爬取网页
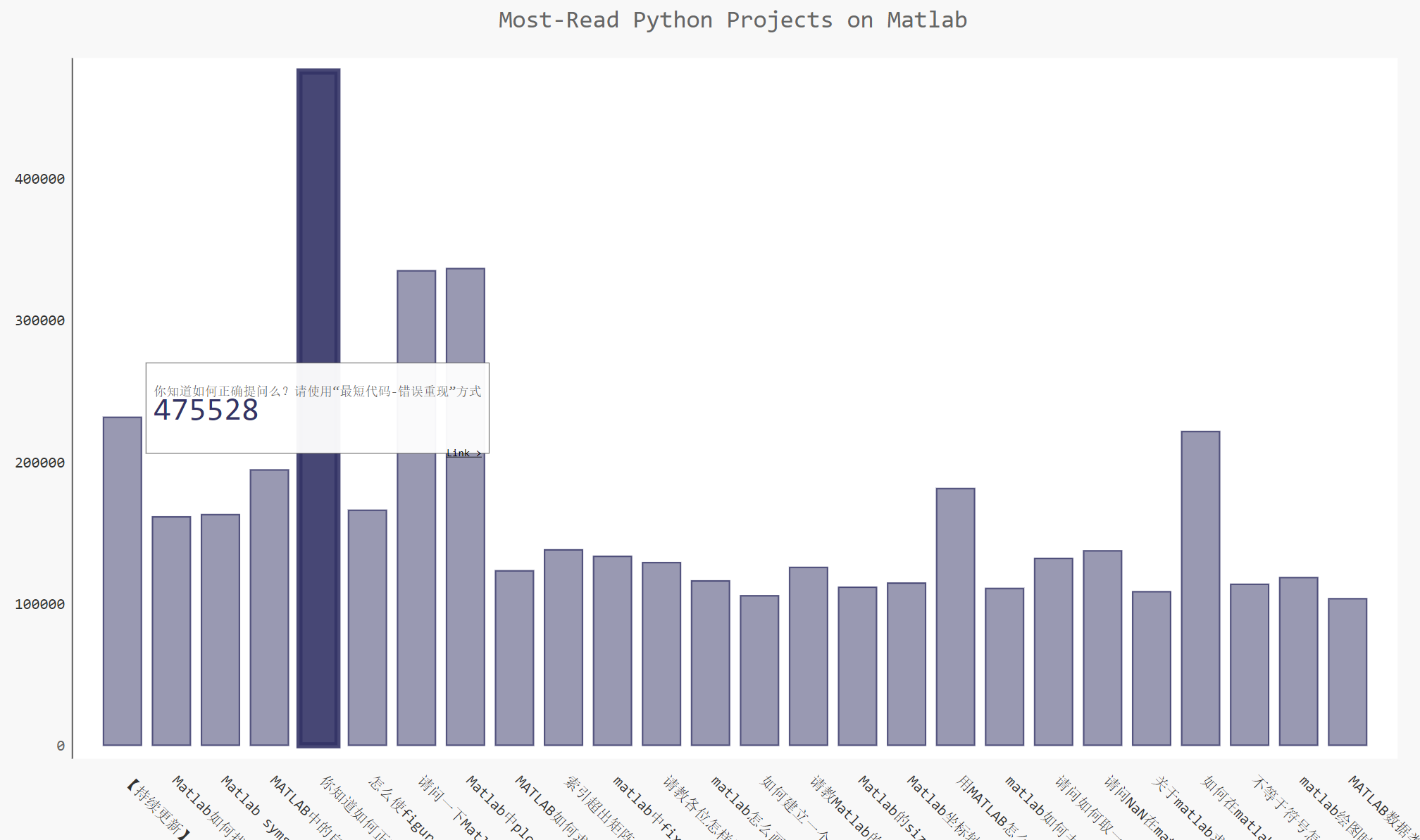
以MATLAB中文论坛–MATLAB 基础讨论 为例,进行页面信息提取,主要提取页面内问题,问题的阅读量以及问题链接,汇总阅读量大于100000的图。
解析网页信息,主要的提取代码为:
<a href="thread-568443-1-1.html" onclick="atarget(this)" class="s xst">小白求问函数求导问题</a>
工具
python
利用Python语言进行编程爬取网页的内容。
beautifulsoup
用beautifulsoup包进行解析网页。
完整代码
// An highlighted block
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 9 19:39:29 201
@author: 12101
"""
from bs4 import BeautifulSoup
import requests
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
# 得到每页的数据 urls 网页源
def get_titles(urls,data = None):
print(urls)
try:
web_data = requests.get(urls)
soup = BeautifulSoup(web_data.text, 'lxml')
souptitle=soup.find_all("a",class_='s xst')
soupnum=soup.find_all("a",class_='xi2')
for i in range(0,len(souptitle)):
link.append(souptitle[i]['href'])
for title in souptitle:
Title.append(title.get_text())
for num in soupnum:
nextSib=num.find_next_siblings('em')
if (len(nextSib)==1):
Nums.append(int(nextSib[0].get_text()))
return Title,Nums,link
except:
return "Someting is Wrong!
# 得到绘图的数据 Title 标题 Nums 数量 link 链接
def getplotdata(Title,Nums,link):
for i in range(0,len(Title)):
plot_dirt={
"value":Nums[i],
"lable":Title[i],
"xlink":'http://www.ilovematlab.cn/' + link[i],
}
plot_dirts.append(plot_dirt)
return plot_dirts
# 绘图操作定义 Plot_dirt 绘图数据字典 Title 横坐标标题
def Plot_dirt(name,Plot_dirt,Title):
my_style = LS('#333366', base_style=LCS)
# 定义类型
my_config = pygal.Config()
my_config.x_label_rotation = 45
my_config.show_legend = False
my_config.title_font_size = 24
my_config.label_font_size = 14
my_config.major_label_font_size = 18
my_config.truncate_label = 15
my_config.show_y_guides = False
my_config.width = 1000
chart1 = pygal.Bar(my_config, style=my_style)
chart1.title = 'Most-Read Python Projects on Matlab'
chart1.x_labels = Title
chart1.add('',Plot_dirt)
chart1.render_to_file(name)
# 输出文件 定义样式 name 文件名 title 标题 num 阅读量 link 链接
def Output_data(name,title,num,link,temp):
filename = name
with open(filename,'w',encoding='utf-8') as file_object:
if temp==1:
for i in range(0,len(title)):
file_object.write(title[i] + "\t" + str(num[i]) + "\t" + 'http://www.ilovematlab.cn/' + link[i] + "\n")
else:
for i in range(0,len(title)):
file_object.write(title[i] + "\t" + str(num[i]) + "\t" + link[i] + "\n")
Title,Nums,plot_dirts,plot_All,plot_numer,plot_title,link,plot_link=[],[],[],[],[],[],[],[]
MaxReadNum=200000
urls = ['http://www.ilovematlab.cn/forum-6-{}.html'.format(str(i)) for i in range(1,1001)]
for url in urls:
get_titles(url)
# 输出所有网页的数据 标题 阅读量 链接
Output_data('outputall.txt',Title,Nums,link,1)
# 对得到的绘图数据进行字典处理
getplotdata(Title,Nums,link)
# 处理得到的数据,将大于MaxReadNum的数据提取出来
for i in range(0,len(plot_dirts)):
if plot_dirts[i]['value'] > MaxReadNum:
plot_All.append(plot_dirts[i])
plot_title.append(plot_dirts[i]['lable'])
plot_numer.append(plot_dirts[i]['value'])
plot_link.append(plot_dirts[i]['xlink'])
name1='1.svg'
Plot_dirt(name1,plot_All,plot_title)
# 输出绘图数据的文本文件
Output_data('outputpart.txt',plot_title,plot_numer,plot_link,2
结果