大数据系列(一)hadoop生态圈基础知识后续之HDFS
头脑风暴-最初的文件存储
单机时代,如同我们玩游戏的windows电脑,无论文件多大(如果存储空间不够就加硬盘或者扩充硬盘),都是存在了我们有很多小种子的E盘之内(手动斜眼笑)。想象一下,这个时候我们需要计算文件中:helloword这个单词出现的次数,只能选择计算整个文件,有可能计算一天,然而不幸的是,在23小时左右发生了故障,一切都白费了。又或者,正在计算的时候,硬盘烧毁了,这下惨了,不光计算没成,数据也没了。那么问题来了,如何解决这些问题?
- 做数据备份,将数据文件备份在多个电脑上:这样解决了硬盘烧毁,数据丢失问题
- 分布式数据计算:多个电脑同时开工,共同计算,给每个电脑分配任务,不同电脑计算不同的数据模块,解决计算时间长的问题
- 资源调度与健康检查:对这些电脑不停的检查,是否挂了。如果挂了,随时通知大家,把挂的那一份计算分配给剩下的电脑,解决了中途电脑宕机造成数据不准确
有了以上几条,你觉得可以了吗?No、No、No,骚年,你太天真了,我们设想一下,现在有3个文件分别为:1T、2T、3T,我们有4个电脑分别为:A1、A2、A3、A4, 我们尝试着来分配:A1(1T, 2T)、A2(1T, 2T)、A3(2T, 3T)、A4(3T),当数据更大,电脑节点更多的时候,无法保证资源利用率,并且很难进行并行处理,节点反而可能成为网络瓶颈
HDFS存储原理与架构
HDFS的架构图(官方文档图)

HDFS的组成
- HDFS通常由一个Master(NameNode,简称NN)和多个Slaves(DataNode,简称DN)组成
- 一个文件,被拆分成多个Block(默认128M),比如一个文件是200M,会被拆分成一个128M和一个72M两个文件,然后被存储在一系列DN上面,防止某机器挂掉(解决了上面头脑分包资源利用率低、无法很好的分布式并行计算)。
- NN负责客户端请求响应、元数据管理(文件名称、副本系数、Block存放的DN)
- DN负责存储文件对应的数据块(Block)、定期向NN汇报本身Block信息以及健康状况
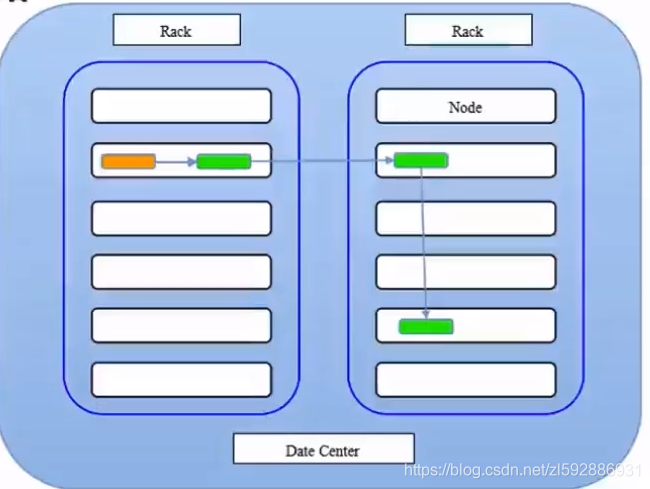
HDFS副本存放策略
文件被拆分成多个Block,每个Block存放多份(默认存放3份),下图:橘黄色标示客户端提交请求,那么Block优先存放当前节点上,然后另外一个优先存另一个Rack上,第三个在第二个Rack上随机存放。
HDFS环境搭建
参考博主此篇博客,基于云服务器,搭建分布式环境,利用3台服务器,当然可以随时扩展:https://blog.csdn.net/zl592886931/article/details/89818448
注意事项:
- 需要linux服务器
- 需要java环境,我们团队目前用的是jdk11,显然无法匹配hadoop,使用jdk1.8及以下版本。 HBase高版本好像也支持jdk11了,但是生产目前来说还是别冒风险
- hadoop配置文件修改(hadoop_home/etc/hadoop):
hadoop-env.sh配置 export JAVA_HOME=你的java路径
core-site.xml(默认文件系统的地址):
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0000(域名):8020</value>
</property>
<!--默认存储数据的地方是临时文件夹,linux重启,会删除临时文件,所以修改文件存储位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app</value>
</property>
hdfs-site.xml(设置副本系数,默认3,单机伪分布式部署的时候):
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 启动hdfs:
格式化文件系统(仅第一次执行,无需重复执行): hdfs namenode -format
启动hdfs:sbin/start-dfs.sh
检查是否启动:jps , 会出现所有java进程相关的程序
- hadoop shell的命令:前缀是hdfs dfs或者hadoop fs ,入hadoop fs -text xx.yml 查看xx.yml内容,加上前缀之后,和linux的命令差不多,如创建test文件夹: hadoop fs -mkdir text
HDFS文件存储位置以及Block分块
我们来继续实验一把,如果我们使用命令将文件存放在hdfs中,众所周知,文件超过128M(默认)会被分成block,那么我们怎么知道block在哪里呢,我们来找一找(注意所有对hdfs操作的命令均由NameNode完成)。
首先,我们来将jdk文件直接放入hdfs中:
1.先把jdk打个包
tar -zcvf jdk.tar.gz jdk1.8.0_171/*
然后查看包大小:

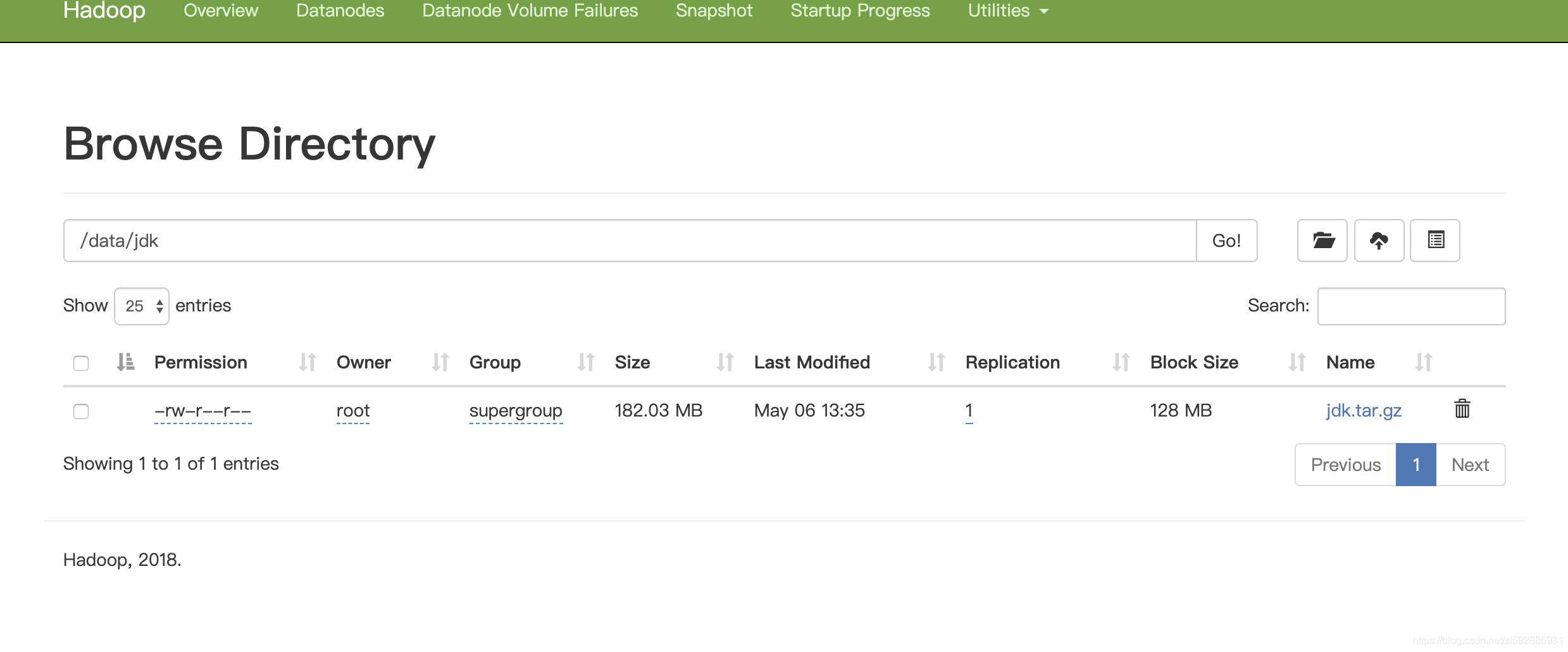
2.然后吧这个jdk包用put指令存入hdfs中/data/jdk(文件路径可自己设置,博主是存在这里的)
hadoop fs -put jdk.tar.gz /data/jdk
3.我们用命令查看一下是否已经存入
hadoop fs -ls -h /data/jdk
这里注意,我们下图文件行左边第二个是:1, 代表副本系数为1,意思是只存储了一份,所有另外几个datanode节点不会备份这个数据,为什么呢?原来我们在搭建环境的时候,设置了dfs.replication为1.这个需要按照实际需要自行设定
也可以用web页面查看(http://你自己的ip:9870/explorer.html#/):

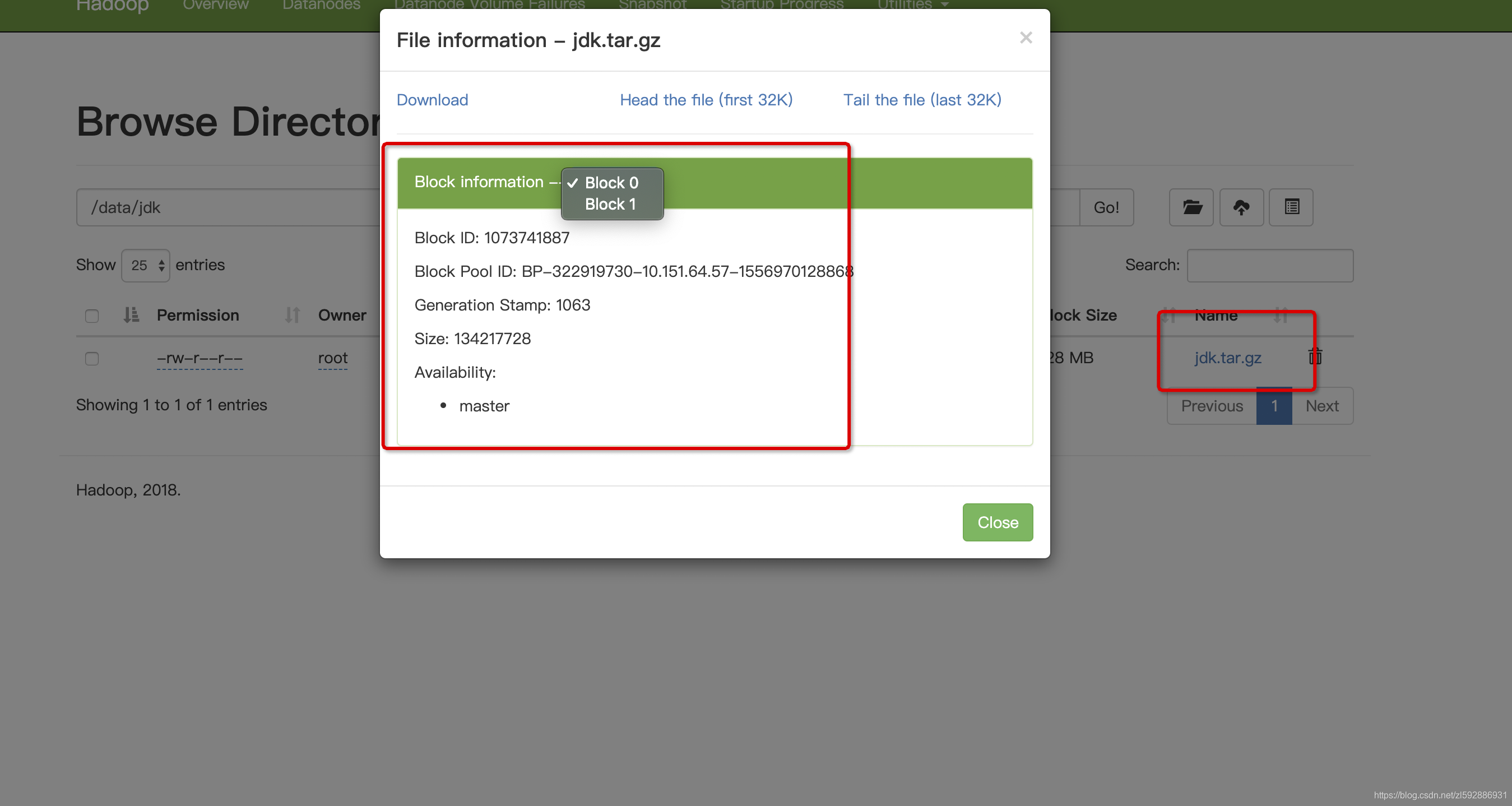
4.我们来查看一下文件是否被分成多个Block,默认一个block是128M,而我们文件是182M,所以应该被分成两个block,截图如下,我们看到文件果然被拆分成了两个block:
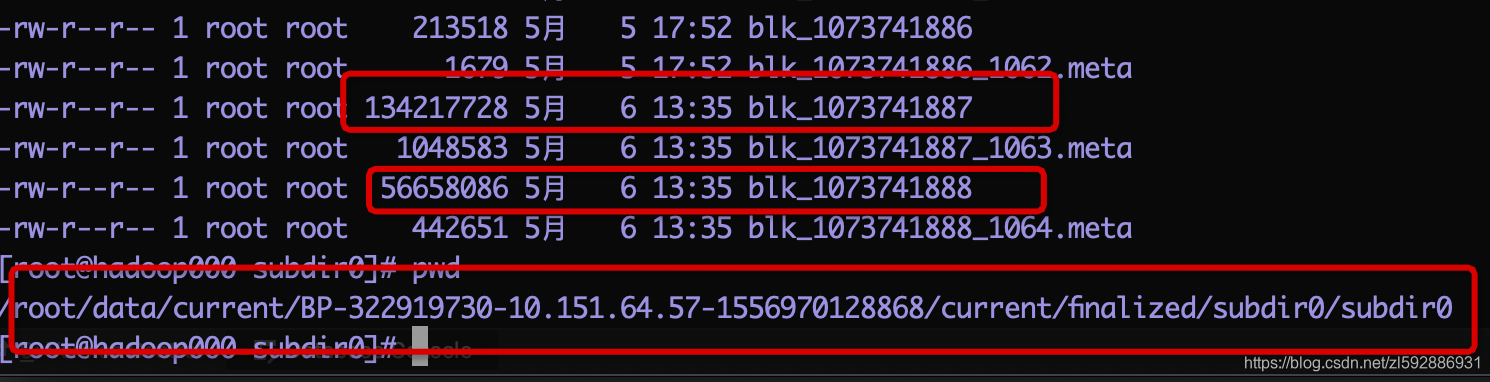
5.我们去hdfs系统上找一下block具体存储的信息在哪里:
我们的文件分成两个block,blockId分辨是:1073741887和1073741888,如下图,文件存储的位置已经找到:
来一次多副本文件存储
上面给大家展示了把文件放在hdfs中,我们可以直接从data中查看到真正block存储的地方,但是发现,另外两个DataNode并没有jdk这个文件包,这是因为我们在搭建环境的时候,设定了dfs.replication=1,所以副本只存一份,那么我们来尝试上传文件,指定副本系数,然后再去DataNode查看是否有多份数据.
1.将文件包上传,并指定副本系数为2,让我们2个datanode节点全部备份和存储数据
注意:namenode节点上本来就有一个datanode
先来将刚才的数据删除
hadoop fs -rm /data/jdk/jdk.tar.gz
然后:
hadoop dfs -D dfs.replication=2 -put jdk.tar.gz /data/jdk
查看一下:
hadoop fs -ls /data/jdk,如下(不截图了):
-rw-r--r-- 2 root supergroup 190875814 2019-05-06 14:07 /data/jdk/jdk.tar.gz
果然变成了两个副本系数
2.我们再去刚才的目录下看一下:
namenode上的datanode存储为:
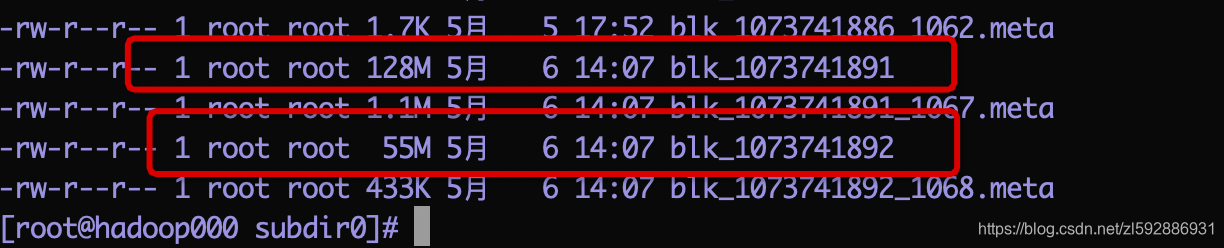
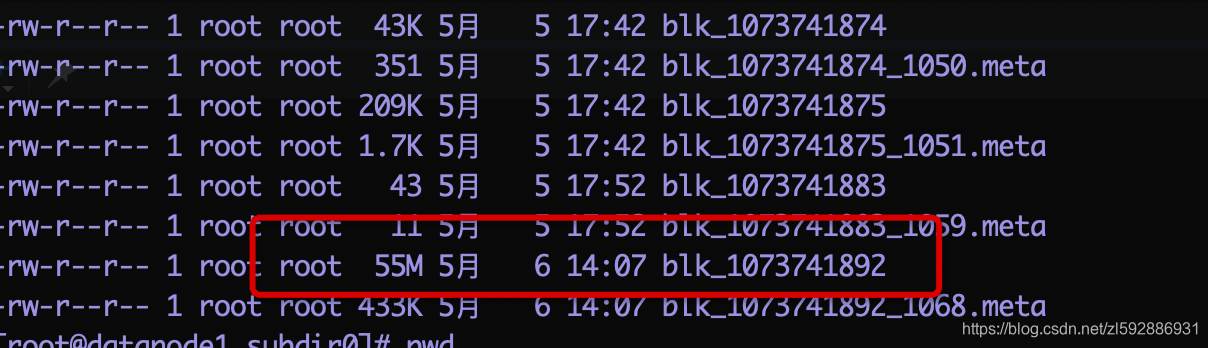
datanode1上面的存储为(只有一个55M的block):
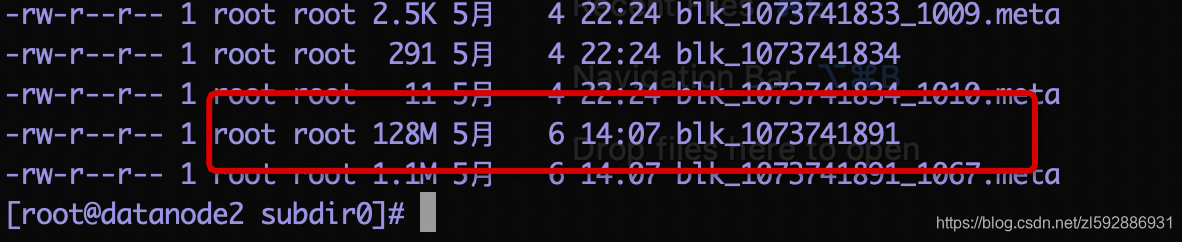
datanode2s上面存储为(有一个128M的block):
3.然后我们继续,将副本系数改为3,是否所有节点都存储完整数据:
这一次我们不删除数据,直接改变此文件的副本系数
hadoop fs -setrep -R 3 /data/jdk/jdk.tar.gz
然后查看结果,执行hadoop fs -ls /data/jdk,结果如下,果然副本系数变为3:
-rw-r--r-- 3 root supergroup 190875814 2019-05-06 14:07 /data/jdk/jdk.tar.gz
我们去刚才目录下再去看一下,所有节点均有次完整数据了:

4.查看当前hdfs的副本数
hadoop fsck -locations
某个文件的副本数,可以通过ls中的文件描述符看到
hadoop dfs -ls
如果你只有3个datanode,但是你却指定副本数为4,是不会生效的,因为每个datanode上只能存放一个副本