ARIMA模型
时间序列模型的意义:
在经典的回归模型中,主要是通过回归分析来建立不同变量之间的函数关系(因果关系),以考察事物之间的联系。本案例要讨论如何利用时间序列数据本身建立模型,以研究事物发展自身的规律,并据此对事物未来的发展做出预测。研究时间序列数据的意义:在现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。在现实中很多问题,如利率波动、收益率变化、反映股市行情的各种指数等通常都可以表达为时间序列数据,通过研究这些数据,发现这些经济变量的变化规律(对于某些变量来说,影响其发展变化的因素太多,或者是主要影响变量的数据难以收集,以至于难以建立回归模型来发现其变化发展规律,此时,时间序列分析模型就显现其优势——因为这类模型不需要建立因果关系模型,仅需要其变量本身的数据就可以建模),这样的一种建模方式就属于时间序列分析的研究范畴。而时间序列分析中,ARIMA模型是最典型最常用的一种模型。
适用与时间序列预测的数据应具有一下性质:
(1)平稳性:
-
平稳性就是要求经由样本时间序列所得到的拟合曲线,在未来的一段期间内仍能顺着现有的形态“惯性”地延续下去
-
平稳性要求序列的均值和方差不发生明显变化
(2)严平稳与弱平稳:
- 严平稳:严平稳表示的分布不随时间的改变而改变。
如:白噪声(正态),无论怎么取,都是期望为0,方差为1 - 弱平稳:期望与相关系数(依赖性)不变,未来某时刻的t的值Xt就要依赖于它的过去信息,所以需要依赖性
(3)差分法:时间序列在t与t-1时刻的差值
一阶差分
二阶差分(在一阶差分的序列基础上进行差分)
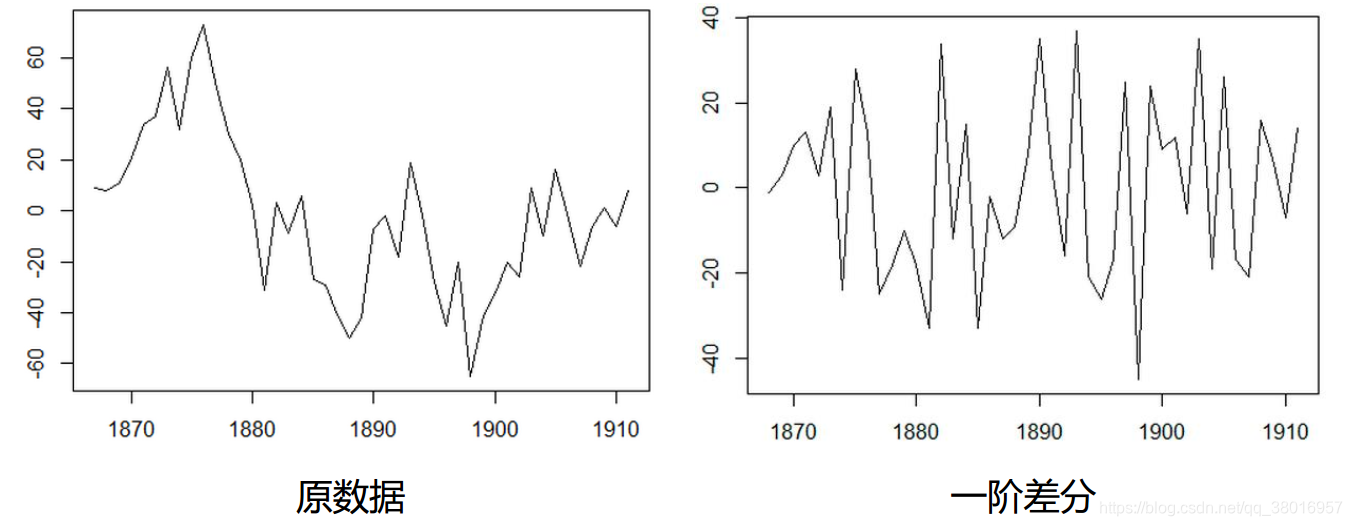
ARIMA模型与ARMA模型的区别:ARMA模型是针对平稳时间序列建立的模型。ARIMA模型是针对非平稳时间序列建模。换句话说,非平稳时间序列要建立ARMA模型,首先需要经过差分转化为平稳时间序列,然后建立ARMA模型。
1、自回归模型-AR
回归:通过拟合数据,建立回归方差,求出系数
自回归:没有变量之间的关系,只有当前值和历史值之间的关系,用变量自身的历史数据对自身进行预测
自回归模型必须满足平稳性的要求
p阶自回归过程的公式定义:
- p阶:与历史的p天(时间间隔)的关系(通过自相关系数求得有关系的阶数)
- 函数 y 表示 第 yt 天 与 第 y_t-i 天 的关系,
*其中gama_i为自相关系数,为需求解的参数
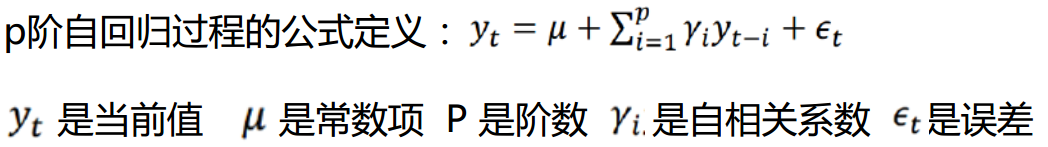
自回归模型的限制
- 自回归模型是用自身的数据来进行预测
- 必须具有平稳性
- 必须具有自相关性,如果自相关系数(φi)小于0.5,则不宜采用
- 自回归只适用于预测与自身前期相关的现象
2、移动平均模型-MA
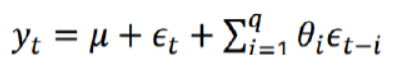
- 移动平均过程其实可以作为自回归过程的补充,解决自回归方差中白噪声的求解问题
- 移动平均具有滞后性
3、 自回归移动平均模型ARMA:
自回归移动平均模型由两部分组成:自回归部分和移动平均部分,因此包含两个阶数,可以表示为ARMA(p,q),p是自回归阶数,q为移动平均阶数,回归方程表示为:
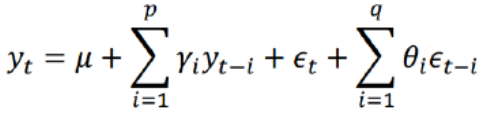
从回归方程可知,自回归移动平均模型综合了AR和MA两个模型的优势,在ARMA模型中,自回归过程负责量化当前数据与前期数据之间的关系,移动平均过程负责解决随机变动项的求解问题,因此,该模型更为有效和常用。
4、差分自回归移动平均模型-ARIMA(p,d,q)
*(Autoregressive Integrated Moving Average Model,简记ARIMA)
- AR是自回归 ,p为自回归项
- MA为移动平均,q为移动平均项数
- d为时间序列成为平稳时所做的差分次数
介绍时间序列平稳性时提到过,AR/MA/ARMA模型适用于平稳时间序列的分析,当时间序列存在上升或下降趋势时,这些模型的分析效果就大打折扣了,这时差分自回归移动平均模型也就应运而生。ARIMA模型能够用于齐次非平稳时间序列的分析,这里的齐次指的是原本不平稳的时间序列经过d次差分后成为平稳时间序列。
原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值(q)以及随机误差项的现值和滞后值进行回归所建立的模型
**移动平均的滞后性
小结:AR/MA/ARMA/ARIMA模型体系是从时间序列数值本身的相关关系出发,将移动平均技术、相关分析技术和平稳技术(差分)等纳入模型,力求建立时间序列数值之间的回归方程,从而达到预测的目的。
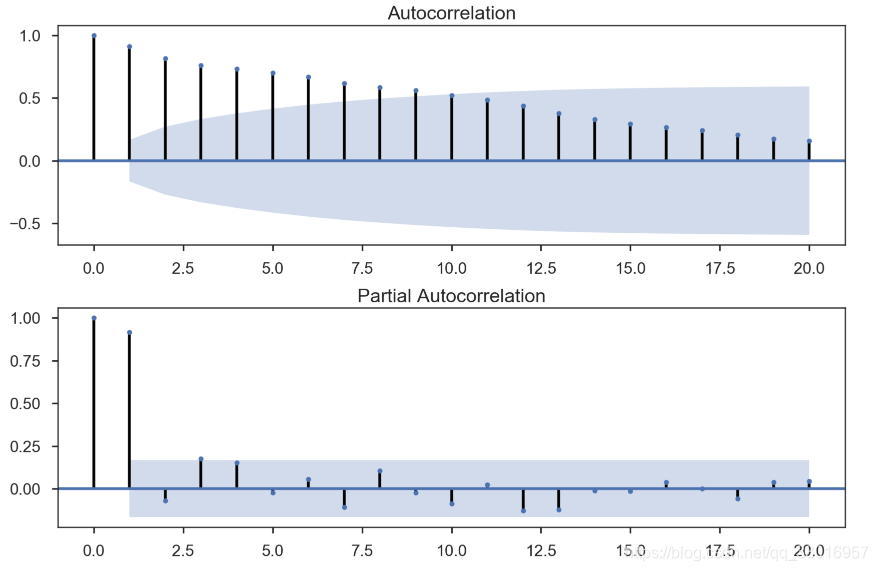
4-1 自相关函数ACF(autocorrelation function)
-
相关性:
两个自变量x、y若变化趋势相同,则为+1
若变化趋势相反,则为-1
若变量间没有关系,则为0 -
有序的随机变量序列与其自身相比较
-
自相关函数反映了同一序列在不同时序的取值之间的相关性
现时间序列只有一个变量,需找出当前变量与滞后变量(不同阶数)之间的相关性,即可确定AR模型p
公式:
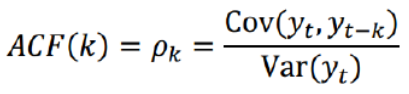
*Pk的取值范围 :[-1,1]
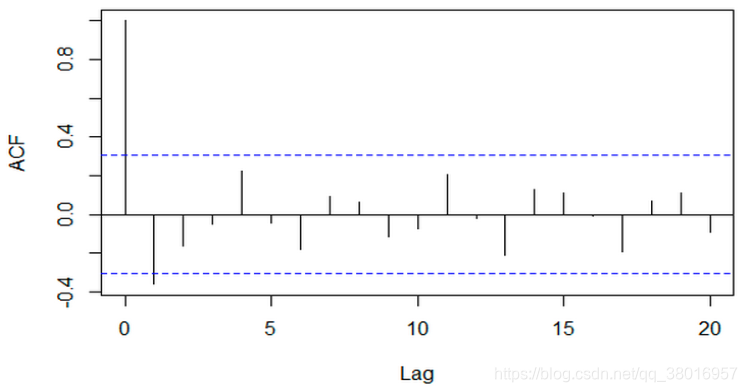
*置信区间(蓝色区域):当前样本有一百个,其中95个样本符合当前的逻辑,则置信区间为95%
当前值与不同阶数(当前值与历史p天的关系)的相关性:(横轴为阶数,纵轴为相关性)
4-2 偏自相关函数(PACF)(partial autocorrelation function)
-
对于一个平稳AR( p)模型,求出滞后k自相关系数p(k)时,实际上得到并不是x(t)与x(t-k)之间单纯的相关关系
-
x(t)同时还会受到中间k-1个随机变量x(t-1)、 x(t-2)、 ……、 x(t-k+1)的影响,而这k-1个随机变量又都和x(t-k)具有相关关系(阶数之间是相互影响的)
-
所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响
-
而PACF剔除了中间k-1个随机变量x(t-1)、 x(t-2)、 ……、 x(t-k+1)的干扰之后,x(t-k)对x(t)影响的相关程度
(ACF还包含了其他变量的影响)
而偏自相关系数PACF是严格这两个变量之间的相关性
4-3 ARIMA(p,d,q)模型阶数确定
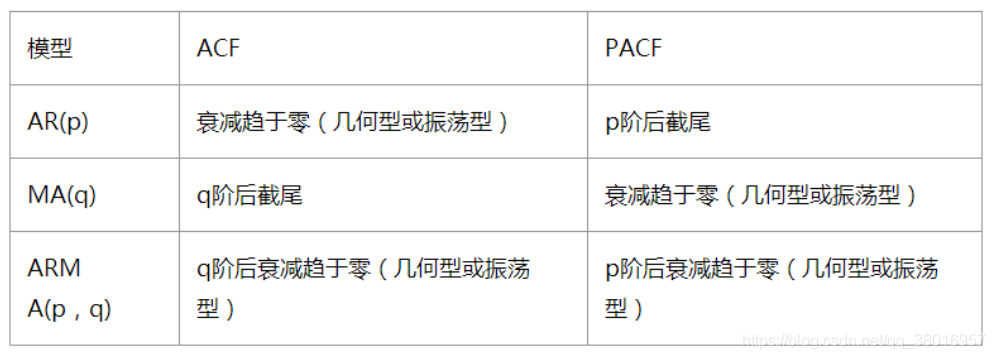
根据AC和PAC图可以判断出p、q的大概值(方法一):
-
P的判断:
AR( p)模型的自相关系数是随着k的增加而呈现指数衰减或者震荡式的衰减,具体的衰减形式取决于AR( p)模型滞后项的系数;
AR( p)模型的偏自相关系数是p阶截尾的。因此可以通过识别AR§模型的偏自相关系数的个数来确定AR( p)模型的阶数p。 -
q的判断
MA(q)模型的自相关系数在q步以后是截尾的。MA(q)模型的偏自相关系数一定呈现出拖尾的衰减形式。 -
ARMA(p,q)模型是AR( p)模型和MA(q)模型的组合模型,因此ARMA(p,q)的自相关系数是AR( p)自相关系数和MA(q)的自相关系数的混合物。当p=0时,它具有截尾性质;当q=0时,它具有拖尾性质;当p,q都不为0,它具有拖尾性质。
-
通常,ARMA(p,q)过程的偏自相关系数可能在p阶滞后前有几项明显的尖柱,但从p阶滞后项开始逐渐趋于0;而它的自相关系数则是在q阶滞后前有几项明显的尖柱,从q阶滞后项开始逐渐趋于0。
*截尾:落在置信区间内(95%的点都符合该规则)
5、ARIMA建模流程
(1)将序列平稳(差分法确定d)
(2)p和q阶数确定:ACF与PACF
(3)ARIMA(p,d,q)
6、ARIMA模型评估标准
参数和最终结果精度的权衡
(1)AIC:赤池信息准则(Akaike Information Criterion,AIC)
AIC = 2k - 2ln(L)
(2)BIC:贝叶斯信息准则(Bayesian Information Criterion,BIC)
BIC = k*ln(n) - 2ln(L)
k为模型参数个数,n为样本数量,L为似然函数
评估标准:选择更简单的模型,即p, q越小,参数项越少,k值越小,AIC和BIC相应得到的值也越小(标准)
BIC的绘制:先从AC和PAC图得出p、q最大最小值,再对不同的p、q进行遍历,得到下图。
在下图中选择最小的值(即为简单的模型),即可选择合适的p,q:
(横纵轴为p、q)

7、模型残差检验:(检验模型的平稳性)
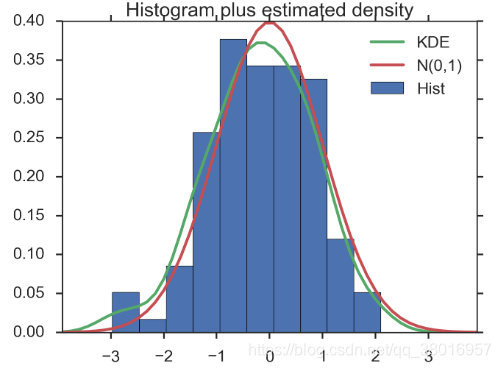
(1)ARIMA模型的残差是否是平均值为0且方差为常数的正态分布
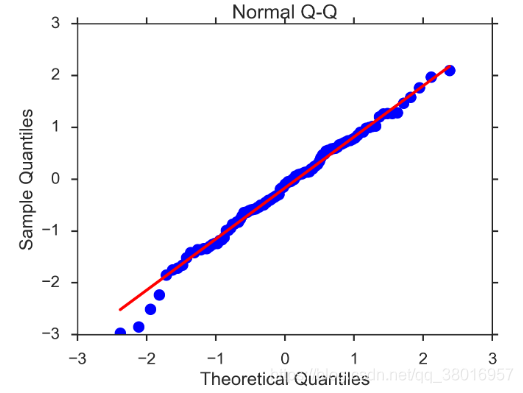
(2)QQ图:线性即正态分布
正太分布图:
QQ图:(若为直线的,则是平稳的模型)