 Hadoop的核心组件是HDFS、MapReduce。
Hadoop的核心组件是HDFS、MapReduce。
Hadoop百度百科
Hadoop是一个的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
Hadoop举例
Hadoop是一个开源的大数据框架,是一个分布式计算的解决方案。
Hadoop的两个核心解决了数据存储问题(HDFS分布式文件系统)和分布式计算问题(MapRe-duce)。
举例1 用户想要获取某个路径的数据,数据存放在很多的机器上,作为用户不用考虑在哪台机器上,HD-FS自动搞定。
举例2 如果一个100p的文件,希望过滤出含有Hadoop字符串的行。这种场景下,HDFS分布式存储,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,同时MapReduce分布式计算可以将大数据量的作业先分片计算,最后汇总输出。
怎么使用Hadoop
1、Hadoop集群的搭建
无论是在windows上装几台虚拟机玩Hadoop,还是真实的服务器来玩,说简单点就是把Hadoop的安装包放在每一台服务器上,改改配置,启动就完成了Hadoop集群的搭建。
2、上传文件到Hadoop集群
Hadoop集群搭建好以后,可以通过web页面查看集群的情况,还可以通过Hadoop命令来上传文件到hdfs集群,通过Hadoop命令在hdfs集群上建立目录,通过Hadoop命令删除集群上的文件等等。
3、编写map/reduce程序通过集成开发工具(例如eclipse)导入Hadoop相关的jar包编写map/reduce程序,将程序打成jar包扔在集群上执行,运行后出计算结果。
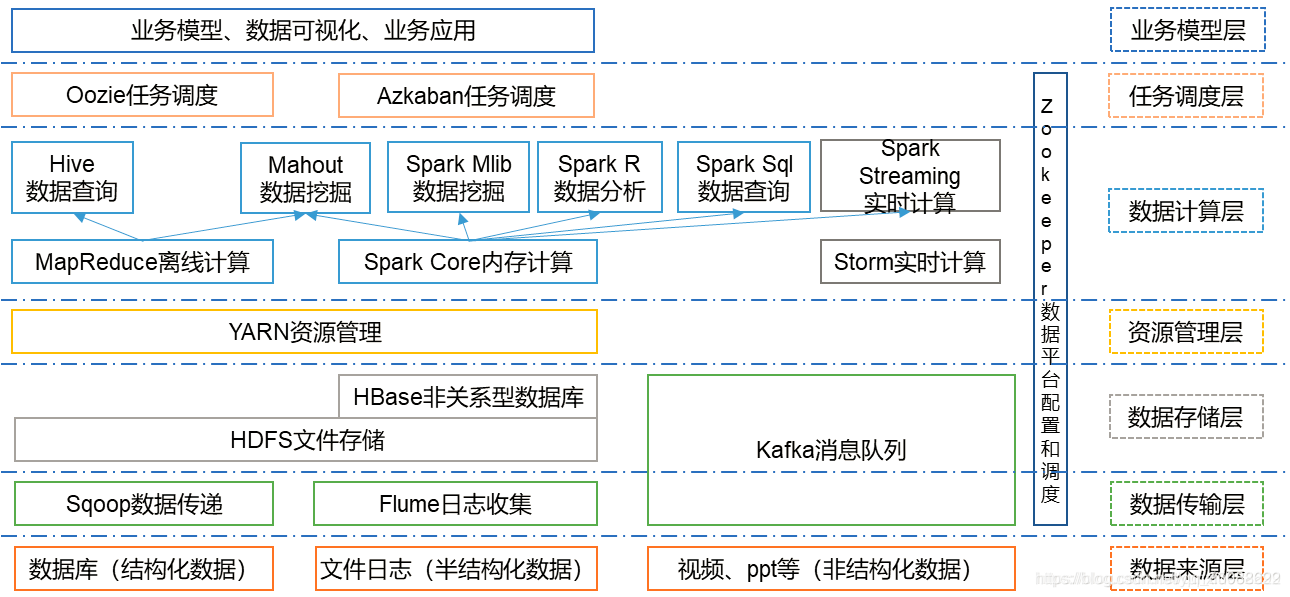
1、HDFS
HDFS是整个hadoop体系的基础,负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
2、MapReduce(分布式计算框架)
MapReduce是一种基于磁盘的分布式并行批处理计算模型,用于处理大数据量的计算。其中Map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,Reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
3、Spark(分布式计算框架)
Spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
4、Hive/Impala(基于Hadoop的数据仓库)
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。因此执行效率高于Apache Hive。
5、HBase(分布式列存储数据库)
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
要掌握的技能
语言基础
Java:掌握javase知识,多理解和实践在Java虚拟机的内存管理、以及多线程、线程池、设计模式、并行化就可以,不需要深入掌握。
Hadoop本身是用java开发的,所以对java的支持性非常好,但也可以使用其他语言。
Linux:系统安装(命令行界面和图形界面)、基本命令、网络配置、Vim编辑器、进程管理、Shell脚本、虚拟机的菜单熟悉等等。
因为Hadoop是运行在Linux系统上的,所以还需要掌握Linux的知识。
Python:基础语法,数据结构,函数,条件判断,循环等基础知识。
下面的技术路线侧重数据挖掘方向,因为Python开发效率较高所以我们使用Python来进行任务。
环境准备
这里介绍在windows电脑搭建完全分布式,1主2从。
VMware虚拟机、Linux系统(Centos6.5)、Hadoop安装包,这里准备好Hadoop完全分布式集群环境。
MapReduce
MapReduce分布式离线计算框架,是Hadoop核心编程模型。主要适用于大批量的集群任务,由于是批量执行,故时效性偏低。
HDFS1.0/2.0
Hadoop分布式文件系统(HDFS)是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
Hive
Hive是一个数据仓库,所有的数据都是存储在HDFS上的。使用Hive主要是写Hql,非常类似于Mysql数据库的Sql。其实Hive在执行Hql,底层在执行的时候还是执行的MapRedce程序。
Spark
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,其是基于内存的迭代式计算。Spark 保留了MapReduce 的优点,而且在时效性上有了很大提高。
Spark Streaming
Spark Streaming是实时处理框架,数据是一批一批的处理。
Spark Hive
基于Spark的快速Sql检索。Spark作为Hive的计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算,可以提高Hive查询的性能。
Hbase
Hbase是一个Nosql 数据库,是一个Key-Value类型的数据库,是高可靠、面向列的、可伸缩的、分布式的数据库。
适用于非结构化的数据存储,底层的数据存储在HDFS上。
第二阶段:数据挖掘算法
1.中文分词:
开源分词库的离线和在线应用
2.自然语言处理:
文本相关性算法
3.推荐算法:
基于CB、CF,归一法,Mahout应用。
4.分类算法:
NB、SVM
5.回归算法:
LR、Decision Tree
6.聚类算法:
层次聚类、Kmeans
7.神经网络与深度学习:
NN、Tensorflow
Hadoop到底是干什么用的