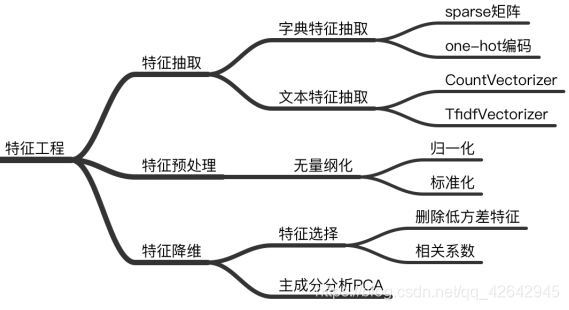
特征降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
- 降低随机变量的个数
特征降维,有时候也称之为特征抽取(用于降维的特征选择方法)或数据压缩,因为现实生活中产生的数据是越来越多,数据压缩技术可以帮助我们对数据进行存储和分析。
特征降维是无监督学习的另一个应用,我们会经常在实际项目中遭遇特征维度非常之高的训练样本,而往往又无法借助自己的领域知识人工构建有效特征;在数据表现方面,我们无法用肉眼观测超过三个维度的特征。因此,特征降维不仅仅重构了有效的低纬度特征,同时也为数据展现提供了可能。在特征降维技术中 PCA 主成分分析是最为经典和实用的特征降维技术,在图像识别方面表现的也很突出。
特征降维的目的
为什么要进行数据降维?
通常处理的数据是多维的,算法的时间复杂度与维数成指数级增加。维数达上千万维,称为维数灾难,往往就需要进行降维处理。
数据降维的作用
- 1.使数据集更容易使用
- 2.降低算法的计算开销
- 3.去除噪声
- 4.减轻过拟合
- 5.易于获取有价值的信息
降维的两种方式

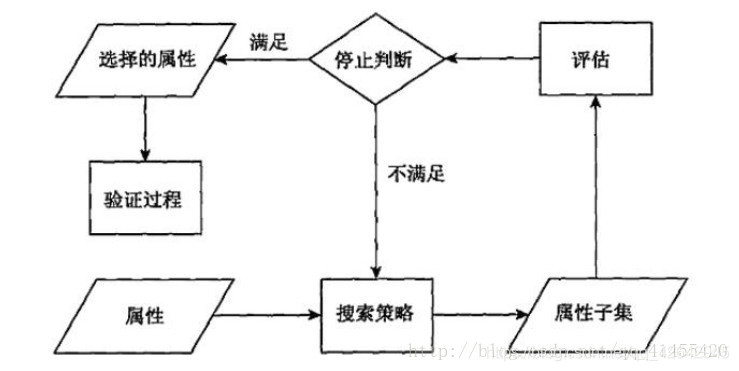
如果我们对领域特征比较熟悉,可以对特征加权,可以说特征加权是一种保留或删除特征的办法。特征越重要,所赋予的权值就越大,而不太重要的特征赋予较小的权值。该法在很多模型中均使用了,如 svm 中对每一个特征都赋予了一个权值。
(2)主成分分析(可以理解一种特征提取的方式):用变换(映射)的方法,把原始特征变换为较少的新特征。 由原始数据创建新的特征集称为特征提取。比如照片的集合,按照照片是否包含人脸分类提取一些特征。
什么是特征选择
定义
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。

方法
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数
- Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
对于Embedded方式,只能在讲解算法的时候在进行介绍,更好的去理解
模块
sklearn.feature_selection
过滤式
低方差特征过滤
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
API
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)- 删除所有低方差特征
- Variance.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
数据计算
数据文件factor_returns.csv获取:
链接:https://pan.baidu.com/s/1z2R2VLIfyxnZxU4e-mvGig
提取码:537w
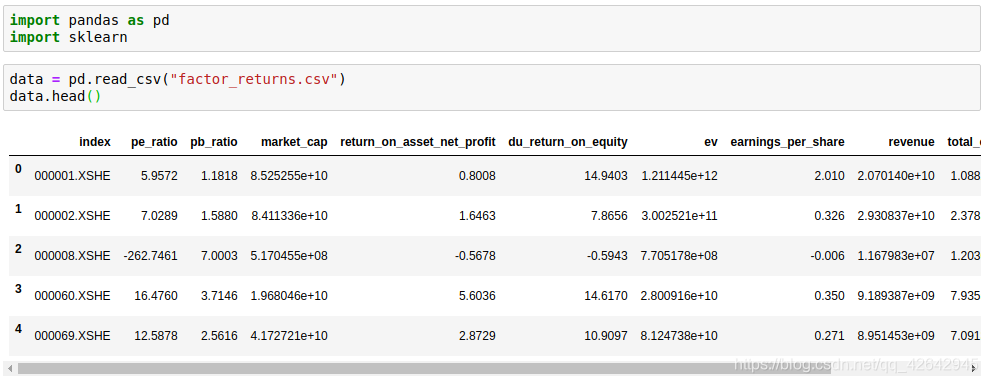
我们对某些股票的指标特征之间进行一个筛选,数据在"factor_returns.csv"文件当中,除去’index,‘date’,'return’列不考虑(这些类型不匹配,也不是所需要指标)
pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense
index,pe_ratio,pb_ratio,market_cap,return_on_asset_net_profit,du_return_on_equity,ev,earnings_per_share,revenue,total_expense,date,return
0,000001.XSHE,5.9572,1.1818,85252550922.0,0.8008,14.9403,1211444855670.0,2.01,20701401000.0,10882540000.0,2012-01-31,0.027657228229937388
1,000002.XSHE,7.0289,1.588,84113358168.0,1.6463,7.8656,300252061695.0,0.326,29308369223.2,23783476901.2,2012-01-31,0.08235182370820669
2,000008.XSHE,-262.7461,7.0003,517045520.0,-0.5678,-0.5943,770517752.56,-0.006,11679829.03,12030080.04,2012-01-31,0.09978900335112327
3,000060.XSHE,16.476,3.7146,19680455995.0,5.6036,14.617,28009159184.6,0.35,9189386877.65,7935542726.05,2012-01-31,0.12159482758620697
4,000069.XSHE,12.5878,2.5616,41727214853.0,2.8729,10.9097,81247380359.0,0.271,8951453490.28,7091397989.13,2012-01-31,-0.0026808154146886697
分析
- 1、初始化VarianceThreshold,指定阀值方差
- 2、调用fit_transform
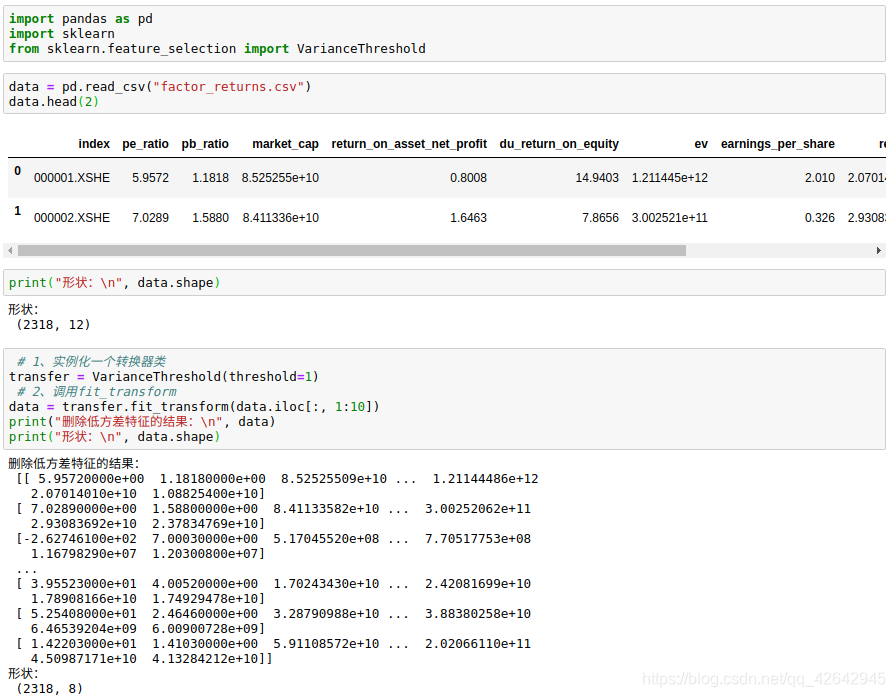
def variance_demo():
"""
删除低方差特征——特征选择
:return: None
"""
data = pd.read_csv("factor_returns.csv")
print(data)
# 1、实例化一个转换器类
transfer = VarianceThreshold(threshold=1)
# 2、调用fit_transform
data = transfer.fit_transform(data.iloc[:, 1:10])
print("删除低方差特征的结果:\n", data)
print("形状:\n", data.shape)
return None

相关系数
- 皮尔逊相关系数(Pearson Correlation Coefficient)
- 反映变量之间相关关系密切程度的统计指标
公式计算案例(了解,不用记忆)
公式
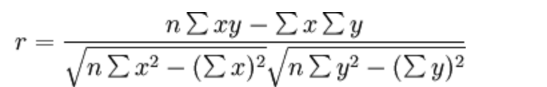
- 反映变量之间相关关系密切程度的统计指标
比如说我们计算年广告费投入与月均销售额
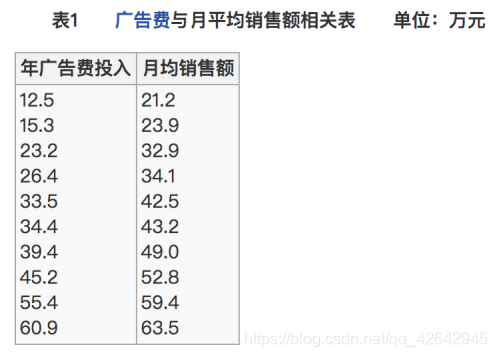
那么之间的相关系数怎么计算
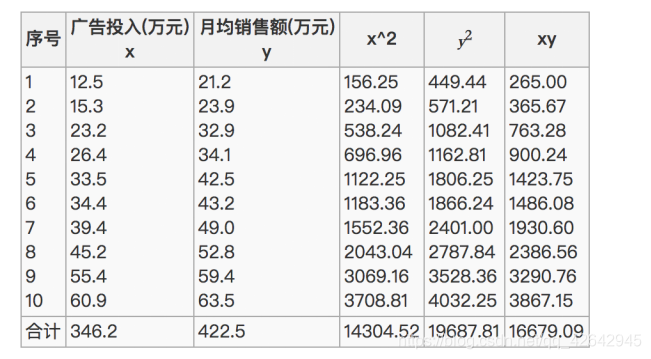
最终计算:
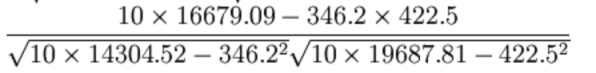
= 0.9942
所以我们最终得出结论是广告投入费与月平均销售额之间有高度的正相关关系。
特点
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。其性质如下:
- 当r>0时,表示两变量正相关,r<0时,两变量为负相关
- 当|r|=1时,表示两变量为完全相关,当r=0时,表示两变量间无相关关系
- 当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱
- 一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
皮尔逊相关系数(Pearson Correlation Coefficient)API
from scipy.stats import pearsonr
- x : (N,) array_like
- y : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
案例:股票的财务指标相关性计算
我们刚才的股票的这些指标进行相关性计算, 假设我们以
factor = ['pe_ratio','pb_ratio','market_cap','return_on_asset_net_profit','du_return_on_equity','ev','earnings_per_share','revenue','total_expense']
这些特征当中的两两进行计算,得出相关性高的一些特征
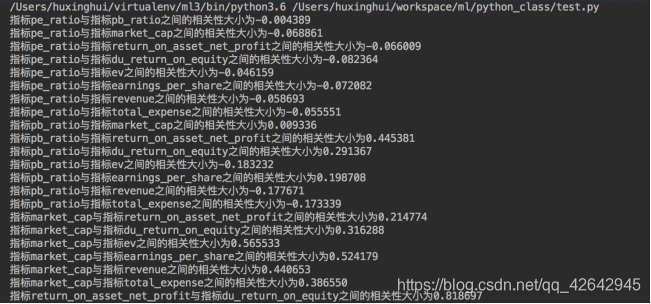
- 分析
- 两两特征之间进行相关性计算
import pandas as pd
from scipy.stats import pearsonr
def pearsonr_demo():
"""
相关系数计算
:return: None
"""
data = pd.read_csv("factor_returns.csv")
factor = ['pe_ratio', 'pb_ratio', 'market_cap', 'return_on_asset_net_profit', 'du_return_on_equity', 'ev',
'earnings_per_share', 'revenue', 'total_expense']
for i in range(len(factor)):
for j in range(i, len(factor) - 1):
print(
"指标%s与指标%s之间的相关性大小为%f" % (factor[i], factor[j + 1], pearsonr(data[factor[i]], data[factor[j + 1]])[0]))
return None
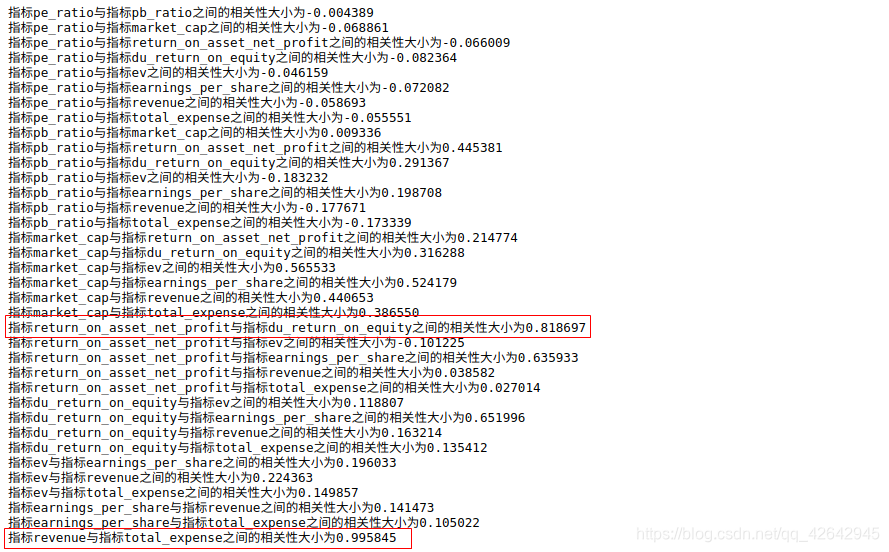
从中我们得出
- 指标revenue与指标total_expense之间的相关性大小为0.995845
- 指标return_on_asset_net_profit与指标du_return_on_equity之间的相关性大小为0.818697
我们也可以通过画图来观察结果
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 8), dpi=100)
plt.scatter(data['revenue'], data['total_expense'])
plt.show()
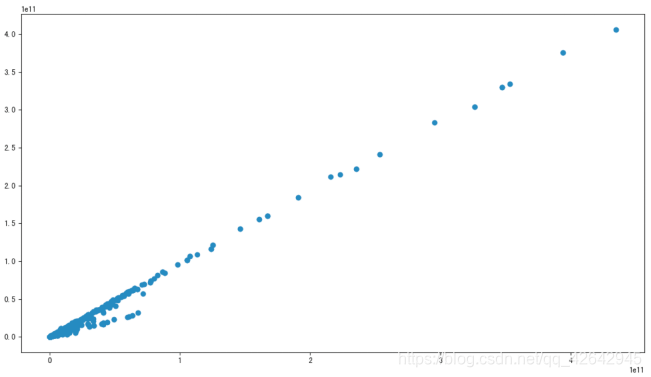
这两对指标之间的相关性较大,可以做之后的处理,比如合成这两个指标。
主成分分析
什么是主成分分析(PCA)
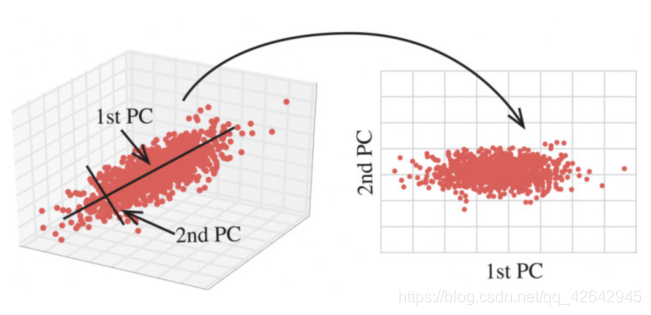
在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。
-
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
-
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
-
应用:回归分析或者聚类分析当中
对于信息一词,在决策树中会进行介绍
那么更好的理解这个过程呢?我们来看一张图

计算案例理解(了解,无需记忆)
假设对于给定5个点,数据如下
(-1,-2)
(-1, 0)
( 0, 0)
( 2, 1)
( 0, 1)
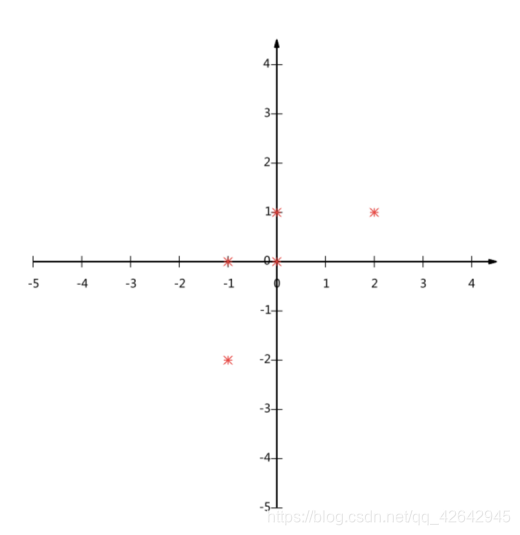
要求:将这个二维的数据简化成一维? 并且损失少量的信息
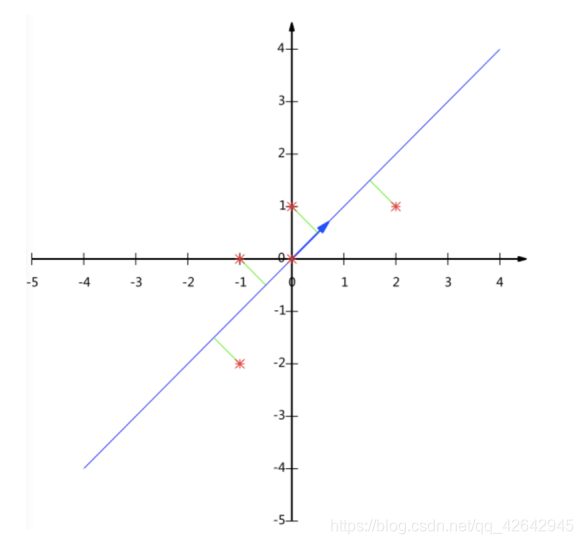
这个过程如何计算的呢?找到一个合适的直线,通过一个矩阵运算得出主成分分析的结果(不需要理解)

API
sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
数据计算
先拿个简单的数据计算一下
[[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
from sklearn.decomposition import PCA
def pca_demo():
"""
对数据进行PCA降维
:return: None
"""
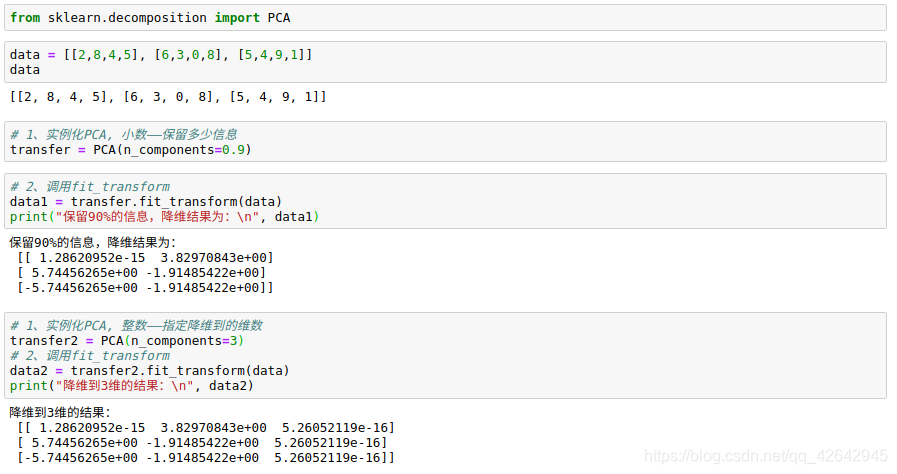
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 1、实例化PCA, 小数——保留多少信息
transfer = PCA(n_components=0.9)
# 2、调用fit_transform
data1 = transfer.fit_transform(data)
print("保留90%的信息,降维结果为:\n", data1)
# 1、实例化PCA, 整数——指定降维到的维数
transfer2 = PCA(n_components=3)
# 2、调用fit_transform
data2 = transfer2.fit_transform(data)
print("降维到3维的结果:\n", data2)
return None
2.6.2 案例:探究用户对物品类别的喜好细分降维

https://www.kaggle.com/c/instacart-market-basket-analysis

数据下载:
链接:https://pan.baidu.com/s/1et1bWdGXgjd7WvCQRZ-H3w
提取码:k2by
数据如下:
- order_products__prior.csv:订单与商品信息
- 字段:order_id, product_id, add_to_cart_order, reordered
- products.csv:商品信息
- 字段:product_id, product_name, aisle_id, department_id
- orders.csv:用户的订单信息
- 字段:order_id,user_id,eval_set,order_number,….
- aisles.csv:商品所属具体物品类别
- 字段: aisle_id, aisle
1 需求
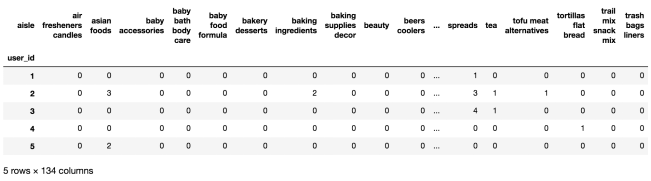
分析
- 合并表,使得user_id与aisle在一张表当中
- 进行交叉表变换
- 进行降维
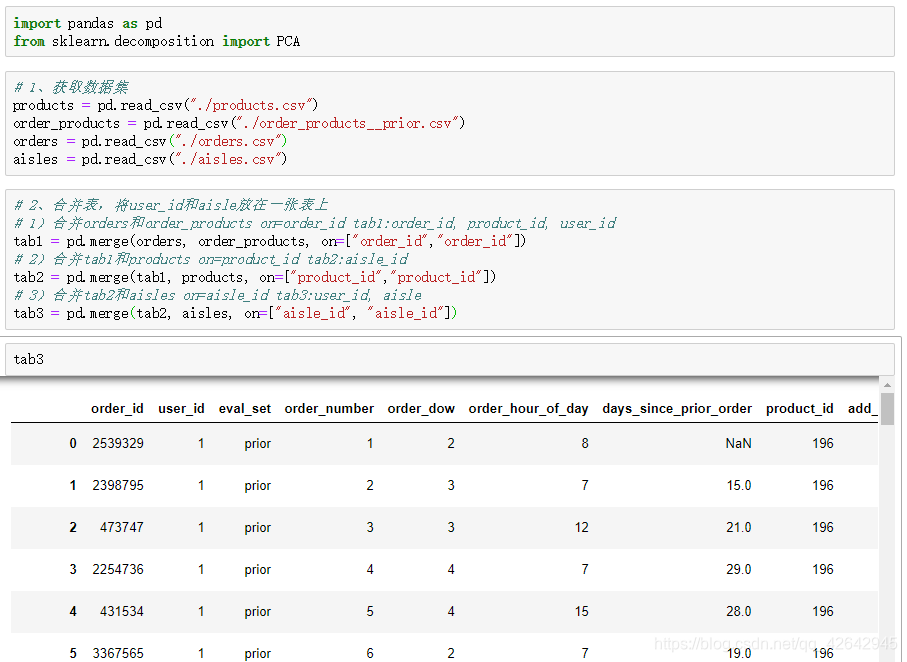
完整代码
import pandas as pd
from sklearn.decomposition import PCA
# 1、获取数据集
# ·商品信息- products.csv:
# Fields:product_id, product_name, aisle_id, department_id
# ·订单与商品信息- order_products__prior.csv:
# Fields:order_id, product_id, add_to_cart_order, reordered
# ·用户的订单信息- orders.csv:
# Fields:order_id, user_id,eval_set, order_number,order_dow, order_hour_of_day, days_since_prior_order
# ·商品所属具体物品类别- aisles.csv:
# Fields:aisle_id, aisle
products = pd.read_csv("./products.csv")
order_products = pd.read_csv("./order_products__prior.csv")
orders = pd.read_csv("./orders.csv")
aisles = pd.read_csv("./aisles.csv")
# 2、合并表,将user_id和aisle放在一张表上
# 1)合并orders和order_products on=order_id tab1:order_id, product_id, user_id
tab1 = pd.merge(orders, order_products, on=["order_id", "order_id"])
# 2)合并tab1和products on=product_id tab2:aisle_id
tab2 = pd.merge(tab1, products, on=["product_id", "product_id"])
# 3)合并tab2和aisles on=aisle_id tab3:user_id, aisle
tab3 = pd.merge(tab2, aisles, on=["aisle_id", "aisle_id"])
# 3、交叉表处理,把user_id和aisle进行分组
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
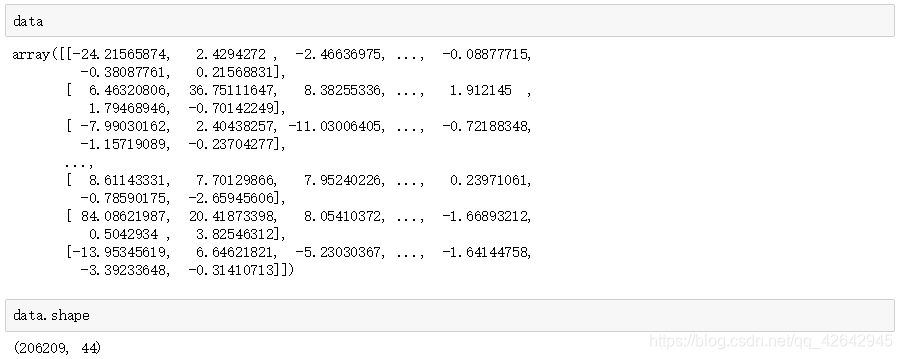
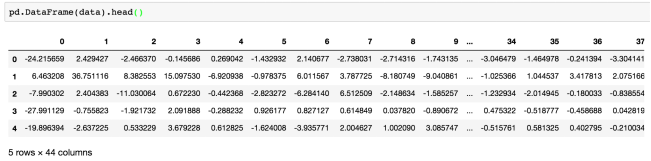
# 4、主成分分析的方法进行降维
# 1)实例化一个转换器类PCA
transfer = PCA(n_components=0.95)
# 2)fit_transform
data = transfer.fit_transform(table)
data.shape