向大家介绍一篇今天新出的非常有意思的 CVPR 2023 的论文,相比于传统的目标检测算法,训练时标注了几个类别,就只能检测几个类别,这篇论文属于通用目标检测的范畴。
通过在训练过程中图像和文本对齐,它可以自动扩展到检测那些视觉标注中没有出现的类别。
这将有效帮助视觉系统目标检测能力的迁移,感觉是非常有前途的技术方向。
论文信息:

这篇论文作者大多数是国内学者。
传统的物体检测算法受限于繁琐的人工标注,在开放世界中出现新类别后往往需要“从头来过”,即使只增加一个新类别,也要完整过一遍标注、训练、部署整个流程,严重限制了其通用性,这显然不“科学”。
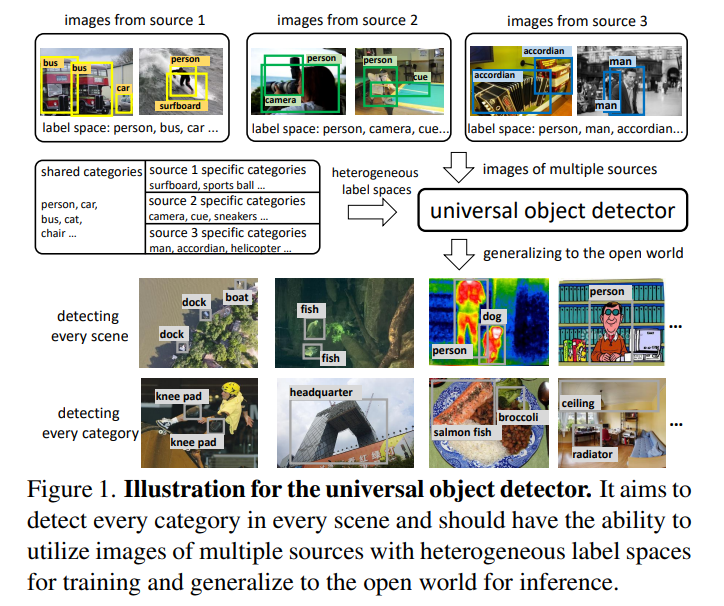
该论文作者提出了UniDetector,就是要让目标检测器具有识别开放世界中大量类别的能力。
其核心关键点:
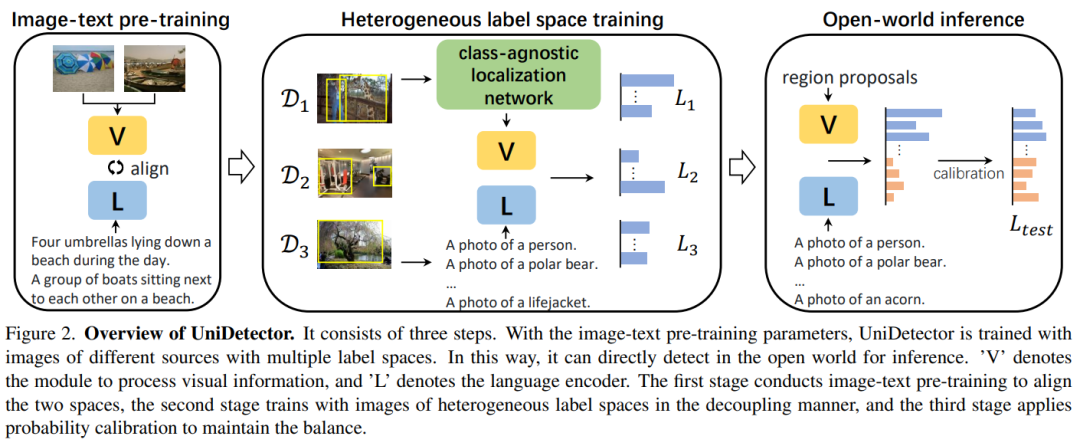
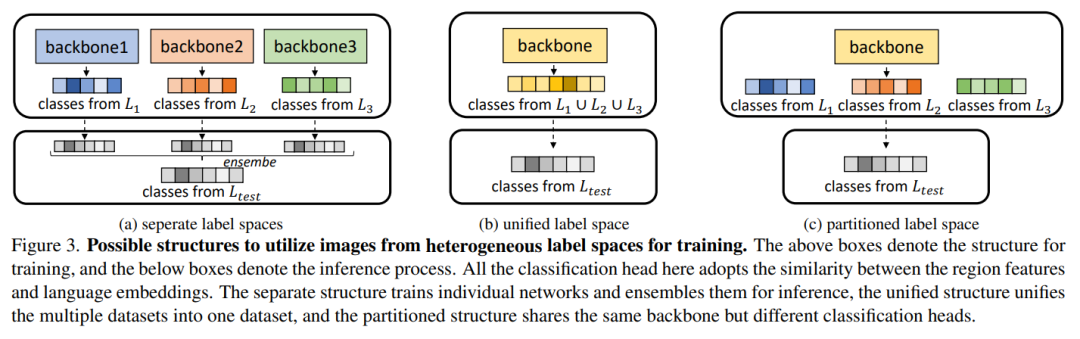
1)基于图像和文本空间的对齐,利用多个来源和异构标签空间的图像进行训练,保证了通用表示的充分信息。
2)由于视觉和语言模态的丰富信息,使其易于推广到开放世界,同时保持已知和未知类别之间的平衡。
3)为了应对训练中的新挑战,作者还提出了提出的解耦训练方式和概率校准,进一步提高了对新类别的泛化能力。
论文中仅用了500个类别参与训练,就可以使UniDetector检测超过7k个类别!而这并不是代表UniDetector只能检测7K个类别,而是现有公开数据集只能让这项研究最多在7K个类别上进行检测和评估!
(好吧,这个世界限制了UniDetector的发挥~)
UniDetector算法示意:
UniDetector算法流程:
训练过程中的异构标签空间:
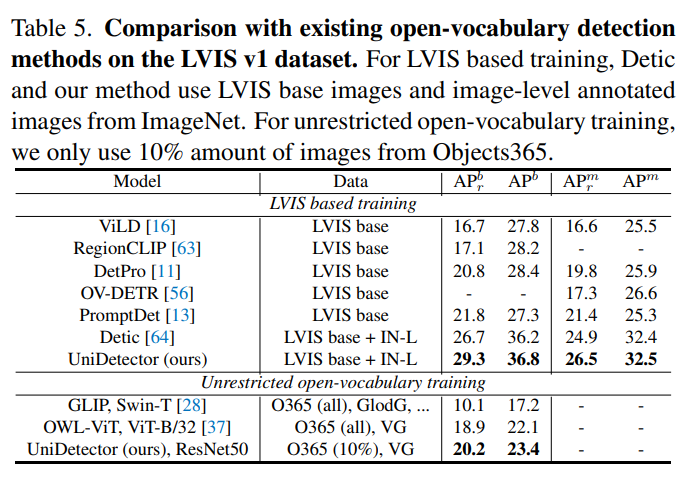
通过实验发现,在具有大量类别的目标检测数据集LVIS、ImageNetBoxes和VisualGenome上,UniDetector表现出强大的零样本泛化能力(也就是数据集中参与训练的图像样本为0个),超过传统监督算法平均4%以上!而在另外13个具有不同场景的目标检测数据集上,UniDetector仅使用3%的训练数据就实现了最先进的性能!
在开放世界数据集上的检测性能:

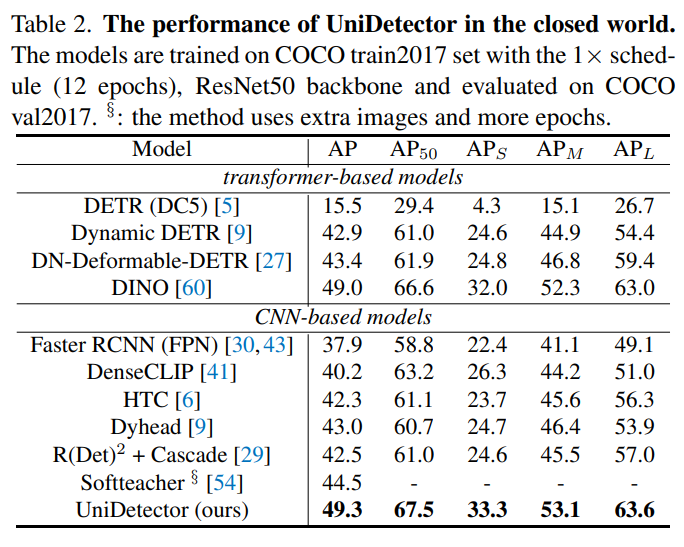
在COCO数据集上的性能:
零样本设置下 在 13 个开放世界数据集上的检测性能:

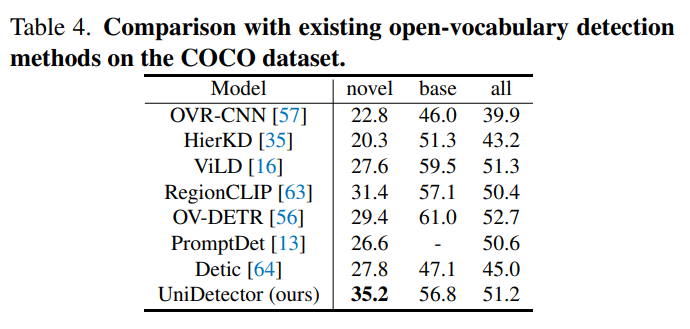
在COCO数据集上与其他开放类别的目标检测方法的比较:
在LVIS 数据集上与其他开放类别的目标检测方法的比较: