在“DNA核苷酸含量”中,我们描述了核酸作为核苷酸单元聚合物的一级结构,并且我们提到广泛存在的DNA由四个碱基的不同序列组成。
然而除了DNA外,染色质还有一种核酸和DNA一起存在;这种核酸具有不同的糖,称为核糖(ribose),后来被称为核糖核酸或RNA。RNA与DNA的不同之处在于它含有称为尿嘧啶(uracil)的碱基代替胸腺嘧啶; DNA和RNA之间的结构差异如图1所示。生物学家最初认为RNA仅包含在植物细胞中,而DNA仅限于动物细胞。然而,随着新的化学方法的提出,在地球上所有生命形式的细胞中发现了两种核酸,这一假设消失了。
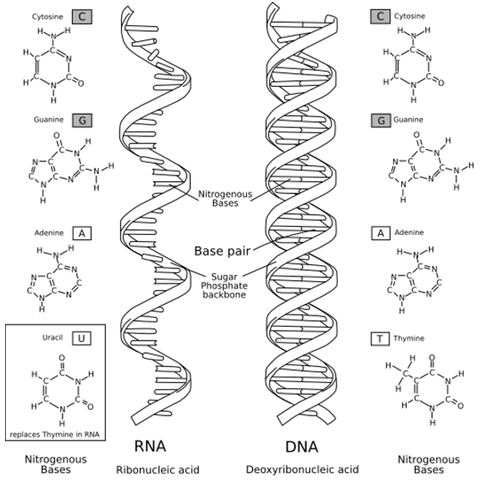
图1. RNA和DNA之间的结构差异
DNA和RNA的主要结构是如此相似,因为前者是创建信使RNA(mRNA)这种特殊RNA分子的蓝图。mRNA在RNA转录期间产生,在此期间,DNA的链用作构建RNA链的模板,通过一次复制一个核苷酸,其中使用尿嘧啶代替胸腺嘧啶。
在真核生物中,DNA主要存在于细胞核中,而RNA可以存在于细胞任意位置以执行DNA的命令。在以后的问题中,我们将更详细地研究RNA转录的过程和分枝。
RNA转录
RNA转录定义了DNA转化为RNA的过程。在真核生物中,RNA转录发生在细胞核中。如图2所示,RNA聚合酶(RNAP)通过遍历DNA的一条链(在3'-5'方向)促进转录,这里的DNA称为模板链。在每个连续的碱基处,RNAP将互补碱基添加到RNA的合成链中,其中尿嘧啶取代胸腺嘧啶。因为产生的RNA链(称为前mRNA)是在互补性上构建的,所以它与相反的DNA链相同(除了用尿嘧啶替代胸腺嘧啶)。因此,第二条DNA链称为编码链,因为即使在转录过程中不使用它,编码链也与前mRNA链相同,除了用尿嘧啶取代胸腺嘧啶。

图2. RNA转录过程
问题
通过以上介绍我们知道了RNA串是由包含'A','C','G'和'U'的字母组成的字符串。
给定对应于编码链的DNA串t,其转录的RNA串u通过用u中的'U'替换t中所有出现的'T'而形成。
Given: 一段DNA序列t
Return: t转录后的RNA序列
样本数据
GATGGAACTTGACTACGTAAATT
样本输出
GAUGGAACUUGACUACGUAAAUU
分析
这个问题很简单:只需读取字符串然后将T替换成U即可。在这里我提供两种方法来解决这个问题。
python
我们可以使用python的一个内置函数str.replace()来解决,查看该函数的文档我们可以得到:
replace(...)
S.replace(old, new[, count]) -> str
因此我们定义一个函数:
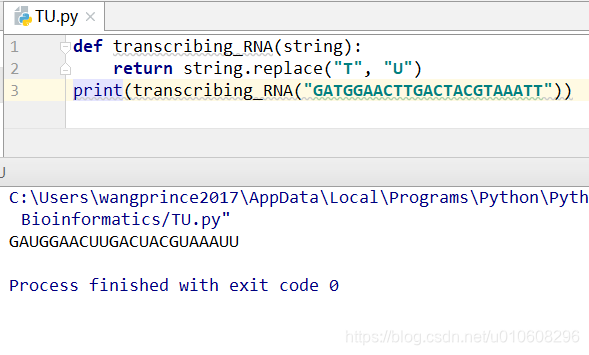
def transcribing_RNA(string):
return string.replace("T", "U")
In [1]:
print(transcribing_RNA("GATGGAACTTGACTACGTAAATT"))
Out[1]:
GAUGGAACUUGACUACGUAAAUU
bash
我们可以直接在bash中解决上面这个问题。我们使用tr这个命令,在bash下查看这个命令的文档我们可以得到:
NAME
tr - translate or delete characters
SYNOPSIS
tr [OPTION]... SET1 [SET2]
DESCRIPTION
Translate, squeeze, and/or delete characters from standard input, writing to standard output.
根据文档描述,这个命令的功能是翻译字符,也就是说可以根据单个字符或字符集进行替换。
In [1]:
tr T U < sample_dna_seq.txt
Out[1]:
GAUGGAACUUGACUACGUAAAUU