Bag of Freebies for Training Object Detection Neural Networks
摘要: 提高深度学习模型精度主要有以下一些方面:1. 更好的模型如vgg-resnet-densenet;2. 更多的数据;3. 更好的tricks。这篇文章主要从tricks方面入手来讨论一些tricks对模型的提高。
而且,深度学习有一些技巧是针对特定的模型才有提升作用的,这些技巧不具有可复制性,不好。所以我们需要找那些具有可复制性的技巧,不用太多调整参数就可以有几个点的提升。这才是一个好的tricks。
这篇文章探究了:
- mixup,并提出了一种新的 visually coherent image mixup方法
- 学习率的调整规则
- 标签平滑
- synchronized 批归一化
然后论文在单阶段和多阶段的目标检测器上做了相关实验。
借助这些策略,做到了最大5%的精度提升

3. 技巧
3.1 Visually Coherent Image Mixup视觉上连贯的图像混淆
**图像分类中的mixup技巧
图像融合+标签融合
目标检测中mixup技巧

mixup融合的比例是从一个beta(0.2,0.2)的分布中取出来的。作者认为这个beta分布是不完美的。用一个“大象实验”来说明的。将一张单独的大象方块图片随机的放到一张自然图片中,然后将这张图片送入目标检测器,现有目标检测器对这种测试不够鲁棒,不能很好的检测出图片中的大象。
实验发现增大beta分布的参数值,能得到更好的mixup效果。
在yolov3上测试发现确实增大beta分布参数的值确实有助于提高模型精度

这种mixup增加了目标之间的重叠现象。对于常见的相互对象遮挡的对象检测,网络被鼓励观察不寻常的拥挤补丁,这些补丁要么是自然呈现的,要么是由对抗技术创建的。
- 重叠有助于提高目标检测器(不知道在人脸检测是否适用,因为人脸检测的论文并没有做这项)

在大象实验中,没有用mixup策略训练的模型很难检测出大象。采用mixup技巧的模型则能更好的检测出。但是mixup模型的平均置信度更低。但是不影响测试的结果。
3.2 标签平滑
one-hot+softmax容易使模型产生过度拟合。所以采用label smoothing。
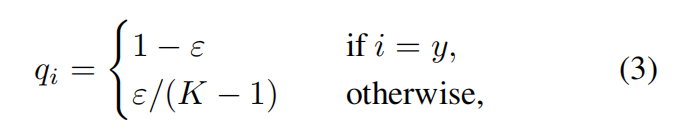
3.3 图像处理
在图像分类领域中,神经网络通常对图像的几何变换具有很强的容忍度。为了提高泛化精度,避免过拟合,建议对空间特征进行随机扰动,如随机翻转、旋转、裁剪等。然而,对于目标检测的图像预处理,我们需要额外的谨慎,因为检测网络对这种转换更敏感。
- 包括随机裁剪(带约束)、随机扩展、随机水平翻转和随机调整大小(带随机插值,不同的插值方法)
- 随机的颜色抖动,包括亮度、色度、饱和度和对比度
在训练faster-rcnn的时候不进行随机采样(随机crop)因为roi的生成和随机crop有异曲同工之处。
3.4 学习速率的调整
3.5 Synchronized Batch Normalization批归一化
3.6 随机训练图片尺寸,单阶段检测器
用H = W ∈ {320, 352, 384, 416, 448, 480, 512, 544, 576, 608}来训练yolov3
4. 结果
请注意,为了消除测试时间技巧的副作用,我们总是使用标准的非最大抑制实现来报告单个尺度、单个模型的结果。我们在实验中不使用外部训练图像或标签
4.1 voc数据集

- mixup的效果最好,这就是可复制性的技巧
- data augmentaition对单阶段的检测器具有更多的重要性
在coco数据集上的结果
可复制性的技巧
- data augmentaition对单阶段的检测器具有更多的重要性

在coco数据集上的结果
