版权声明:君若不学,则何以成?本文为博主原创文章,欢迎转载(记得注明出处,拜托~)。 https://blog.csdn.net/hu_belif/article/details/83058798
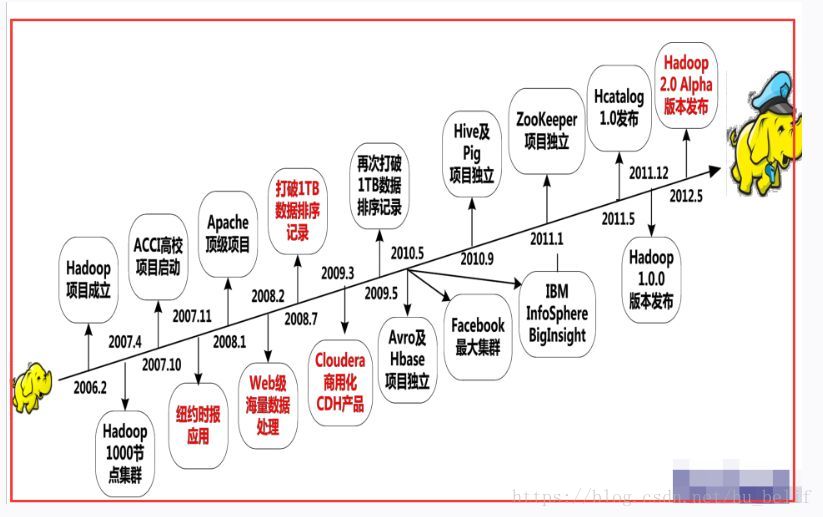
Hadoop的发展史:
生态圈图解:

MapReduce:分布式数据处理模型和执行环境、运行于大型商用机集群。
ZooKeeper:一个分布式、高可用的协调服务。ZooKeeper提供分布式锁之类的基本服务用于构建分布式应用。
HDFS: 分布式文件系统,运行于大型商用机集群。 Hadoop体系最底层的一个模块。为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。
HBase: 一个分布式、按列存储的数据库。HBase 使用 HDFS作为底层存储,同时支持 MapReduce 的批量式计算和点查询(随机读取)。
Pig:一种数据流语言和运行环境,用以检索非常大的数据集。Pig 运行在MapReduce 和 HDFS 的集群上。
Hive:一个分布式、按列存储的数据仓库。 Hive 管理 HDFS中存储的数据,并提供基于 SQL 的查询语言(由运行时引擎翻译成 MapReduce作业)用以查询数据。
Avro:支持高效、跨语言的 RPC以及永久存储数据的序列化实现,主要负责数据的序列化。
Mahout:一个可扩展的机器学习和数据挖掘
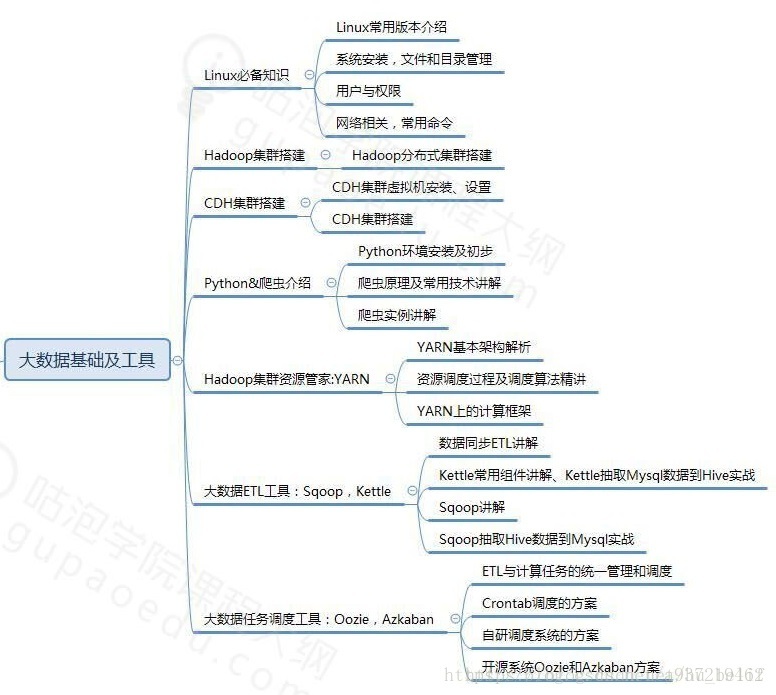
大数据必备的一些数据处理技术: