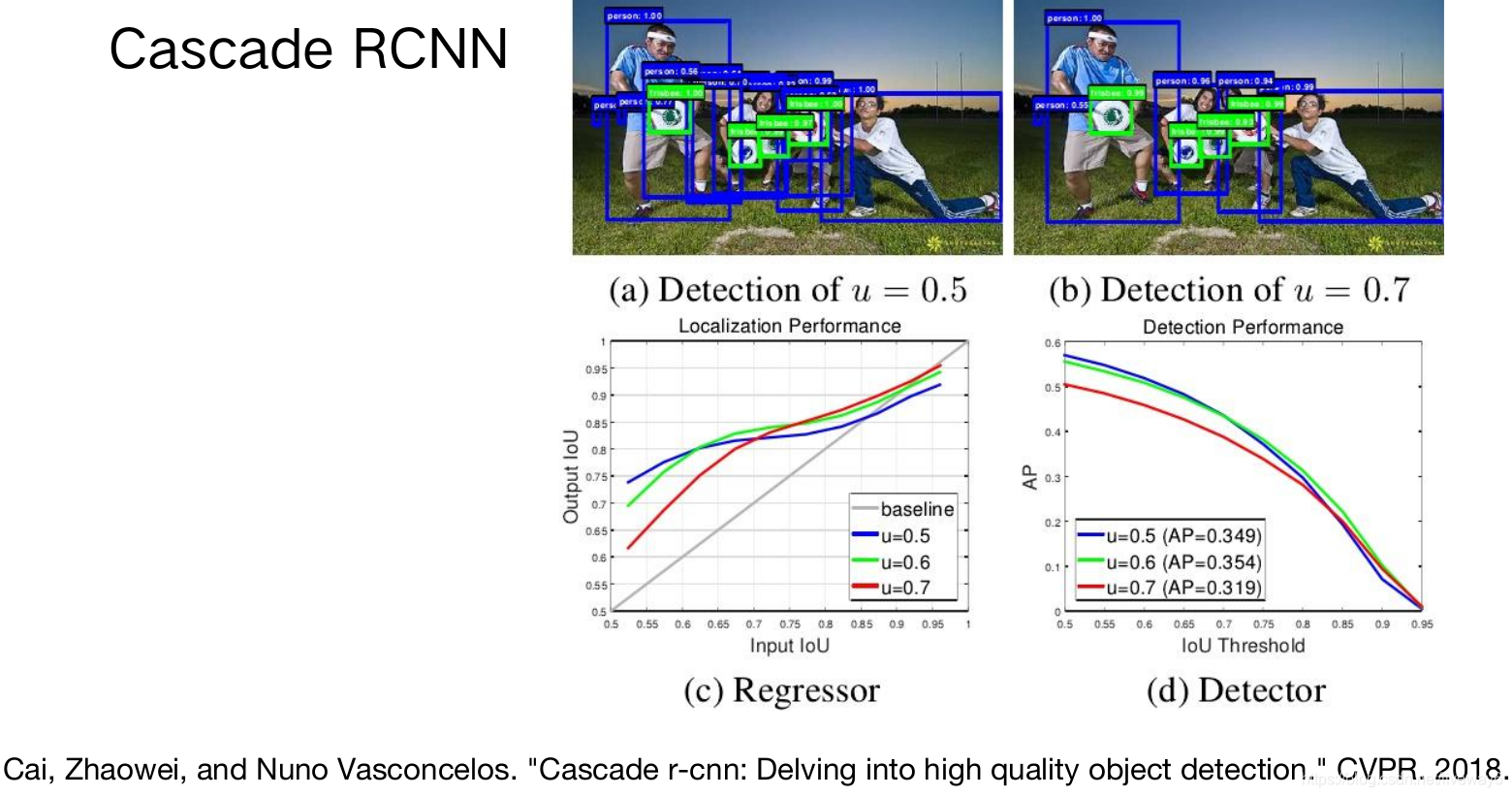
因此作者设计了multi-stage的检测网络,在每个stage中设置的NMS阈值不一样。
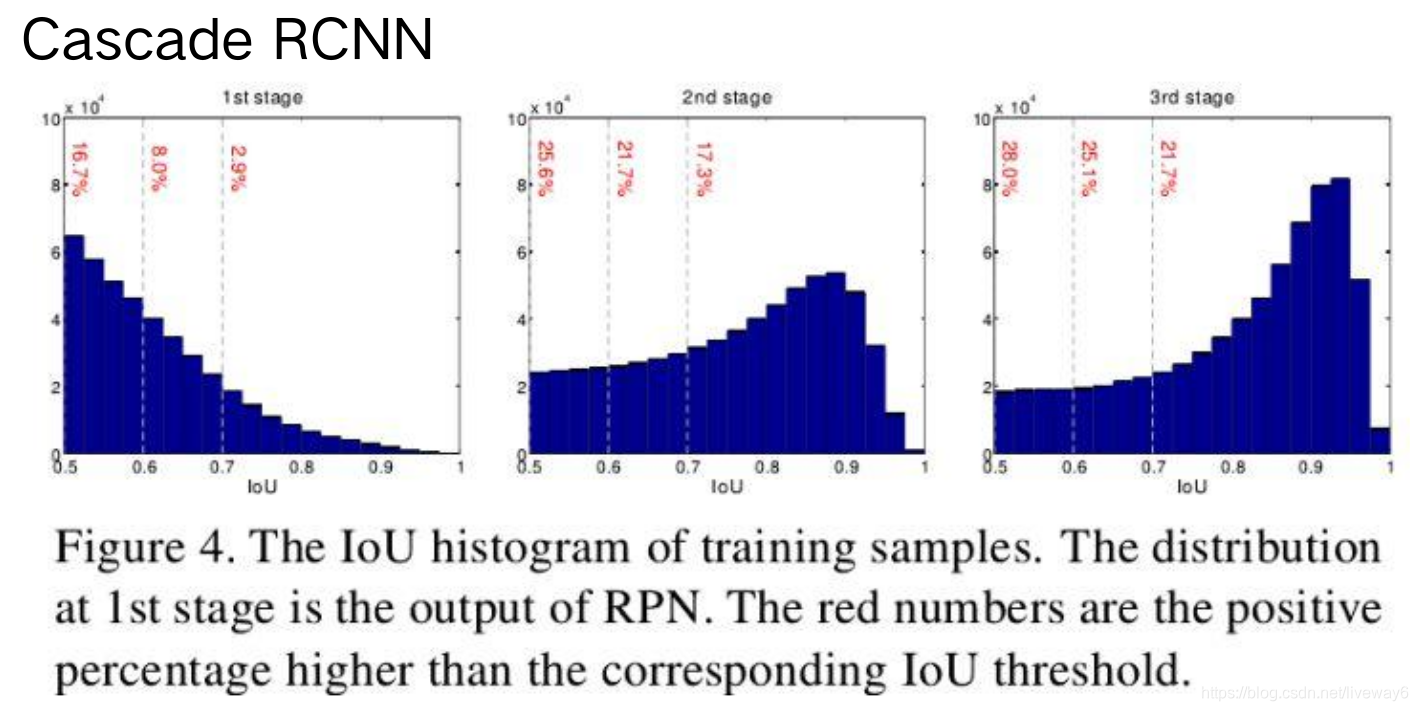
作者在实验中发现,在stage1的时候,object的IoU会存在在比较低的范围内;在stage2的时候,object的IoU会在中等偏高,在stage3的时候,object的IoU就很高了。说明了需要在stage1的时候设置低阈值,在stage3的时候设置高阈值。
最后的结果还不错吧

形变
一般来说,目标检测的kernel都是一个矩形,但是物体并不一定都是矩形的,所以jiefeng就提出了deformable conv。

定位准确度
在NMS阶段,一般是根据分类精度来去掉一些bbox的,但是分类精度不一定等于定位精度,如下图,因此定位更精确的框有可能会被抑制。

然后有人在传统检测网络中多加了一个head来预测proposal的IoU值,来确保网络保留定位更加精确的bbox。
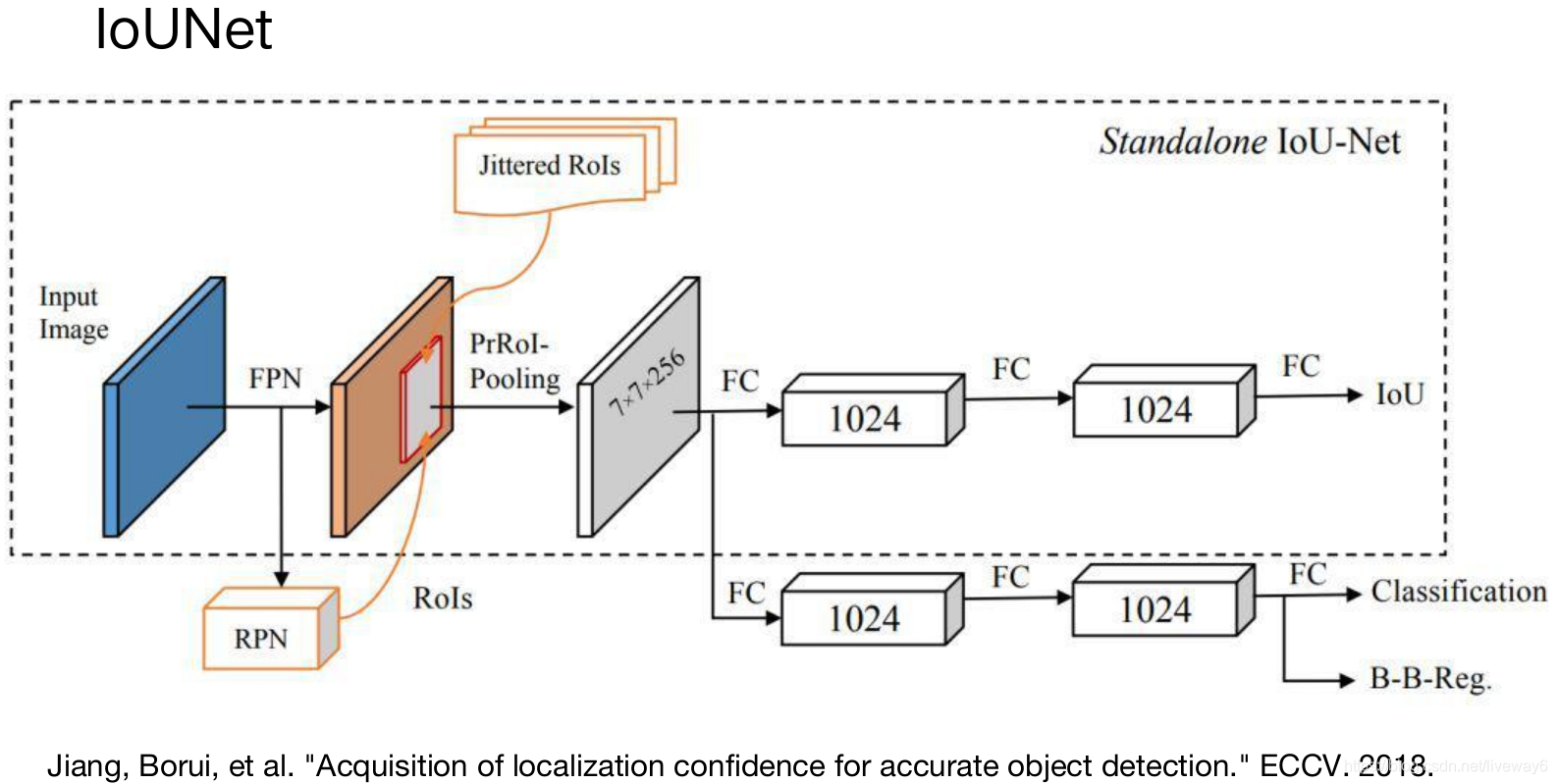
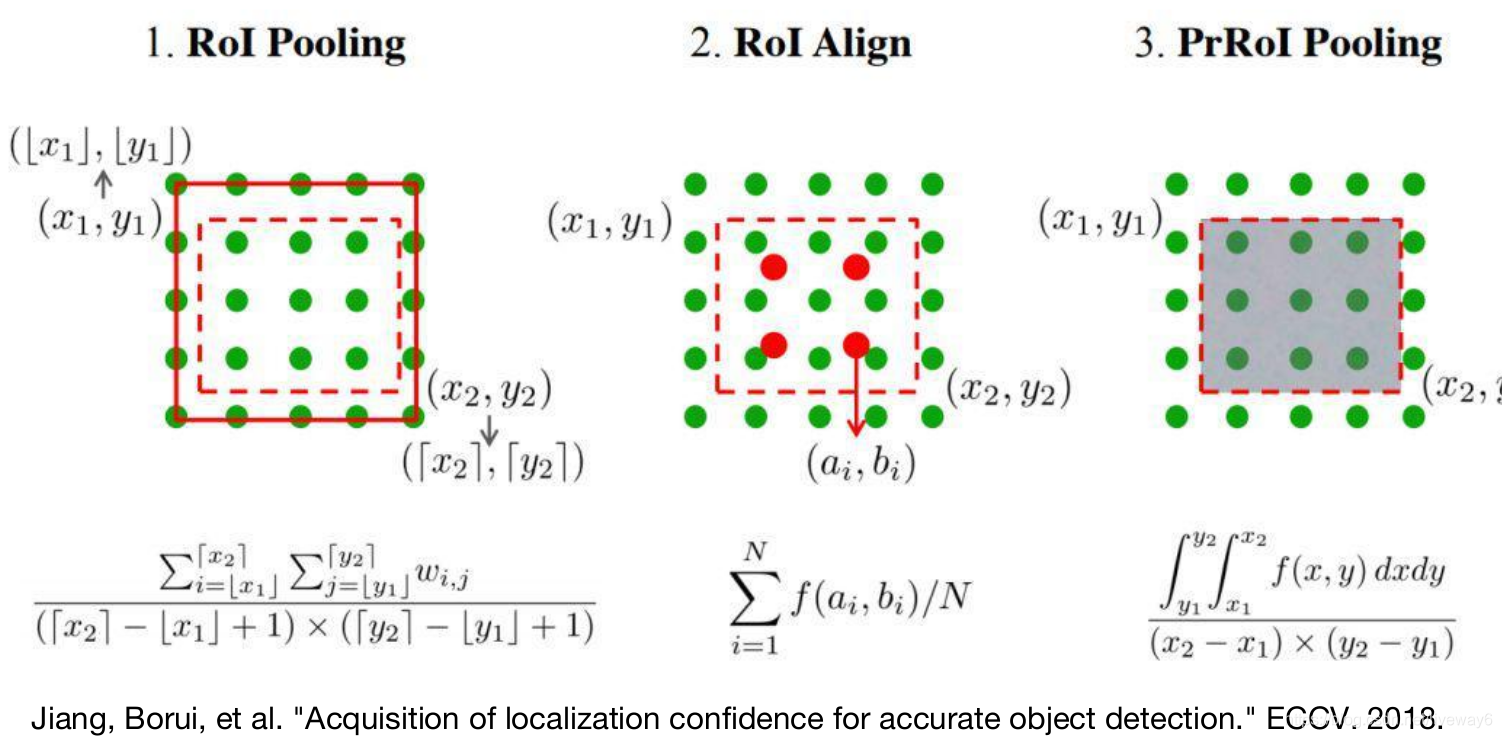
然后他来提出了一种pooling,对于ROI pooling和ROI align来说都不能对框的坐标点进行梯度回传,因而不能改变它的位置。作者提出的PrROI pooling可以用来回归bbox的坐标点,使得定位更加精准。
结果对比

关系这里主要介绍了师姐的工作,等我看我论文再来新写一篇吧,内容很多。
(其实是我想回宿舍了)