时间序列分析?
时间序列,就是按时间顺序排列的,随时间变化的数据序列。
生活中各领域各行业太多时间序列的数据了,销售额,顾客数,访问量,股价,油价,GDP,气温。。。
常用的时间序列模型
常用的时间序列模型有四种:
- 自回归模型 AR§
- 移动平均模型 MA(q)
- 自回归移动平均模型 ARMA(p,q)
- 自回归差分移动平均模型 ARIMA(p,d,q),
随机过程的特征有均值、方差、协方差等。
如果随机过程的特征随着时间变化,则此过程是非平稳的;相反,如果随机过程的特征不随时间而变化,就称此过程是平稳的。
下图所示,左边非稳定,右边稳定。
可以说前三种都是 ARIMA(p,d,q)模型的特殊形式。
ARIMA模型
ARIMA模型(英语:Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),时间序列预测分析方法之一。ARIMA(p,d,q)中,AR是"自回归",p为自回归项数;MA为"滑动平均",q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数)。“差分”一词虽未出现在ARIMA的英文名称中,却是关键步骤。
ARIMA模型 是统计模型(statistic model)中最常见的一种用来进行时间序列 预测的模型。

模型十分简单,只需要内生变量而不需要借助其他外生变量
模型训练步骤
(一)根据时间序列的散点图、自相关函数和偏自相关函数图以ADF单位根检验其方差、趋势及其季节性变化规律,对序列的平稳性进行识别。一般来讲,经济运行的时间序列都不是平稳序列。
(二)对非平稳序列进行平稳化处理。如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理,如果数据存在异方差,则需对数据进行技术处理,直到处理后的数据的自相关函数值和偏相关函数值无显著地异于零。
(三)根据时间序列模型的识别规则,建立相应的模型。若平稳序列的偏相关函数是截尾的,而自相关函数是拖尾的,可断定序列适合AR模型;若平稳序列的偏相关函数是拖尾的,而自相关函数是截尾的,则可断定序列适合MA模型;若平稳序列的偏相关函数和自相关函数均是拖尾的,则序列适合ARMA模型。
(四)进行参数估计,检验是否具有统计意义。
(五)进行假设检验,诊断残差序列是否为白噪声。
(六)利用已通过检验的模型进行预测分析。
练习
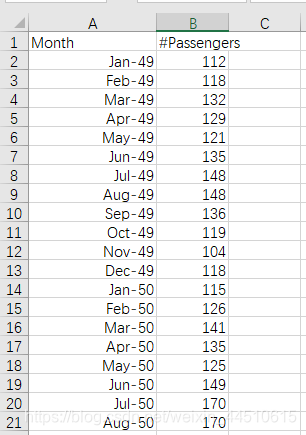
Jan-49 代表1949-01-01 一直到1960-12-01
从以前的乘客人数预测以后的乘客人数
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
# 从statsmodels导入arima
from statsmodels.tsa.arima_model import ARIMA
import matplotlib as mpl
import matplotlib.pyplot as plt
import warnings
from statsmodels.tools.sm_exceptions import HessianInversionWarning
def extend(a, b):
'''
选出两个维度,a和b;选择出其最大最小值
:param a:
:param b:
:return:
'''
return 1.05*a-0.05*b, 1.05*b-0.05*a
def date_parser(date):
'''
格式化时间
:param date:
:return:
'''
return pd.datetime.strptime(date, '%Y-%m')
if __name__ == '__main__':
warnings.filterwarnings(action='ignore', category=HessianInversionWarning)
pd.set_option('display.width', 100)
np.set_printoptions(linewidth=100, suppress=True)
data = pd.read_csv('.\\AirPassengers.csv', header=0, parse_dates=['Month'], date_parser=date_parser, index_col=['Month'])
data.rename(columns={'#Passengers': 'Passengers'}, inplace=True)
print(data.dtypes)
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 使用对数的方法,这样准确度更高,也就是缩小数据
x = data['Passengers'].astype(np.float)
x = np.log(x)
print(x.head(10))
show = 'prime' # 'diff', 'ma', 'prime'
d = 1
diff = x - x.shift(periods=d)
ma = x.rolling(window=12).mean()
xma = x - ma
p = 8
q = 8
model = ARIMA(endog=x, order=(p, d, q)) # 自回归函数p,差分d,移动平均数q
arima = model.fit(disp=-1) # disp<0:不输出过程
prediction = arima.fittedvalues
print(type(prediction))
y = prediction.cumsum() + x[0]
mse = ((x - y)**2).mean()
rmse = np.sqrt(mse)
plt.figure(facecolor='w')
if show == 'diff':
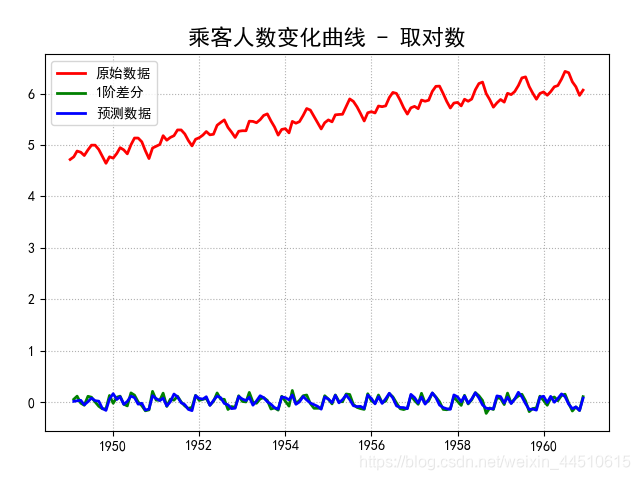
plt.plot(x, 'r-', lw=2, label='原始数据')
plt.plot(diff, 'g-', lw=2, label='%d阶差分' % d)
plt.plot(prediction, 'b-', lw=2, label=u'预测数据')
title = '乘客人数变化曲线 - 取对数'
elif show == 'ma':
plt.plot(x, 'r-', lw=2, label=u'原始数据')
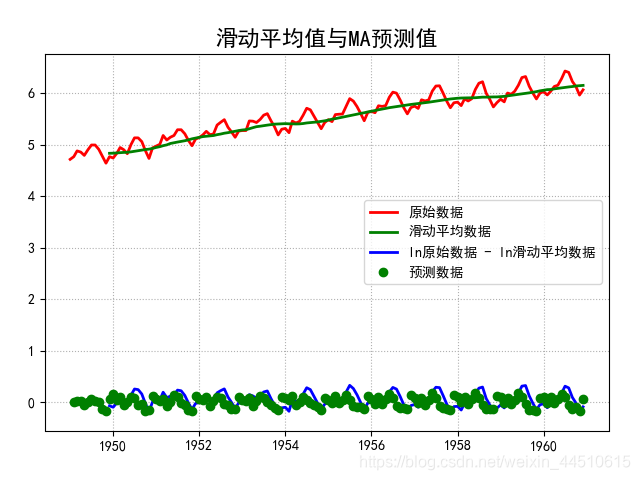
plt.plot(ma, 'g-', lw=2, label=u'滑动平均数据')
plt.plot(xma, 'b-', lw=2, label='ln原始数据 - ln滑动平均数据')
plt.plot(prediction, 'go', label='预测数据')
title = '滑动平均值与MA预测值'
else:
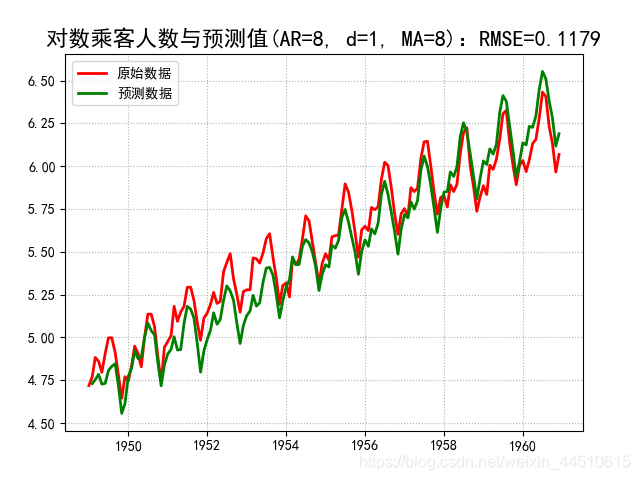
plt.plot(x, 'r-', lw=2, label='原始数据')
plt.plot(y, 'g-', lw=2, label='预测数据')
title = '对数乘客人数与预测值(AR=%d, d=%d, MA=%d):RMSE=%.4f' % (p, d, q, rmse)
plt.legend()
plt.grid(b=True, ls=':')
plt.title(title, fontsize=16)
plt.tight_layout(2)
plt.savefig('%s.png' % title)
plt.show()