前言
发现在网上分享的链接需要一个一个提取很麻烦,所以写了一个脚本
代码
#! /usr/bin/env python
# _*_ coding:utf-8 _*_
from requests import session
from bs4 import BeautifulSoup
import csv
import codecs
import re
import time
import json
def login(email,passwd,isproxies):
url="https://xxx.com/auth/login"
data={
'email':email,'passwd':passwd}
proxies = {
"http": "http://127.0.0.1:8090",
"https": "http://127.0.0.1:8090",
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
if isproxies:
r=sess.post(url,data,headers=headers,proxies=proxies,verify=False)
else:
r = sess.post(url, data, headers=headers, verify=False)
def pa(isproxies):
url="https://xxx.com/user/node"
proxies = {
"http": "http://127.0.0.1:8090",
"https": "http://127.0.0.1:8090",
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
if isproxies:
r=sess.get(url,headers=headers,proxies=proxies,verify=False)
else:
r = sess.get(url, headers=headers, verify=False)
soup = BeautifulSoup(r.text, 'html.parser')
arr = soup.div.select('.row')
arr1 = BeautifulSoup(str(arr[1]), 'html.parser')#arr[1]为vip用户,arr[0]为普通用户
arr2 = arr1.div.select('.tile.tile-collapse')
for i in range(0, len(arr2)):
# for i in range(0, 1):
temp = BeautifulSoup(str(arr2[i]), 'html.parser')
name = re.findall(r'node-header-title">(.+?)\|', str(temp.div.select('.node-header-title')[1]))
node = re.findall(r"\d+", str(temp.a))[1]
ismu = re.findall(r"\d+", str(temp.a))[2]
person = re.findall(r"\d+", str(temp.div.select('.node-header-title')[1]))[1]
k = {
"name": name[0], "person": person, "ismu": ismu}
sum[node] = k
print(json.dumps(sum, ensure_ascii=False, indent=4))
def getlink(isproxies):
while 1:
print("请输入你要获取链接的节点id")
node = input("Please input your table_name: ")
if node in sum:
break
url = "https://xxx.com/user/node/"+node+"?ismu="+sum[node]['ismu']+"&relay_rule=0"
proxies = {
"http": "http://127.0.0.1:8090",
"https": "http://127.0.0.1:8090",
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
if isproxies:
r=sess.get(url,headers=headers,proxies=proxies,verify=False)
else:
r = sess.get(url, headers=headers, verify=False)
link=re.findall(r'href="(.+?)"/>', str(r.text))[0]
print(link)
def getalllink(isproxies,node):
url = "https://xxx.com/user/node/"+node+"?ismu="+sum[node]['ismu']+"&relay_rule=0"
proxies = {
"http": "http://127.0.0.1:8090",
"https": "http://127.0.0.1:8090",
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
if isproxies:
r=sess.get(url,headers=headers,proxies=proxies,verify=False)
else:
r = sess.get(url, headers=headers, verify=False)
link=re.findall(r'href="(.+?)"/>', str(r.text))[0]
print(link)
return link
def writecsv(isproxies):
csvFile = codecs.open('1.csv', 'w', encoding='GBK')
writer = csv.writer(csvFile)
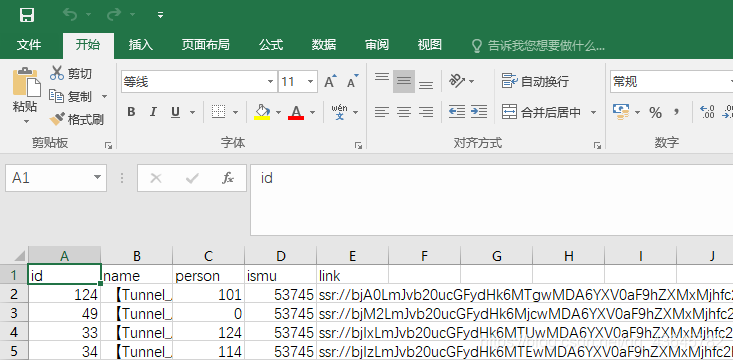
writer.writerow(["id", "name","person","ismu","link"])
for key,values in sum.items():
link=getalllink(isproxies,key)
writer.writerow([key.strip(), sum[key]['name'], sum[key]['person'], sum[key]['ismu'], link])
time.sleep(2)
csvFile.close()
def main(email,passwd,isproxies):
login(email,passwd,isproxies)
pa(isproxies)
while 1:
print("请输入你要获取的方式")
number = input("1获取全部链接,0获取指定链接")
if number=="0":
break
elif number=="1":
break
else:
print("输入错误,请重新输入")
if number=="1":
writecsv(isproxies)
else:
getlink(isproxies)
if __name__ == '__main__':
email=""#账号
passwd=""#密码
sess=session()
sum={
}
main(email,passwd,0)#0为不设置代理,1为设置代理
设置好网址和账号密码,之后选择输入即可