在目标检测的实际应用中,常常会出现需要泛化的目标检测系统的情况。如城市安防中,需要目标检测系统能够检测足够多类别的目标,才能达到更好的安防效果。 但目前常用的目标检测数据集中包含的类别数量有限,使用单个数据集训练的目标检测模型已经不能满足需求,如何集成训练多个数据集成为了一大热门研究方向。
一、集成多个数据集存在的问题
如果简单的将多个数据集拼接起来进行训练,往往不会获得性能上的提升。主要原因有以下三点:
NO.1
各数据集的标签空间不统一
每个数据集都规定了各自的标签空间,并且不同标签空间之间有重叠。但名字相同的标签在不同数据集中的语义可能不同,如COCO中的mouse代表鼠标,OpenImages中的mouse代表老鼠;名字不同的标签在不同数据集中的语义可能相同,如VOC中的aeroplane和COCO中的airplane均代表飞机。
如果单纯通过标签的名称来对齐会导致标签语义上的歧义。
NO.2
各数据集的标注不一致
由于各数据集的标签空间不统一,导致各数据集的前景背景定义不同。如图1中所示,A数据集中包含person、car类别,但不包含face类别。B数据集中包含person、face类别,但不包含car类别。那么在各自的标注中,A数据集会将car作为前景标注出来,但会将face作为背景忽略;而B数据集会将face作为前景标注出来,但会将car作为背景忽略[2]。这样就导致了不同数据集之间的前景背景定义存在歧义。
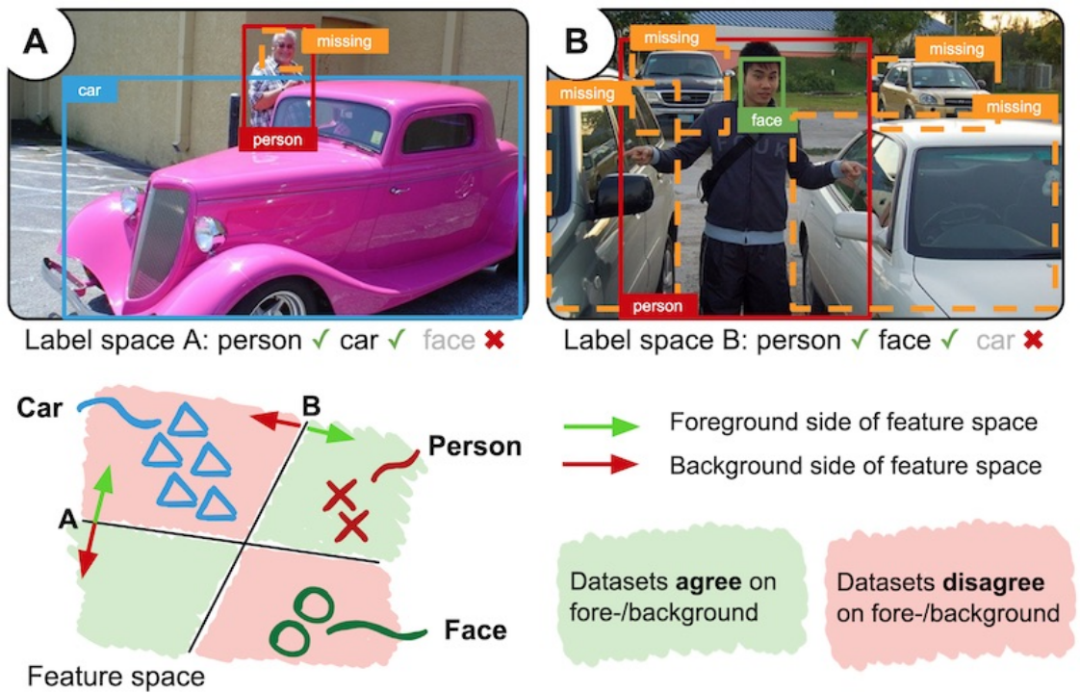
图1 标注不一致问题
NO.3
各数据集的领域差异
由于各数据集的应用场景,图片获取方式的不同导致数据集之间可能存在巨大的领域差异。如图2左为自动驾驶场景,图2右为室内场景,可以明显看出左右两张图像的风格不同,这会导致模型提取的特征分布不同。

图2 领域差异问题
二、SimpleMulti-dataset Detection论文解读
由于篇幅有限,本文只介绍一种通过“构建统一标签空间”来集成训练多个数据集的论文《Simple Multi-dataset Detection》[1]。这里会概述一下论文中的方法,分析其实验结果,并简单介绍代码使用方法,以帮助读者更好地了解集成训练。
NO.1
方法
UT-Austin提出了一种在多个大型数据集(COCO,Objects365,OpenImages等)上训练通用目标检测器的简单方法,并基于此方法夺得了ECCV2020鲁棒视觉挑战赛中的目标检测和实例分割两个赛道的第一名。

图3 不同类型的目标检测模型
传统的目标检测模型如图3(a)所示,单个数据集对应单个模型,这样用COCO数据集训练的模型并不能用于检测Objects365数据集的目标。所以作者采用图3(b)的方式训练一个multi-head(多检测头)模型,共享模型的backbone,对于不同的数据集使用不同的检测头,每个数据集的loss单独计算。这样训练出来的模型可以识别多个数据集中的目标,不过当前的模型并没有做到统一标签空间,如COCO、Objects365、OpenImages均检测出Car类别的目标,但会输出三个重复的检测框。
但通过这种方式,我们获得了统一标签空间的基础,在同一张输入图片上可以获得各数据集检测头的检测结果,这样就可以通过对比检测结果来对齐不同数据集的标签。
作者提出了一种新颖的data-diven方式来学习统一的标签空间:根据不同检测头在各数据集验证集合上的检测结果来学习标签空间。作者将标签空间的融合看作学习一个原始空间 到统一空间
的映射关系矩阵:
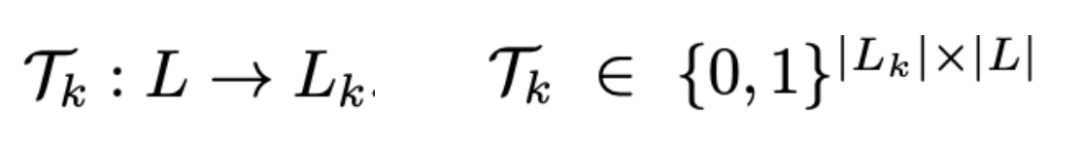
而具体的优化目标为以下公式:

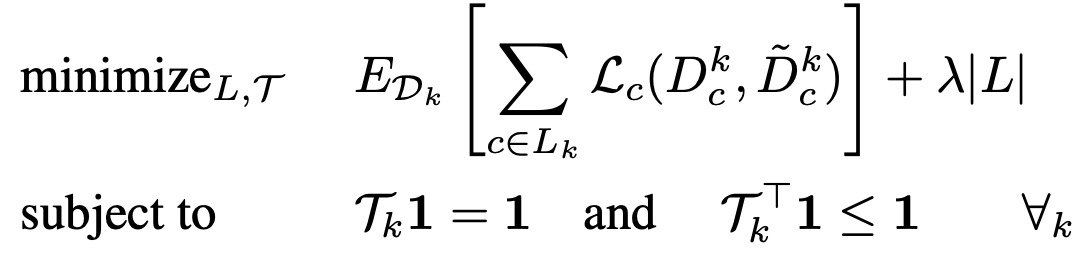
上述公式中出现的变量含义如下所示:
● :数据集k对应的映射矩阵
● :在统一标签空间下各预测框的类别概率分布
● :在数据集k的标签空间下各预测框的类别概率分布
● :优化损失函数
其中由于无法直接对映射矩阵进行优化(无法得知初始映射关系),作者巧妙的将问题转化为穷举在各数据集上每个类别可能的映射关系的方式来寻找最佳的映射矩阵,详细可见论文中的推导[1]。
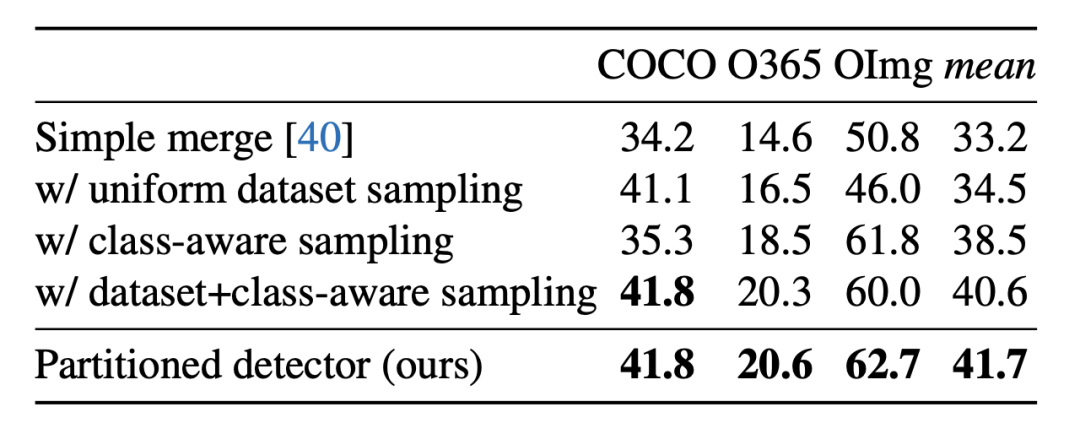
表1 不同Sampling策略效果
如表1 所示,作者对比了在不同sampling策略下的效果。其中uniform dataset sampling表示平衡不同数据集间的样本数量;class-aware sampling表示平衡数据集内的长尾效应,增加尾部类别被sample的概率。从结果可以看出uniform dataset sampling和class-aware sampling都是十分重要的。
NO.2
实验结果
作者使用了ResNet-50 backbone的CascadeRCNN进行实验。首先如表2所示,作者提出的多检测头模型在不融合标签空间的情况下已经可以比拟单检测头模型(8x schedule),为后面学习标签映射矩阵提供了可靠的检测结果。
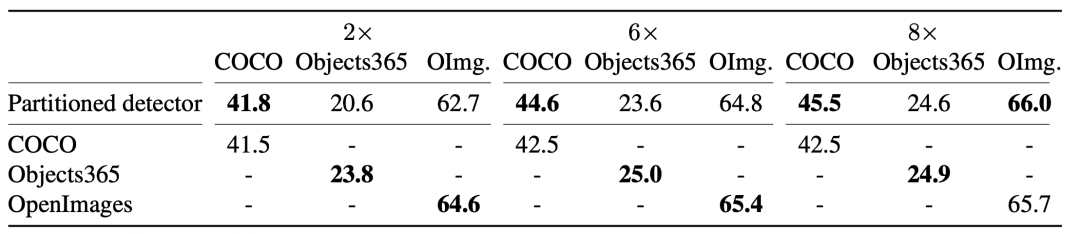
表2 多检测头模型与单检测头模型效果对比
通过上述方法学习到统一标签空间后,在表3中作者对比了不同版本统一标签空间对模型性能的影响(2x schedule)。
● GloVe embedding表示使用GloVe词向量合并相似的标签;
● Learned,distortion和Learned,AP表示使用论文中提出的方法,通过不同优化损失函数学习到的统一标签空间;
● Expert human表示人工手动合并的统一标签空间。
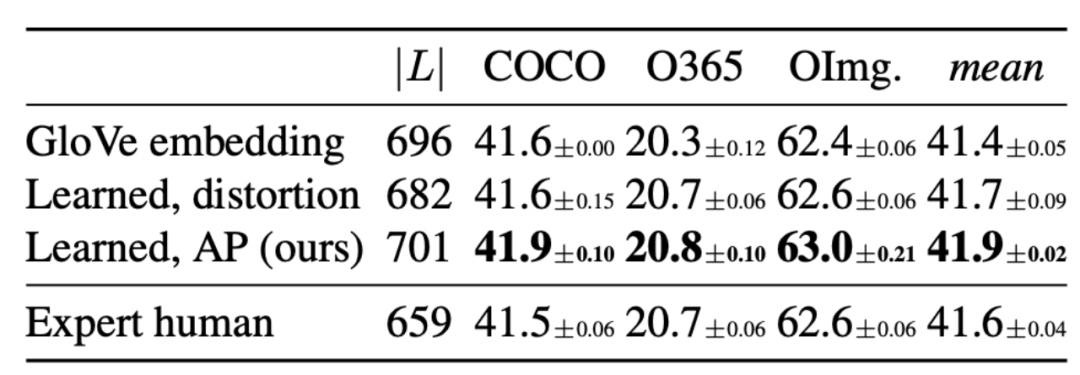
表3 不同版本标签空间效果对比
如表4所示,统一标签空间后的模型可以泛化应用到其他下游数据集,并在多数下游数据集上取得更好的效果。
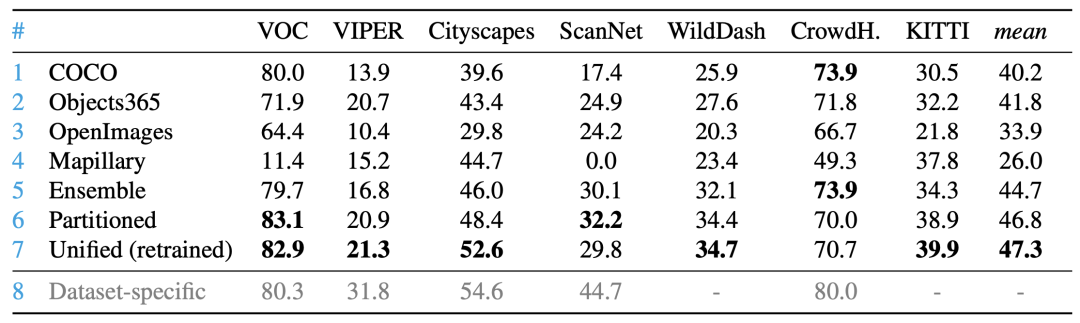
表4 在其他数据集上的泛化性能
最后如果将模型规模扩大,使用ResNeSt200作为backbone并训练8x schedule,模型的效果可以和一些SOTA模型相媲美。
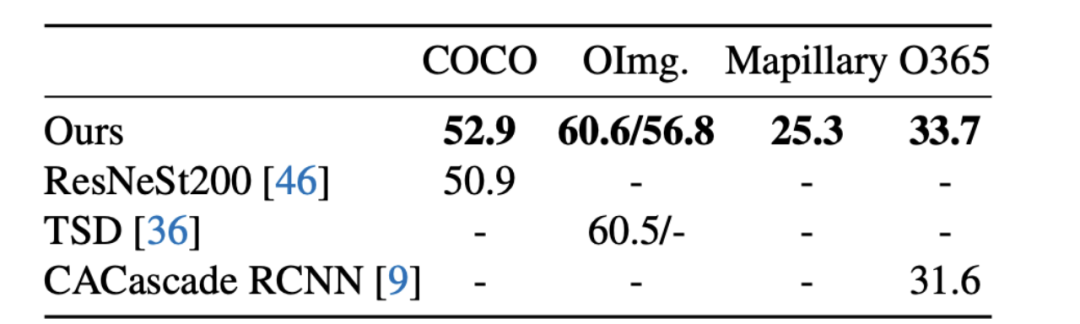
表5 扩大模型规模
作者对学习到的统一标签空间进行分析,发现该方法成功的将名字相同但语义不同的标签分开,将名字不同但语义相同的标签融合到一起。
三、实际操作
作者开源了论文的代码,下载地址:https://github.com/xingyizhou/UniDet
该论文依赖detectron2框架,需要先按照说明安装detectron2。说明文档:https://detectron2.readthedocs.io/en/latest/tutorials/install.html
安装好detectron2后需要将该论文代码放到projects目录下:
cd /path/to/detectron2/projects
git clone https://github.com/xingyizhou/UniDet.git推荐将需要的COCO,Objects365,OpenImages(使用2019 challenge版本)数据集下载到统一的文件夹。(下载地址:https://storage.googleapis.com/openimages/web/challenge2019.html)。下载好的COCO和Objects365可以直接使用,但OpenImages需要进行转换:
# 使用UniDet/tools/convert_datasets/convert_oid.py进行转换
python convert_oid.py --path /path/to/openimage --version challenge_2019 --subsets train
python convert_oid.py --path /path/to/openimage --version challenge_2019 --subsets val --expand_label按下面的命令将DETECTRON2_DATASETS变量指向下载数据集的文件夹,使detectron2可以读到数据集。
export DETECTRON2_DATASETS=/path/to/datasets接下来需要下载challenge-2019-label500-hierarchy.json文件。(下载地址:https://storage.googleapis.com/openimages/challenge_2019/challenge-2019-label500-hierarchy.json)。并将UniDet/unidet/evaluation/oideval.py文件中的oid_hierarchy_path修改到该文件实际路径。

另外在UniDet/configs/中可以看到与OpenImages数据相关的config文件中有一项openimages_challenge_2019_train_v2_cat_info.json文件在代码仓库中并没有给出。
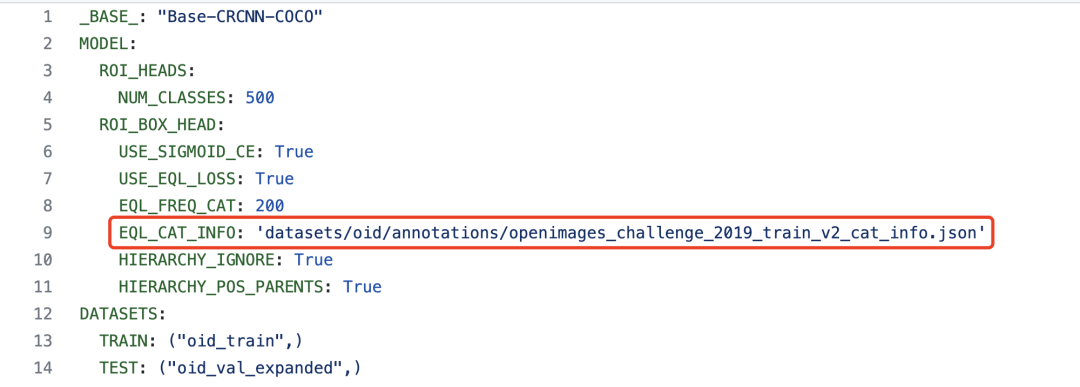
通过观察训练代码可得知该文件中存放有OpenImages数据集各类别的图片数量统计信息,可自行对OpenImages各类别的图片数进行统计来生成,具体格式如下:
[{"id": 419, "image_count": 45938}, {"id": 231, "image_count": 31351}, {"id": 71, "image_count": 130723}, {"id": 114, "image_count": 378077}, {"id": 117, "image_count": 3262}, {"id": 30, "image_count": 289999}, {"id": 11, "image_count": 58145}, {"id": 165, "image_count": 265635}, {"id": 345, "image_count": 29521}, ...]
至此,全部准备工作完成,可以开始训练。如果想以2x schedule训练一个多检测头模型,则可通过以下命令行实现:
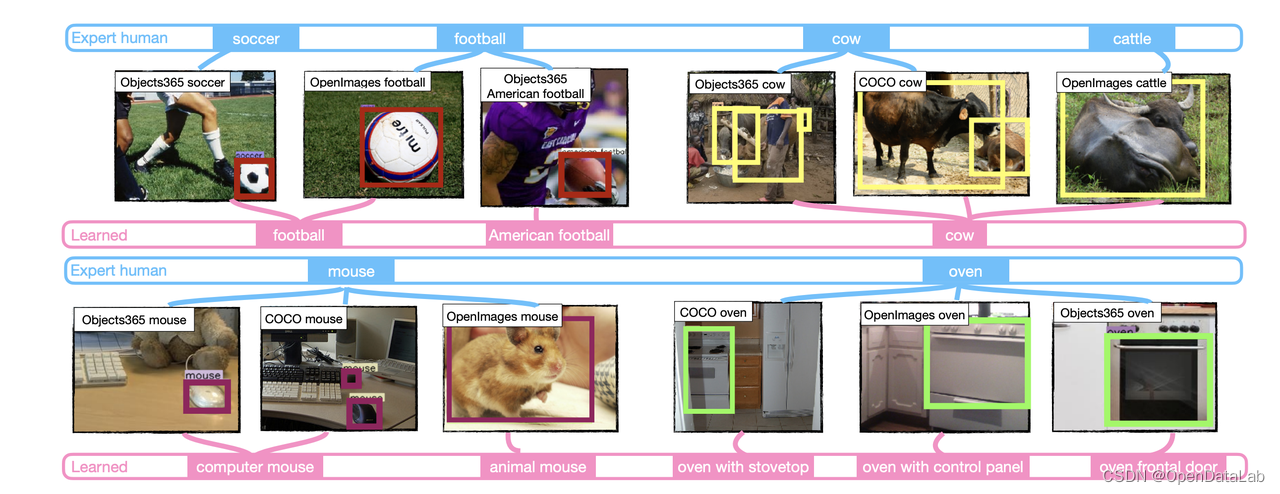
python UniDet/train_net.py --config-file UniDet/configs/Partitioned_COI_R50_2x.yaml在UniDet/datasets/label_spaces/中,作者给出了各类统一后的标签空间,这里展示一下按论文中提出的方法学习的标签空间:
如果想复现学习标签空间的步骤,可以在训练好多检测头模型后得到在三个数据集的验证集上的推理结果,并按照UniDet/tools/UniDet_learn_labelspace_mAP.ipynb中的步骤运行即可。
如果想添加自定义数据集,可以在UniDet/unidet/data/datasets/中注册自定义数据集,并修改config文件。具体如何注册可参考detectron2文档:https://detectron2.readthedocs.io/en/latest/tutorials/datasets.html
四、数据集下载
本文提到的相关数据集免费、高速检索、下载地址:
● COCO 2014:https://opendatalab.org.cn/COCO_2014
● COCO 2017:https://opendatalab.org.cn/COCO_2017
● Objects365:https://opendatalab.org.cn/Objects365
● OpenImages Challenge 2019:https://opendatalab.org.cn/Open_Images_Challenge_2019
● OpenImages V4:https://opendatalab.org.cn/Open_Images_V4
● OpenImages V6:https://opendatalab.org.cn/OpenImages-v6
还有哪些你想了解的数据集?更多资源请访问OpenDataLab官网,3700+海量、安全、便捷的数据集资源满足你的需求,欢迎体验与下载。(点击原文查看)
● OpenDataLab官网:https://opendatalab.org.cn/
五、后记
本文介绍了集成多个数据集训练存在的问题以及一篇简单的集成多数据集训练的论文,并介绍了该论文代码的使用方法及相关数据集资源。后续也会继续介绍其他集成多个数据集训练的方法,点赞、转发、分享助力更新~
参考文献
[1] Zhou, Xingyi, Vladlen Koltun, and Philipp Krähenbühl. "Simple multi-dataset detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[2] Zhao, Xiangyun, et al. "Object detection with a unified label space from multiple datasets." European Conference on Computer Vision. Springer, Cham, 2020.
作者丨Langy
相信光的力量
- End -
以上就是本次分享,获取海量数据集资源,请访问OpenDataLab官网;获取更多开源工具及项目,请访问OpenDataLab Github空间。另外还有哪些想看的内容,快来告诉小助手吧。更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying加入OpenDataLab官方交流群。