一、数据的降维
(1)含义
数据降维是减少特征的数量,优化算法的运行。
(2)降维的方法
1>过滤式特征选择
# 除去方差小于某个值的那一列特征
from sklearn.feature_selection import VarianceThreshold
def var():
var = VarianceThreshold(threshold=0.0) # 过滤式特征选择,这里是除去为零的特征
x = [[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]
data = var.fit_transform(x)
print(data)
return None
#结果是
[[2 0]
[1 4]
[1 1]]
2>主成分分析
from sklearn.decomposition import PCA
def pca():
pca = PCA(n_components=0.9)
#保留90%特征的意思
x = [[2,8,4,5],[6,3,0,8],[5,4,9,1]]
data = pca.fit_transform(x)
print(data)
return None
#结果
[[ 1.22879107e-15 3.82970843e+00]
[ 5.74456265e+00 -1.91485422e+00]
[-5.74456265e+00 -1.91485422e+00]]
(3)降维的实例运用
# 下面是利用kaggle上的数据探究用户对物品类别的喜好细分
>>1首先我们获取的数据是有很多的表格,我们需要连接他们
# 运用pandas中merge合并表
import pandas as pd
from sklearn.decomposition import PCA
# 读取表格
order_product = pd.read_csv("./data/instacart/order_products__prior.csv")
products = pd.read_csv("./data/instacart/products.csv")
orders = pd.read_csv("./data/instacart/orders.csv")
aisles = pd.read_csv("./data/instacart/aisles.csv")
#合并表格
table1 = pd.merge(order_product, products, on=["product_id", "product_id"])
table2 = pd.merge(table1, orders, on=["order_id", "order_id"])
table = pd.merge(table2, aisles, on=["aisle_id", "aisle_id"])
>>2然后我们要把表格变成适用机器学习的方式
# 行为用户,列为不同物品的类别
# 利用pandas中crosstab来交叉表(指定行和列)
table = pd.crosstab(table["user_id"], table["aisle"])
>>3利用PCA进行主成分分析
transfer = PCA(n_components=0.9)
data = transfer.fit_transform(table)
>>4最后我们可以进行主成分分析并查看剩余的特征数量
print(data.shape)
二、数据的划分
因为要评估模型训练的优劣,所以要将测试集分为训练集和测试集。我们可以依靠函数帮助我们完成较好的分类。
from sklearn.datasets import load_iris
#调取sklearn中存在的数据集iris
from sklearn.model_selection import train_test_split
#调取划分数据集的函数 train_test_split
li = load_iris()
print("获取特征值")
print(li.data)
print("目标值")
print(li.target)
print(li.DESCR)
# 注意返回值, 训练集 train x_train, y_train 测试集 test x_test, y_test
# x为特征集,y为目标集
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
#注意顺序哦
print("训练集特征值和目标值:", x_train, y_train)
print("测试集特征值和目标值:", x_test, y_test)
三、转换器与估计器
(1)转换器
fit_transform
可以换成两部分,前者求均值和方差,后者运算。
(2)估计器
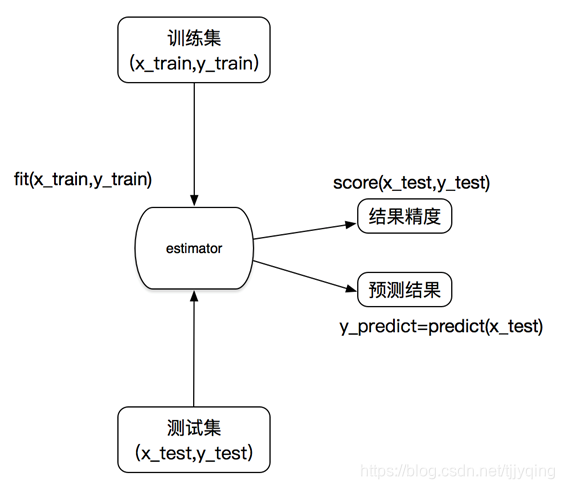
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API。
#用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
#用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
估计器的工作流程
扫描二维码关注公众号,回复:
12576761 查看本文章
