Spark:计算引擎,框架媒介,调用配置所处位置下的机器的硬件设施来实现调用配置。使用内存来存储数据,运算快,断电丢失。对应于Hadoop圈中的MapReduce
Hbase:分布式、面向列的数据库,存储和读取媒介,来源于BigTable(一个结构化数据的分布式存储系统),但HBase是一个非结构化数据存储的数据库。是Hadoop项目的子项目
非结构化、面向列、稀疏
Hadoop:分布式系统基础框架,管理者。MapReduce使用硬盘存储数据
Storm:流式实时计算框架,实时处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。
大数据:量大类多的数据集
大数据的技术基础:MapReduce(分布式计算框架)、Google File System(分布式文件系统)和BigTable(数据存储系统)
结构化数据:数字、符号等数据
非结构化数据:文本、图像、声音、视频等数据
大数据分析:可视化分析(百度地图春节人口迁移大数据)、数据挖掘算法(沃尔玛啤酒与尿布、推荐、广告)、预测性分析能力(金融分析、股票预测、气象预测)、语义引擎(siri)、数据质量管理(去假留真)
分布式计算:把一组计算机通过网络相互连接组成分散系统,然后将需要处理的大量数据分散成多个部分,交由分散系统内的计算机组同时计算,最后将这些计算结果合并得到最终的结果。
服务器集群:由互相连接在一起的服务器群所组成的一个并行式或分布式系统。服务器集群中的服务器运行同一个计算任务。因此,从外部看,这群服务器表现为一台虚拟的服务器,对外提供统一的服务。
生态圈及其组件:
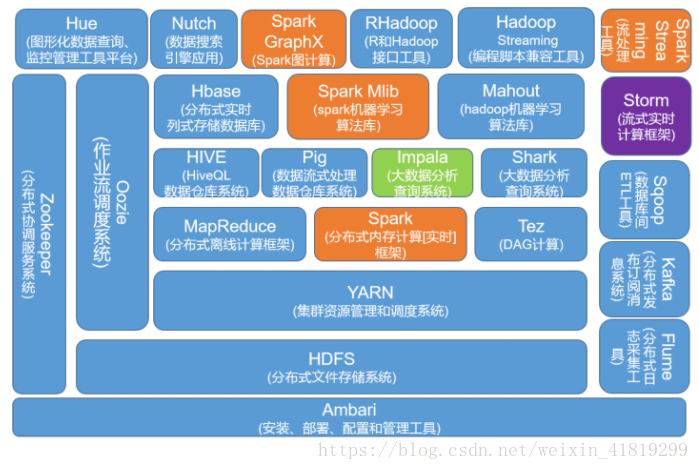
蓝色代表Hadoop生态系统组件,黄色Spark生态组件。Hadoop提供了Spark许多没有的功能,比如分布式文件系统,而Spark 提供了实时内存计算,速度非常快。
HDFS:Hadoop的分布式文件系统组件,运行在通用硬件上,使大量数据分布式存储到成千上百台机器
Hive、SparkSQL、Pig:数据仓库系统
YARN:为不同任务分配资源
MLlib:Spark机器学习组件