#要安装bs4和request,用pip install from bs4 import BeautifulSoup import requests #用request下载网页图片 import urllib.request #放在函数定义 x = 0 #获取豆瓣图片 #参数赋值可以不写,也可以传个默认值1,但不能写i变量,因为这时i还没定义,两个变量相等是不行的 def getDbImage(page = 1): #x = 0 #获取网页源代码 #https://www.dbmeinv.com/?pager_offset=3 response = requests.get('https://www.dbmeinv.com/?pager_offset={}'.format(page)) html = response.text #返回200,说明请求成功 #print(response) #创建对象 用解释器解释网页 也可以用lxml等 soup = BeautifulSoup(html,'html.parser') #找到所有的img标签,这个网页只有我们要的照片有img标签,要看网页情况 girl = soup.find_all('img') #获得所有img标签,这是个列表,可以循环 #print(girl) #循环列表得到每一个标签 for img in girl: #print(img) #获得所有的链接 link = img.get('src') #print(link) #x定义在函数内则不需要global,但每次循环x都会变回0,不利于文件命名,在这里定义成全局变量 global x #下载图片,也可以用open,现在换个方法,urlretrieve(检索)第一个参数为链接,第二个参数是保存路径,images文件夹下,后面是文件名 urllib.request.urlretrieve(link,'images/%s.jpg'%x) #每次循环修改文件名,每次递增1, x += 1 #做个提示 print('正在下载第%s张图片'%x) #获取范围页数,比如前10页 for i in range(1,11): print("正在下载第{}页图片".format(i)) #现在对比下网页翻页变化,可以发现后面那个4可以更改为变量 #https://www.dbmeinv.com/?pager_offset=3 #https://www.dbmeinv.com/?pager_offset=4 getDbImage(i) #函数需要变量接受i
除去注释后简约版代码:
from bs4 import BeautifulSoup import requests import urllib.request x = 0 def getDbImage(page = 1): response = requests.get('https://www.dbmeinv.com/?pager_offset={}'.format(page)) html = response.text soup = BeautifulSoup(html,'html.parser') girl = soup.find_all('img') for img in girl: link = img.get('src') global x urllib.request.urlretrieve(link,'images/%s.jpg'%x) x += 1 print('正在下载第%s张图片'%x) for i in range(1,11): print("正在下载第{}页图片".format(i)) getDbImage(i)
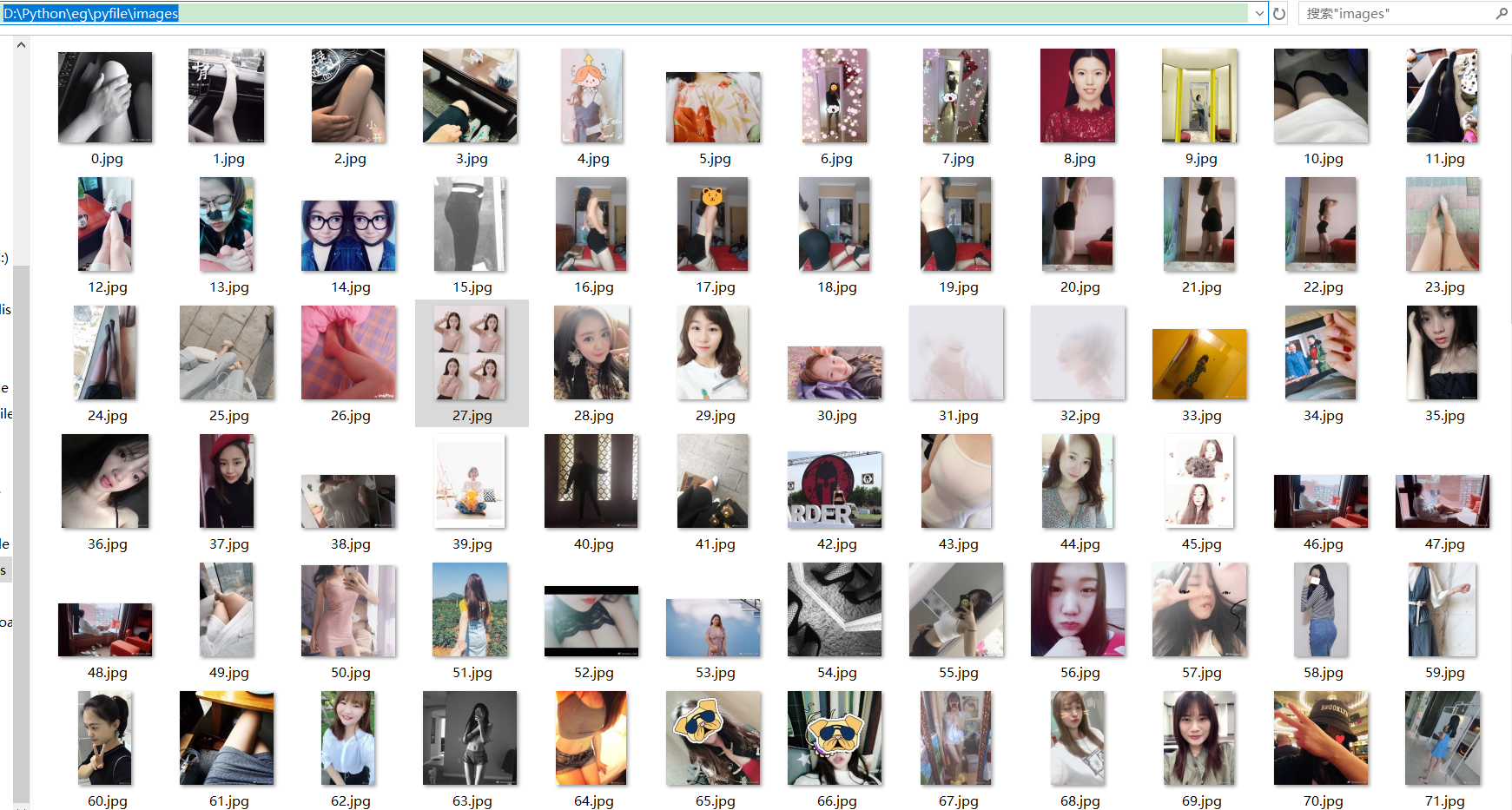
效果如下: