目录
一、Hadoop简介
hadoop = MapReduce+HDFS(hadoop 文件系统)
进一步解释:
MapReduce是一个项目,HDFS是另一个项目,他们组成了hadoop。
实际上这两个项目与hadoop关系 ,好比 hadoop是计算机,而MapReduce是CPU,而HDFS是硬盘。
显而易见了,MapReduce处理数据,HDFS存储数据。
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:
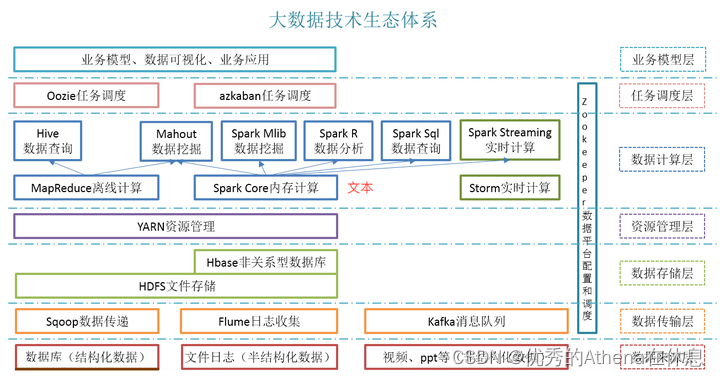

数据采集工具:
日志收集框架: Flume 、 Logstash 、 Filebeat
数据迁移工具: Sqoop
数据存储工具:
分布式文件存储系统: Hadoop HDFS
数据库系统: Mongodb 、 HBase
数据处理工具:
分布式计算框架:
批处理框架:Hadoop MapReduce
流处理框架:Storm
混合处理框架:Spark 、 Flink
查询分析框架 : Hive 、 Spark SQL 、 Flink SQL 、 Pig 、 Phoenix
资源和任务管理:集群资源管理器 : Hadoop YARN
分布式协调服务: Zookeeper
任务调度框架: Azkaban 、 Oozie
集群部署和监控: Ambari 、 Cloudera Manager
上面列出的都是比较主流的大数据框架,社区都很活跃,学习资源也比较丰富。从 Hadoop 开始入门学习,因为它是整个大数据生态圈的基石,其它框架都直接或者间接依赖于 Hadoop 。
二、Hadoop的运行模式
Hadoop可以按三种模式进行安装和运行。
1. 单机模式
(1)Hadoop的默认模式,安装时不需要修改配置文件。
(2)Hadoop运行在一台计算机上,不需要启动HDFS和YARN。
(3)MapReduce运行处理数据时只有一个JAVA进程,使用本地文件系统进行数据的输入输出。
(4)用于对MapReduce程序的逻辑进行调试,确保程序的正确。
2. 伪分布式模式
(1)Hadoop安装在一台计算机上,需要修改相应的配置文件,用一台计算机模拟多台主机的集群。
(2)需要启动HDFS和YARN ,是相互独立的Java进程。
(3)MapReduce运行处理数据时是每个作业一个独立进程,输入输出使用分布式文件系统。
(4)用来进行学习和开发测试Hadoop程序的执行是否正确。
3. 完全分布式模式
(1)在多台计算机上安装JDK和Hadoop ,组成相互连通的集群,需要修改相应的配置文件。
(2)Hadoop的守护进程运行在由多台主机搭建的集群上。真正的生产环境。
三、Hadoop生态圈组件
1. HDFS
HDFS是一个基于 java 的 Hadoop 分布式文件系统(Hadoop Distributed File System),是 Hadoop 生态系统中最重要的组成部分。HDFS 是 Hadoop 的主要存储系统,为大数据提供可扩展的、高容错的、可靠的和具有成本效益的数据存储。HDFS 被设计用来部署在低廉的硬件上,在许多安装中已经被设为默认配置。它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop 通过类似 shell 的命令与 HDFS 直接交互。
HDFS 有两个主要组件:NameNode 和 DataNode。
NameNode:NameNode 也被称为主节点,但它并不存储实际的数据或数据集。NameNode 存储的是元数据,即文件的权限、某一上传文件包含哪些 Block 块、Bolck 块保存在哪些 DataNode 上等细节信息。它由文件和目录组成。
NameNode 的任务:
- 管理文件系统的命名空间;
- 控制客户端对文件的访问;
- 操作文件命名空间的文件或目录操作,如打开,关闭,重命名等。
DataNode:DataNode 负责将实际数据存储在 HDFS 中,并负责来自文件系统客户的读写请求。在启动时,每个 Datanode 连接到其相应的 Namenode 并进行握手。命名空间ID 和 DataNode 的软件版本的验证是通过握手进行的。当发现不匹配时,DataNode 会自动关闭。
DataNode 的任务:
- DataNode 管理存储的数据。
- DataNode 同时还要执行块的创建、删除,以及来自 NameNode 的块复制指令。
2. MapReduce
MapReduce 是 Hadoop 生态系统的核心组件,提供数据处理。MapReduce 是一个软件框架,用于轻松编写应用程序,处理存储在 Hadoop 分布式文件系统中的大量结构化和非结构化数据。MapReduce 程序具有并行性质,因此对于使用集群的多台机器进行大规模数据分析非常有用,提高了计算速度和可靠性。MapReduce 的每个阶段都有键值对作为输入和输出。Map函数获取一组数据并将其转换为另一组数据,其中各个元素被分解为元组(键/值对)。函数将 Map 的输出作为输入,并根据键来组合这些数据元组,相应地修改键的值。
MapReduce的特点:
- 简单性:MapReduce 作业很容易运行。应用程序可以用任何语言编写,如 java、C++ 和 python。
- 可扩展性:MapReduce 可以处理 PB 级的数据。
- 速度:通过并行处理,需要几天才能解决的问题,通过 MapReduce 在几小时和几分钟内就能解决。
- 容错性:MapReduce 会照顾到故障。如果一份数据不可用,另一台机器有一份相同密钥对的副本,可以用来解决相同的子任务。
3. YARN
YARN(Yet Another Resource Negotiator)作为一个 Hadoop 生态系统的组件,它提供了资源管理。Yarn 也是 Hadoop 生态系统中最重要的组件之一。YARN 被称为 Hadoop 的操作系统,因为它负责管理和监控工作负载。它允许多个数据处理引擎(如实时流和批处理)来处理存储在一个平台上的数据。
- 灵活性:除了 MapReduce(批处理),还能实现其他专门的数据处理模式,如交互式和流式。由于 YARN 的这一特点,其他应用程序也可以在 Hadoop2 中与 MapReduce 程序一起运行。
- 效率:由于许多应用程序在同一个集群上运行,因此,Hadoop 的效率提高了,而对服务质量没有太大影响。
- 共享:提供一个稳定、可靠、安全的基础,并在多个工作负载中共享操作服务。
除了基本模块,Hadoop还包括以下项目:
4. Hive
Apache Hive是一个开源的数据仓库系统,用于查询和分析存储在 Hadoop 文件中的大型数据集。Hive主要做三个功能:数据汇总、查询和分析。Hive 使用的语言称为 HiveQL(HQL),与SQL类似。HiveQL 自动将类似 SQL 的查询翻译成 MapReduce 作业,并在Hadoop上执行。
Hive 的主要部分:
- Metastore:元数据存储。
- 驱动:管理 HiveQL 语句的生命周期。
- 查询编译器:将 HiveQL 编译成有向无环图(DAG)。
- Hive 服务器:提供一个 Thrift 接口和 JDBC / ODBC 服务器。
5. Pig
Apache Pig 是一个高级语言平台,用于分析和查询存储在 HDFS 中的巨大数据集。Pig 作为 Hadoop 生态系统的一个组成部分,使用 PigLatin 语言,它与 SQL 非常相似。它的任务包括加载数据,应用所需的过滤器并以所需的格式转储数据。对于程序的执行,Pig 需要 Java 运行环境。
Apache Pig 的特点:
- 可扩展性:为了进行特殊的处理,用户可以创建自己的功能。
- 优化机会:Pig 允许系统自动执行优化,这使得用户可以关注语义而不是效率。
- 处理所有种类的数据:Pig 既能分析结构化的数据,也能分析非结构化的数据。
6. HBase
Apache HBase 是 Hadoop 生态系统的一个组成部分,它是一个分布式数据库,被设计用来在可能有数十亿行和数百万列的表中存储结构化数据。HBase 是一个建立在 HDFS 之上,可扩展的、分布式的 NoSQL 数据库。HBase 提供实时访问 HDFS 中的数据的读取或写入。
HBase 有两个组件,即 HBase Master 和 RegionServer。
HBase Master
- 它不是实际数据存储的一部分,但在所有 RegionServer 之间协商负载平衡。
- 维护和监控 Hadoop 集群。
- 执行管理(创建、更新和删除表的界面)。
- 控制故障转移。
- 处理DDL操作。
RegionServer
- 处理来自客户端的读、写、更新、删除请求。
- RegionServer 进程在 Hadoop 集群的每个节点上运行。RegionServer 运行在 HDFS 的 DateNode 上。
7. HCatalog
HCatalog 是 Hadoop 的一个表和存储管理层。HCatalog 支持 Hadoop 生态系统中的不同组件,如MapReduce、Hive 和 Pig,以方便从集群中读写数据。HCatalog 是 Hive的一个关键组件,使用户能够以任何格式和结构存储他们的数据。默认情况下,HCatalog 支持 RCFile、CSV、JSON、sequenceFile 和 ORC 文件格式。
8. Avro
Acro 是 Hadoop 生态系统的一部分,是一个最流行的数据序列化系统,为 Hadoop 提供数据序列化和数据交换服务。这些服务可以一起使用,也可以独立使用。大数据可以使用 Avro 交换用不同语言编写的程序。使用序列化服务,程序可以将数据序列化为文件或消息。它将数据定义和数据一起存储在一个消息或文件中,使得程序可以很容易地动态理解存储在 Avro 文件或消息中的信息。
- Avro 模式:它依靠模式进行序列化 / 反序列化。Avro 需要模式来进行数据的写入 / 读取。当 Avro 数据存储在一个文件中时,它的模式也随之存储。因此,文件可以在以后被任何程序处理。
- 动态类型化:它指的是在不生成代码的情况下进行序列化和反序列化。它是对代码生成的补充,在 Avro 中,静态类型的语言可以作为一种可选的优化。
9. Thrift
Thrift 是一个用于可扩展的跨语言服务开发的软件框架,同时是一种用于 RPC(远程程序调用)通信的接口定义语言。Hadoop 做了大量的 RPC 调用,因此有可能出于性能或其他原因使用 Thrift。
10. Drill
Hadoop 生态系统组件的主要目的是大规模数据处理,包括结构化和半结构化数据。Apache Drill 是一个低延迟的分布式查询引擎,旨在扩展到几千个节点并查询 PB 级的数据。Drill 是第一个具有无模式模型的分布式 SQL 查询引擎。
Drill有专门的内存管理系统,可以消除垃圾回收,优化内存分配和使用。Drill 与 Hive 发挥得很好,允许开发者重用他们现有的 Hive 部署。
- 可扩展性:Drill 在各层提供可扩展的架构,包括查询层、查询优化和客户端 API。我们可以根据企业的具体需求来扩展任何一层。
- 灵活性:Drill 提供了一个分层的列式数据模型,可以表示复杂的、高度动态的数据,并允许高效的处理。
- 动态模式发现:Drill 不要求数据的模式或类型规范,以便开始查询执行过程。相反,Drill 以称为记录批次的单位开始处理数据,并在处理过程中即时发现模式。
- Drill 分散的元数据:与其他 SQL Hadoop 技术不同,Drill 没有集中的元数据要求。Drill 用户不需要为了查询数据而在元数据中创建和管理表。
11. Mahout
Apache Mahout 是用于创建可扩展的机器学习算法和数据挖掘库的开源框架。一旦数据被存储在 HDFS 中,Mahout 提供了数据科学工具来自动寻找这些大数据集中有意义的模式。
Mahout的算法包括:
- 聚类
- 协同过滤
- 分类
- 频繁模式挖掘
12. Sqoop
Apache Sqoop 将数据从外部来源导入相关的 Hadoop 生态系统组件,如 HDFS、Hbase 或 Hive。它还可以将数据从 Hadoop 导出到其他外部来源。Sqoop 与关系型数据库一起工作,如 teradata、Netezza、oracle、MySQL。
Apache Sqoop的特点:
- 从大型机导入顺序数据集:Sqoop 满足了将数据从大型机转移到 HDFS 的日益增长的需求。
- 直接导入 ORC 文件:改善压缩和轻量级索引,提高查询性能。
- 平行数据传输:实现更快的性能和最佳的系统利用率。
- 高效的数据分析:通过将结构化数据和非结构化数据结合在读取数据湖的模式上,提高数据分析的效率。
- 快速的数据拷贝:从外部系统到 Hadoop。
13. Flume
Apache Flume 有效地收集、汇总和移动大量的数据,并将其从原点送回 HDFS。它是容错和可靠的机制。Flume 允许数据从源头流入 Hadoop 环境。它使用一个简单的可扩展的数据模型,允许在线分析应用。使用 Flume,我们可以从多个服务器立即获得数据到 Hadoop。
14. Ambari
Ambari 是一个用于配置、管理、监控和保护 apache Hadoop 集群的管理平台。由于 Ambari 提供了一致的、安全的操作控制平台,Hadoop 管理变得更加简单。
Ambari的特点:
- 简化安装、配置和管理:Ambari 轻松有效地创建和管理大规模的集群。
- 集中的安全设置:Ambari 减少了在整个平台上管理和配置集群安全的复杂性。
- 高度的可扩展性和可定制性:Ambari 具有高度的可扩展性,可将定制服务纳入管理。
- 对集群健康的全面可视性:Ambari通过整体的监控方法,确保集群的健康和可用。
15. Zookeeper
Apache Zookeeper 用于维护配置信息、命名、提供分布式同步和提供组服务。Zookeeper 管理和协调一个大型的机器集群。
Zookeeper的特点
- 快速:Zookeeper 在对数据的读取比写入更常见的工作负载中是快速的。理想的读 / 写比率是 10:1。
- 有序:Zookeeper 维护所有事务的记录。
四、Hadoop优缺点
基于Hadoop开发出来的大数据平台,通常具有以下特点:
- 扩容能力:能够可靠地存储和处理PB级的数据。Hadoop生态基本采用HDFS作为存储组件,吞吐量高、稳定可靠。
- 成本低:可以利用廉价、通用的机器组成的服务器群分发、处理数据。这些服务器群总计可达数千个节点。
- 高效率:通过分发数据,Hadoop可以在数据所在节点上并行处理,处理速度非常快。
- 可靠性:Hadoop能自动维护数据的多份备份,并且在任务失败后能自动重新部署计算任务。
Hadoop生态缺点:
- 因为Hadoop采用文件存储系统,所以读写时效性较差,至今没有一款既支持快速更新又支持高效查询的组件。
- Hadoop生态系统日趋复杂,组件之间的兼容性差,安装和维护比较困难。
- Hadoop各个组件功能相对单一,优点很明显,缺点也很明显。
- 云生态对Hadoop的冲击十分明显,云厂商定制化组件导致版本分歧进一步扩大,无法形成合力。
- 整体生态基于Java开发,容错性较差,可用性不高,组件容易挂掉。
五、Hadoop学习路径
(一)平台基础
1.1 大数据
了解什么是大数据,大数据入门,以及大数据介绍。
以及大数据中存在的问题,包括存储,计算的问题,有哪些解决策略。
1.2 Hadoop平台生态圈
熟悉了解开源Hadoop平台生态圈,以及第三方大数据平台,查找一些Hadoop入门介绍博客或者官网,了解:
What’s Hadoop
Why Hadoop exists
How to Use Hadoop
1.3 Hadoop家族成员
Hadoop是一个庞大的家族,包含存储,计算等一系列产品组件,需要了解其中的一系列组件,包括HDFS,MapReduce,Yarn,Hive,HBase,ZooKeeper,Flume,Kafka,Sqoop,HUE,Phoenix,Impala,Pig,Oozie,Spark等,知道其干什么,维基百科定义。
1.4 HDFS
分布式存储HDFS,了解HDFS架构,HDFS的存储机制,各节点协作关系需理解清楚。
1.5 Yarn
分布式资源管理Yarn,熟悉Yarn架构,以及如何进行资源管理的机制。
1.6 MapReduce
分布式计算MapReduce,对MapReduce底层架构,处理方案进行了解,计算架构方案,了解MapReduce计算的优势,以及劣势。
1.7 HBase
大数据高效存储HBase,了解HBase底层架构,HBase的应用场景,存储方案。
1.8 Hive
大数据仓库Hive,了解Hive的存储机制,Hive的事务型变迁,Hive的应用场景,以及Hive底层计算。
1.9 Spark
内存计算平台Spark,熟悉Spark内存计算架构,计算流程,Spark的运行模式,以及应用场景。
(二)平台进阶
2.1 HDFS
通过命令行操作HDFS,文件查看,上传,下载,修改文件,赋权限等。
通过java demo连接操作HDFS,实现文件读取,上传,下载功能。
通过DI工具,配置HDFS操作流程,实现关系型数据库文件到HDFS存储,HDFS文件保存到本地目录中。
2.2 MapReduce
Eclipse绑定Hadoop环境,添加MapReduce Location,用eclipse运行MapReduce的经典实例WordCount,看其中原理,尝试修改为中文词汇统计,并排除不相关词汇。
2.3 Hive
通过命令行操作Hive,进行beeline连接,SQL语句操作Hive数据仓库。
通过java demo连接操作Hive,实现建表,插入数据,查询,删除数据记录,更新数据,删除表等操作。
通过DI工具,配置关系型数据库抽取到Hive事务表流程,不通过直接驱动连接Hive,通过HDFS以及Hive外表进行过度实现。
2.4 HBase
在命令行中访问操作使用HBase,建立列族,每列添加数据,修改更新数据查看变化。
通过java demo,用phoenix驱动,连接HBASE,实现对HBASE的建表,增删改查数据操作。
DI工具需要修改源码,或者添加phoenix组件,才能使用,因为phoenix插入语句不是Insert into,而是Upsert into,无法与DI工具匹配。
2.5 Spark
在命令行中,运行pyspark,以及spark shell,进行spark命令行操作,提交spark示例任务,进行试运行。
切换Spark运行模式,进行命令行尝试体验。
通过java demo连接Spark,进行任务的分发计算运行。
(三)平台高级
针对上述组件,进行熟练使用,熟能生巧,举一反三,能够根据场景编写MapReduce代码,Spark代码等,针对Hive,HBase深入理解支持的SQL类型,存储过程,触发器等如何进行操作,能够根据需求设计最优的解决方案。
(四)平台深度
深读组件源码,理解平台部署中各个配置的意义及影响,以及如何通过源码以及配置对组件进行优化,修改源码提高Hadoop平台的容错性,扩展性,稳定性等。
参考文献: