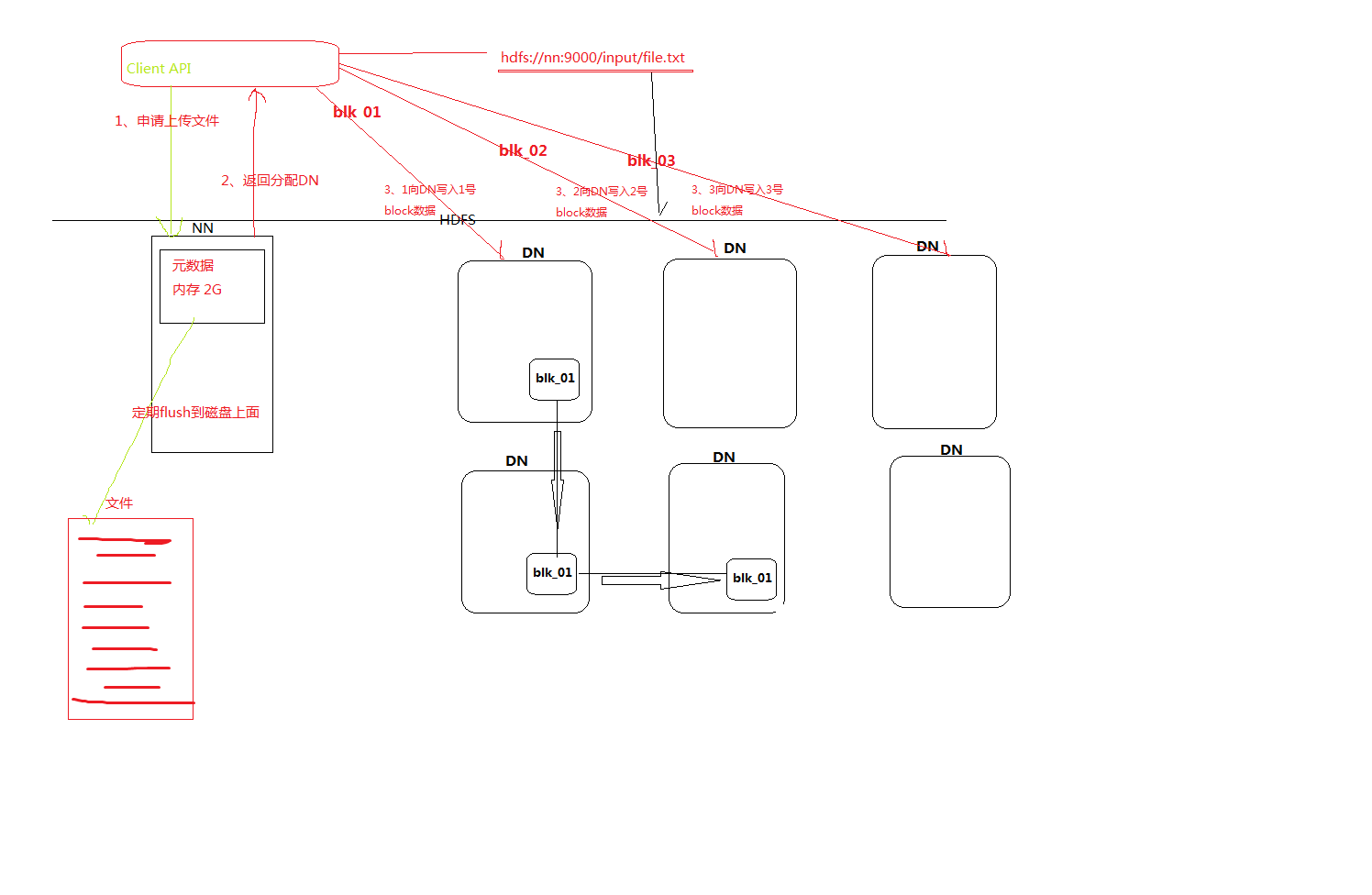
1、HDFS架构原理图
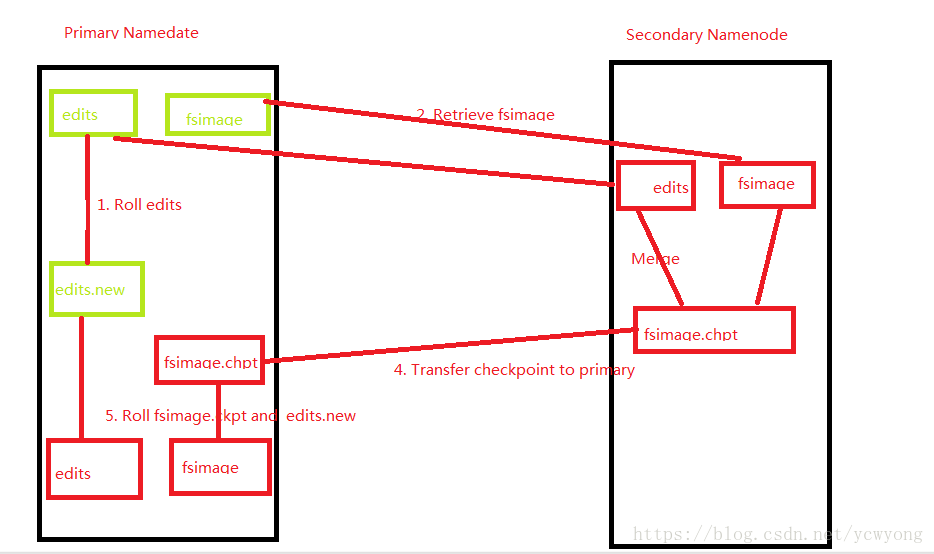
Secondary Namenode流程图
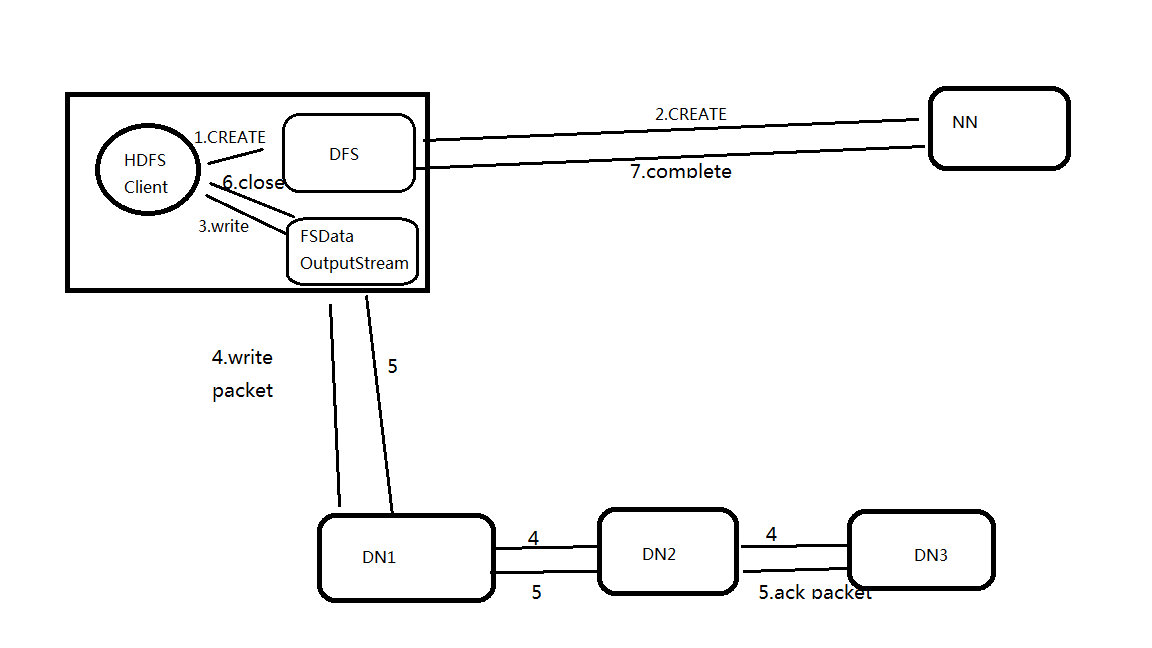
HDFS写流程
官方HDFS架构图
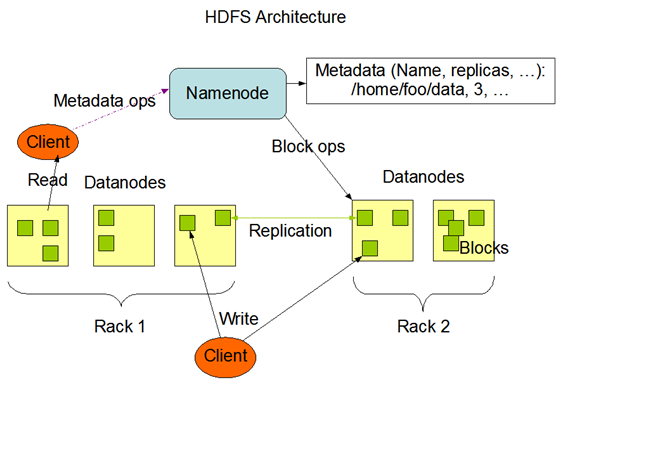
副本存放策略

各个组件概念和作业
Namenode:
存储:文件系统的命名空间
- a.文件名称;
- b.文件目录结构;
- c.文件的属性[权限,创建时间,副本数];
- d.文件对应哪些数据块-->数据块对应哪些datanode节点
- [blockmap当然namenode节点不会持久的存储这种映射关系,是通过集群在启动和运时,datanode 定期发送blockReport给namenode,以此namenode在内存中来动态维护的这种 映射关系]
作用:
管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。
这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件fsimage和编辑日志文件editlog。
Datanode:
存储:数据块和数据块校验和与Namenode通信:
- a.每隔3秒发送一个心跳包
- b.每十次心跳发送一次blockReport.
作用(主要):读写文件的数据块
Scondarynode:
存储:fsimage+editlog
作用:定期合并fsimage+editlog文件为新的fsimage 推送给namenode.俗称检查点动作,checkpoint.
参数:fs.checkpoint.period-->1h fs.checkpoint.size -->64M
2、hadoop MapReduce YARN体系
MapReduce 1.x
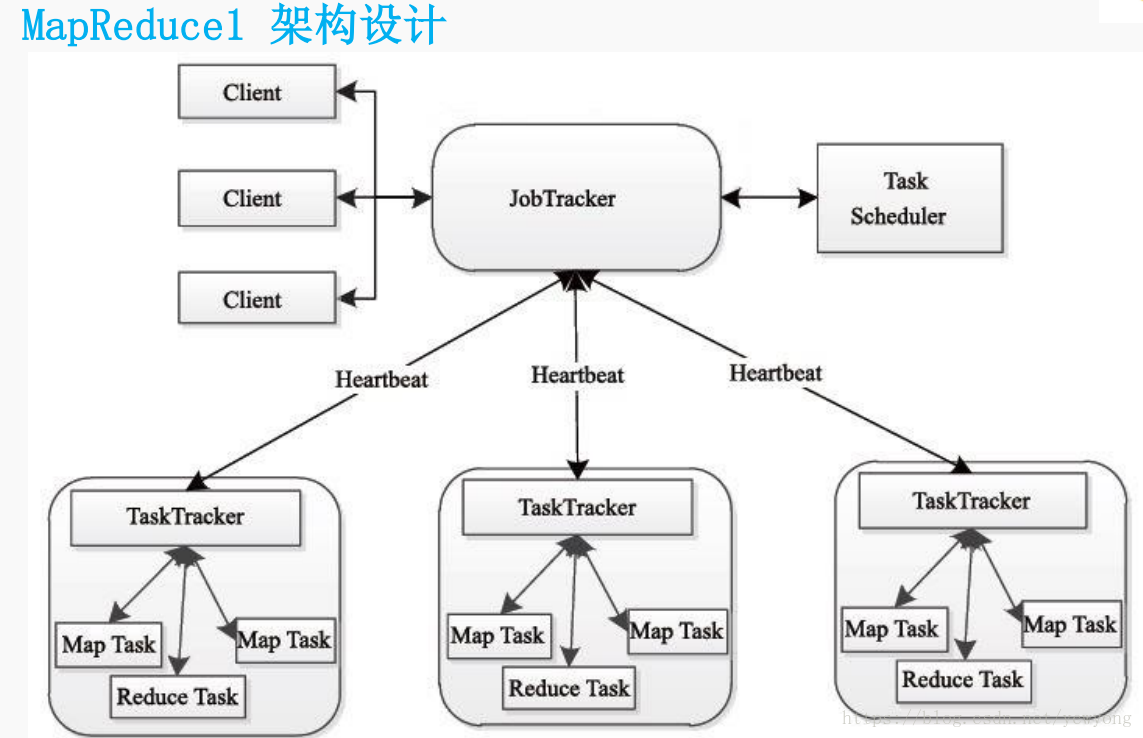
MR1是hadoop1.x中作为计算和资源调度使用,
含有JobTracke TaskTracke 作为计算
map task
reduce taskMapReduce 2.x
YARN工作流程(mr提交应用程序)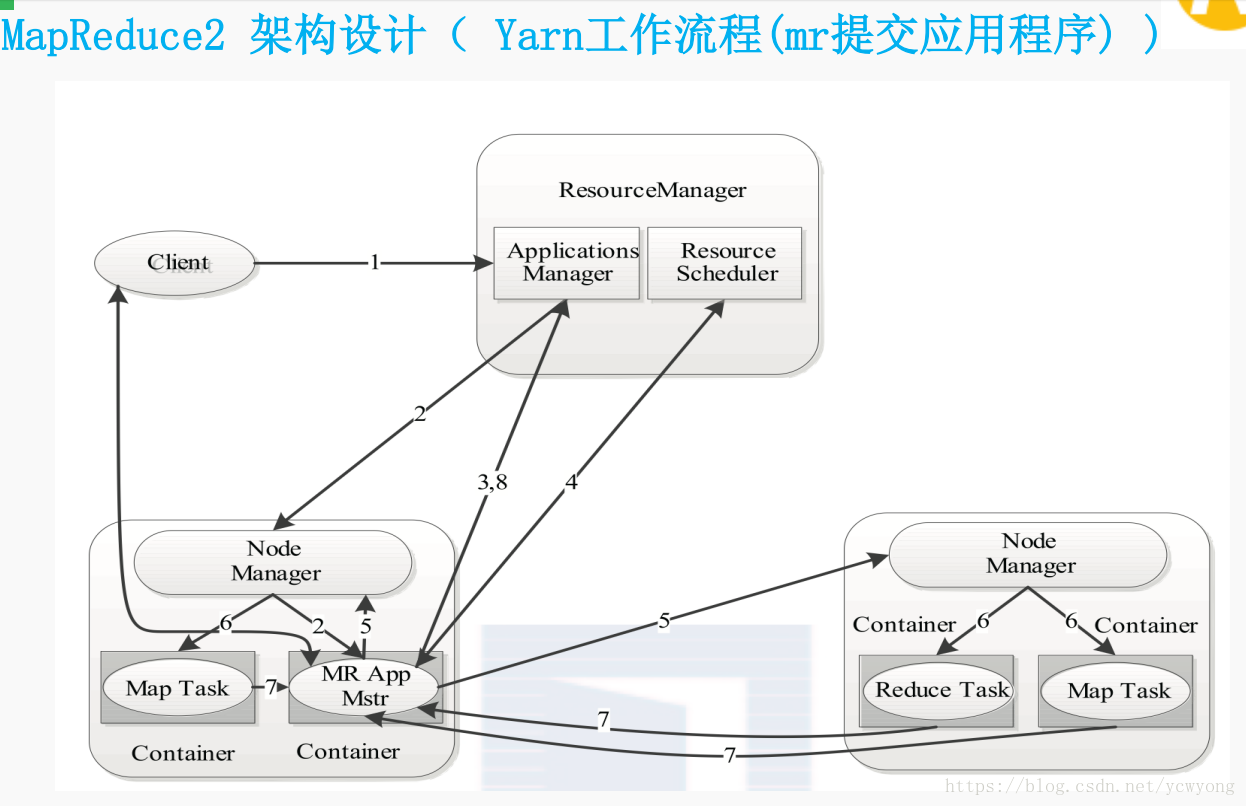
1:用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
2:ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
3:ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后
它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
4:ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
5:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
6:NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通
过运行该脚本启动任务。
7:各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行
状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序
的当前运行状态。
8:应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己
Yarn的基本思想是拆分资源管理的功能,作业调度/监控到单独的守护进程
ApplicationMaster 每一个job有一个ApplicationMaster
NodeManager,NodeManager是基本的计算框架 NodeManager节点,包含Container(运行任务容器)
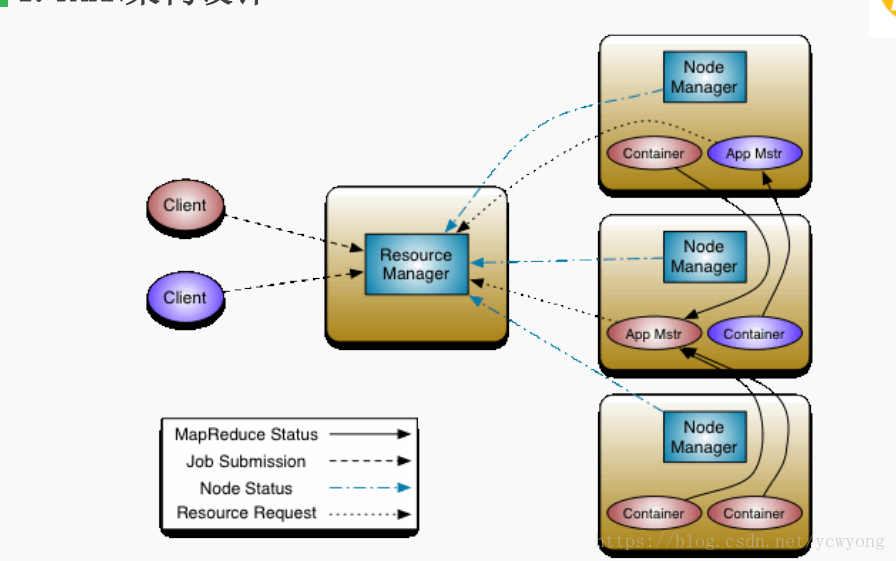
角色
ResourceManager(RM):
主要接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,
负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
ResourceManager(RM):
负责对各NM上的资源进行统一管理和调度。将AM分配空闲的Container运行并监控其运行状态。
对AM申请的资源请求分配相应的空闲Container。主要由两个组件构成:调度器和应用程序管理器。
调度器(Scheduler):
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系
统中的资源分配给各个正在运行的应用程序。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位是
Container,从而限定每个任务使用的资源量。Shceduler不负责监控或者跟踪应用程序的状态,也不负责任务因为各种原 因而需要的重启(由ApplicationMaster负责)。总之,调度器根据应用程序的资源要求,以及集群机器的资源情况,为应用程序 分配封装在Container中的资源。
调度器是可插拔的,例如CapacityScheduler、FairScheduler。
应用程序管理器(Applications Manager):
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器
协商资源以启动AM、监控AM运行状态并在失败时重新启动等,跟踪分给的Container的进度、状态也是其职责。
NodeManager (NM):
NM是每个节点上的资源和任务管理器。它会定时地向RM汇报本节点上的资源使用情况和各个Container的
运行状态;同时会接收并处理来自AM的Container 启动/停止等请求。
ApplicationMaster (AM):
用户提交的应用程序均包含一个AM,负责应用的监控,跟踪应用执行状态,重启失败任务等。
ApplicationMaster是应用框架,它负责向ResourceManager协调资源,并且与NodeManager协同工作完成Task的执行和监控。
MapReduce就是原生支持的一种框架,可以在YARN上运行Mapreduce作业。有很多分布式应用都开发了对应的应用程序框架,用
于在YARN上运行任务,例如Spark,Storm等。如果需要,我们也可以自己写一个符合规范的YARN application。
Container:
是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,
RM为AM返回的资源便是用Container 表示的。 YARN会为每个任务分配一个Container且该任务只能使用该Container中
描述的资源。