大数据系列(一)hadoop生态圈基础知识
首语
15年做了大数据,跳槽之后,长达2年多,不停游走在web、手机端、后端、服务器,几乎没在碰过大数据,不知不觉hadoop生态圈愈发完善。本来自己做了自己的博客网站,奈何很久没维护,服务器到期了,然后凉凉斯密达。所以在csdn从头来过,收获良多,所以写一篇大数据系列文章,记录一下所有的知识,文章会包含入门的基础知识以及部分的实战演练。另外,如果有对前后端以及服务器整体devOps感兴趣的,可以联系我哦,大家共同进步。
初识hadoop
- hadoop是一个开源的分布式存储分布式计算平台
- hadoop可以创建大型数据仓库、PB级数据的存储、处理、分析、统计等业务
- hadoop多运用于搜索引擎、日志分析、商业智能、数据挖掘等等
- 后续会有大数据系列(一)的后续,对各个框架进行后续说明和一些demo演示
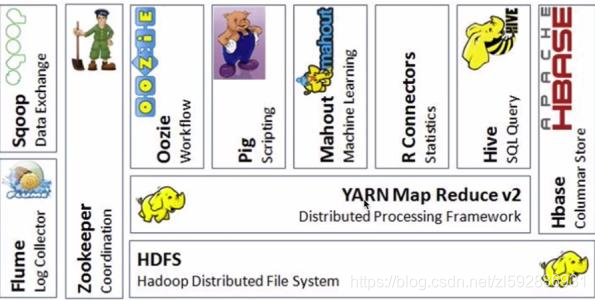
- hadoop生态系统图如下(通常现在数据计算由spark代替)
分布式文件系统HDFS
可以查看博主这篇博客,对HDFS稍作补充: https://blog.csdn.net/zl592886931/article/details/89792515
HDFS源自于谷歌爸爸的GFS论文,该论文发表于2003年10月,有兴趣的小伙伴可以查看
https://blog.csdn.net/three_man/article/details/44408825
HDFS的特点便是:极强的扩展性、优秀的容错性、海量数据存储
架构图如下:
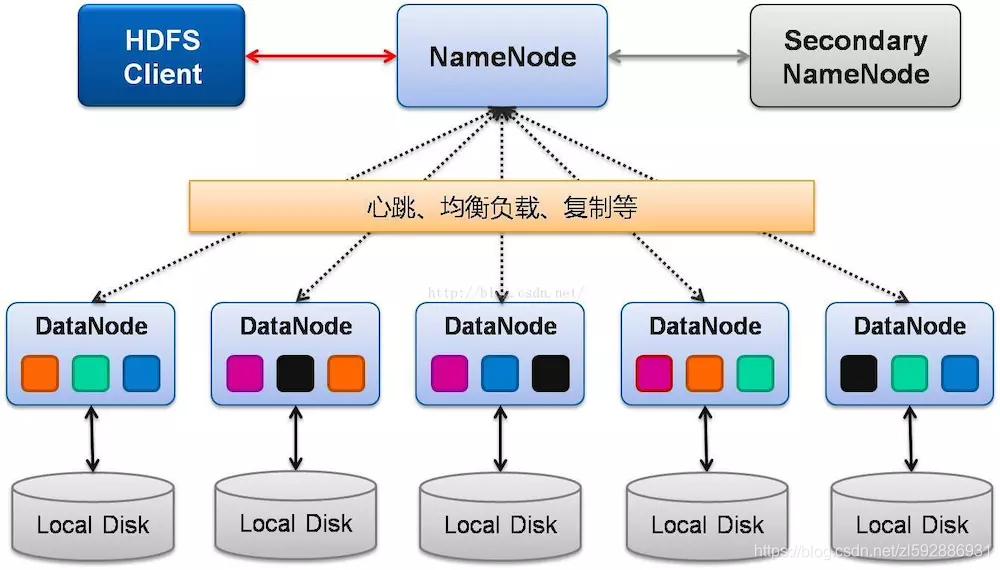
- 扩展性:hadoop是多节点数据存储,并且以集群方式存在,比如:当下你有100个节点,如果你的数据存不下,我们只需要再添加节点(DataNode)即可
- 容错性:hadoop的数据存储是以多副本的存储方式,存放在各个节点上。比如你有一个10M的文件,hadoop默认帮你同时在3台节点上存储你的数据,如果其中一个节点挂了,还有两个节点继续运行,无需担心数据丢失问题,极强的保障了数据一致性。
- 海量数据存储:hadoop适合海量数据存储(TB或者PB级别数据)
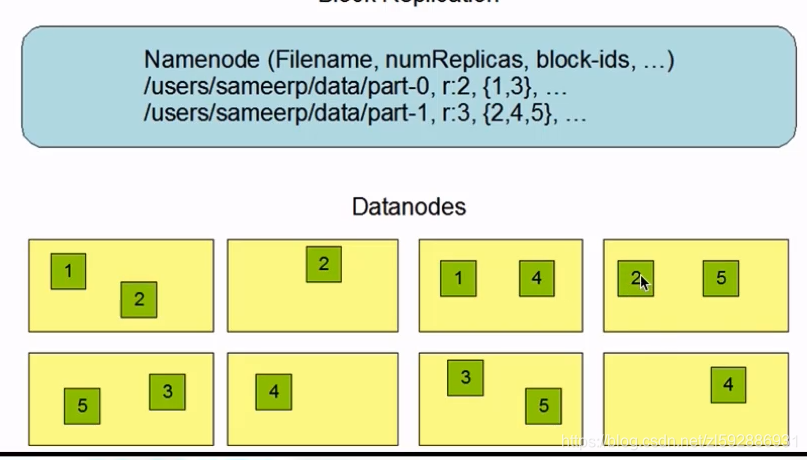
- 存储方式将文件切分成指定大小的数据块,并以多副本的方式存储在机器上,默认一个数据块为128M(可配置)。当数据切分、多副本存储、容错等事件发生时候,对用户是透明的。下图便是多副本存储,r:2,{1,3}表示,1与3有两个block存储块
分布式资源调度YARN(Yet Another Resource Negotiator)
yarn负责整个集群资源的管理和调度
yarn具有扩展性、容错性、兼容Pig、Hive、Hbase、Spark、Solr等多个大数据框架并可以实现资源统一调度
可以查看博主这篇博客,有对yarn做一些补充:https://blog.csdn.net/zl592886931/article/details/89792780
分布式计算框架MapReduce
WordCount的使用例子参考博主此篇博客:https://blog.csdn.net/zl592886931/article/details/89848752
源之于谷歌爸爸的MapReduce论文,论文发表于2004年12月,谷歌出品,必属精品,有兴趣可自行搜索
其特点依然是:扩展性、容错性、超大数据量离线处理(基于进程、大批量的处理,所以无法做到实时处理)
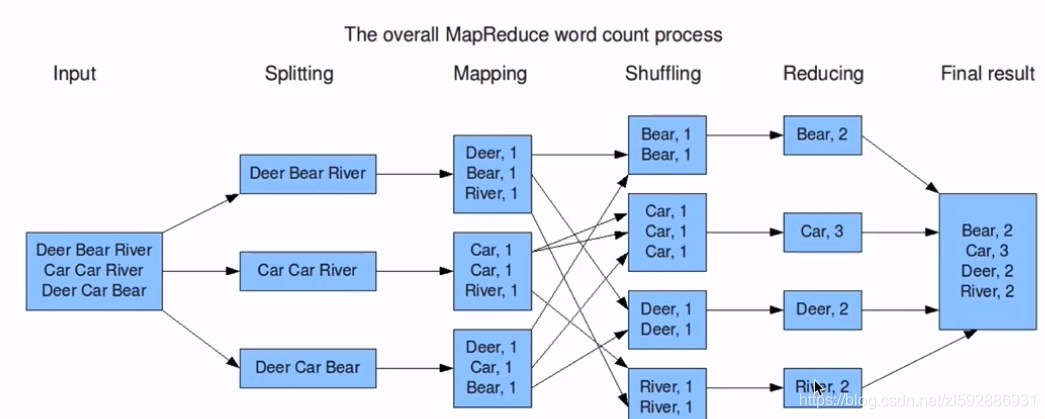
计算过程分为Map(映射、分批)、Reduce(合并计算)两个步骤,下图是wordcount处理过程:
Hadoop的优势
- 数据高可靠性: hadoop的数据存储在多个节点,并且支持数据重新调度计算,当一个节点发生故障,不仅可以保证数据不丢失,系统内部也支持重新调度作业进行数据计算,这些操作都对用户是透明无感的。
- 高扩展性:存储或者计算的资源不够时,可以横向线性扩展机器,一个集群中可以包含上千个节点
- 性价比高:Hadoop设计是存储在廉价机器上,用软件解决硬件问题。所以只需要一些廉价的机器,便可以运行一个超大数据的集群,hadoop还拥有比较成熟的生态圈,方便大数据开发。
环境搭建
参考博主的本篇博客:https://blog.csdn.net/zl592886931/article/details/89818448