版权声明:供学习记录之用 https://blog.csdn.net/Keruila/article/details/80606152
爬取站点:http://www.biquge.info/22_22522/index.html
用到的模块/库:BeautifulSoup、urllib.request、urllib.error、re、sys
1、采集每一个章节的链接
网页解析:
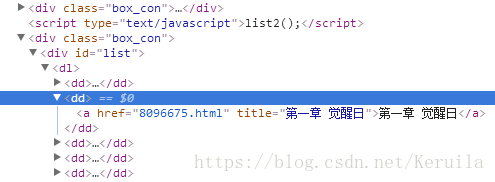
需要采集的是如图所示的“a”标签下的“href”属性;
采集每一个href属性放入一个列表中;
以下为采集章节链接的代码:
from bs4 import BeautifulSoup from urllib import request from urllib.error import HTTPError, URLError import re headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36') opener = request.build_opener() opener.addheaders = [headers] def get_chapter_link(url): try: html1 = request.urlopen(url) # 目录页 except (HTTPError,URLError) as e: print('打开失败') print(e) soup_html1 = BeautifulSoup(html1, "html5lib") href_list = [] # 用来保存所有章节的链接 # 此网页有两个<div class="box_con">标签,第二个为章节目录,所以此处用[1] for child in soup_html1.findAll('div', {'class': 'box_con'})[1] \ .findAll('a', {'href': re.compile(".{7,7}\.html")}): # 正则表达式筛选所有href属性为"*******.html"格式的a标签 if 'href' in child.attrs: href_list.append('http://www.biquge.info/22_22522/' + child.attrs['href']) # 构建章节链接,并加入列表 return href_list target_url = 'http://www.biquge.info/22_22522/index.html' print(get_chapter_link(target_url))运行结果:

2、采集每一个章节的内容
章节标题所在标签:

章节内容所在标签:
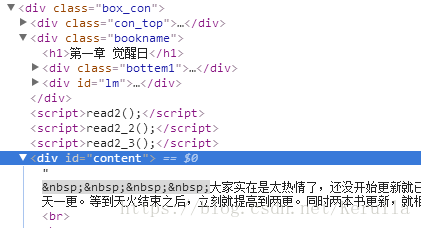
采集每一个章节的标题+内容写入txt文件中。
代码如下:
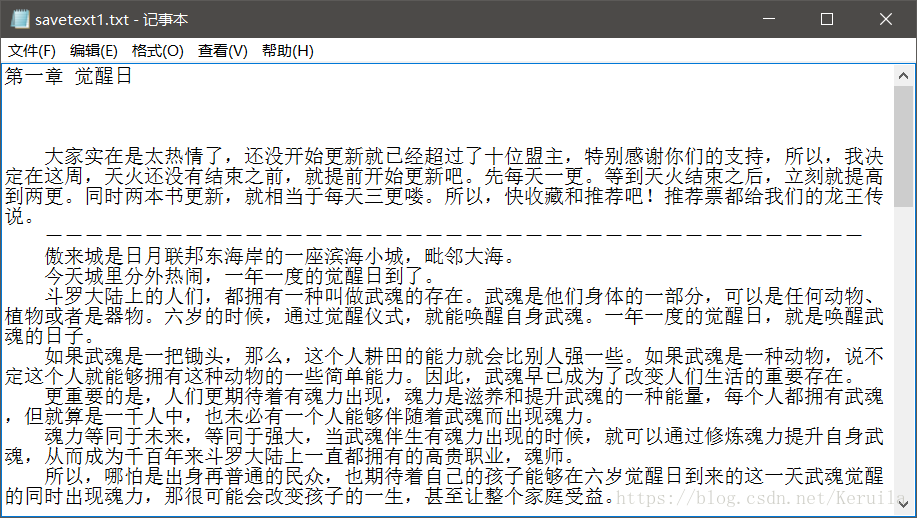
from bs4 import BeautifulSoup from urllib import request from urllib.error import HTTPError, URLError headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36') opener = request.build_opener() opener.addheaders = [headers] savetext1 = open('C:\\Users\Keruila\Desktop\savetext1.txt', 'a', encoding='utf-8') def get_chapter_content(url): try: html_content = request.urlopen(url) except (HTTPError, URLError) as e: print(e) print('打开失败') soup_content = BeautifulSoup(html_content, "html5lib") # 获得章节名 chapter_title = soup_content.find('div', {'class': 'box_con'}) \ .find('div',{'class': 'bookname'}).h1 savetext1.write(chapter_title.get_text() + '\n\n') # 写入txt文件中 # 获得章节内容 chapter_content = soup_content.find('div', {'class': 'box_con'}) \ .find('div',{'id': 'content'}) # 删除'\xa0'字符,先替换为&字符,再将连续的四个&字符 # 替换成'\n '(换行+四个空格)以达到理想的文章格式 tmp = chapter_content.get_text().replace('\xa0', '&') content = tmp.replace('&&&&', '\n ') savetext1.write(content + '\n\n') # 写入文件中 get_chapter_content('http://www.biquge.info/22_22522/8096675.html')采集结果:
3、整合以上两个函数,爬取整本书
from bs4 import BeautifulSoup from urllib import request from urllib.error import HTTPError, URLError import re import sys import time target_url = 'http://www.biquge.info/22_22522/index.html' headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) \ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36') opener = request.build_opener() opener.addheaders = [headers] savetext1 = open('C:\\Users\Keruila\Desktop\savetext1.txt', 'a', encoding='utf-8') def get_chapter_link(url): try: html1 = request.urlopen(url) # 目录页 except (HTTPError,URLError) as e: print('打开失败') print(e) soup_html1 = BeautifulSoup(html1, "html5lib") href_list = [] # 用来保存所有章节的链接 # 此网页有两个<div class="box_con">标签,第二个为章节目录,所以此处用[1] for child in soup_html1.findAll('div', {'class': 'box_con'})[1] \ .findAll('a', {'href': re.compile(".{7,7}\.html")}): # 正则表达式筛选所有href属性为"*******.html"格式的a标签 if 'href' in child.attrs: href_list.append('http://www.biquge.info/22_22522/' + child.attrs['href']) # 构建章节链接,并加入列表 return href_list def get_chapter_content(url): try: html_content = request.urlopen(url) except (HTTPError, URLError) as e: print(e) print('打开失败') soup_content = BeautifulSoup(html_content, "html5lib") # 获得章节名 chapter_title = soup_content.find('div', {'class': 'box_con'}) \ .find('div',{'class': 'bookname'}).h1 savetext1.write(chapter_title.get_text() + '\n\n') # 写入txt文件中 # 获得章节内容 chapter_content = soup_content.find('div', {'class': 'box_con'}) \ .find('div',{'id': 'content'}) # 删除'\xa0'字符,先替换为&字符,再将连续的四个&字符 # 替换成'\n '(换行+四个空格)以达到理想的文章格式 tmp = chapter_content.get_text().replace('\xa0', '&') content = tmp.replace('&&&&', '\n ') savetext1.write(content + '\n\n') # 写入文件中 chapter_link_list = get_chapter_link(target_url) downloaded = 0 # 已经下载的数量 chapter_count = len(chapter_link_list) # 章节总数量 start_time = time.time() # 计算下载时间 for link in chapter_link_list: get_chapter_content(link) # 打印爬取进度,在命令行里可以显示 downloaded += 1 sys.stdout.write("已下载:%.3f%%" % float(downloaded / chapter_count * 100) + '\r') sys.stdout.flush() savetext1.close() end_time = time.time() print('用时:%.2f s' % (end_time - start_time))
正在下载:
手机阅读软件打开就可以看:
参考:https://blog.csdn.net/c406495762/article/details/71158264