Ridge回归、LASSO回归、Elastic Net弹性网络解决过拟合问题
1.如果仅是在测试集数据集上存在该问题–>过拟合
如果模型在训练集上的效果不错,但是在测试集上的效果非常差,在这种情况下,认为模型存在过拟合。
产生的原因:
a.样本少
b.模型的学习能力太强(模型比较复杂)
c.做了太多的特征的增维操作
解决方案:
a.增加样本的数量
b.换一个算法模型或者在训练过程中,加入正则化项系数,限制模型过拟合,正则化有两个:L1和L2
c.不要做太多的增维操作
为了防止过拟合,不能让theta的值过大或过小,可以在目标函数上增加一个平方和损失。
平方和损失称之为L2-norm
绝对值theta称之为L1-norm
Ridge回归:使用L2正则的线性回归模型称为Ridge回归(岭回归)
LASSO回归:使用L1正则的线性回归模型称为LASSO回归
Elastic Net(弹性网络):同时使用L1和L2正则的线性回归模型
区别:
Ridge模型具有较高的准确性、鲁棒性以及稳定性(如果数据中不存在冗余的特征属性)圆
LASSO模型因为能去掉数据中的噪音或者冗余(所以将LASSO算法运用到特征的选择),所以具有较高的求解速度。稀疏解:是训练出来得到的模型中有很多参数值都是0。稀疏解是用于特征的选择,因为参数为0所对应的特征相当于没有决策能力。 正方形
如果既要考虑稳定性也考虑求解的速度,就使用Elastic Net p(圆形) + (1-p)(正方形)
衡量回归算法模型效果的指标
- MSE :误差平方和
- RMSE :MSE的平方根
- R^2:取值范围(负无穷,1],值越大表示模型越拟合训练数据,,最优解为1。
模型参数:需要在训练集上通过给定的方式找出模型参数;形如:线性回归中的θ
超参数:在模型训练中需要使用到的参数值,但是该参数值需要开发人员给定的。形如:Ridge模型中的alpha对应公式中的lamada
给定超参数的方式:
1.可以根据算法的特性来选择一个比较合适的值。形如:Ridge模型中的alpha(0.1~0.001)
2.通过sklearn提供的交叉验证的方式来选择最优参数
3.通过网格交叉验证的方式来选择最优参数
代码如下:
使用Ridge回归算法
#引入所需要的包
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import time
#创建一个时间字符串格式化字符串
def date_format(dt):
import time
t = time.strptime(’ ‘.join(dt),’%d/%m/%Y %H:%M:%S’)
return (t.tm_year,t.tm_mon,t.tm_mday,t.tm_hour,t.tm_min,t.tm_sec)
#设置字符集,防止中文乱码
mpl.rcParams[‘font.sans-serif’] = [u’simHei’]
mpl.rcParams[‘axes.unicode_minus’] = False
#1、加载数据
path = ‘./datas/household_power_consumption_1000.txt’
#path = ‘./datas/household_power_consumption_200.txt’
df = pd.read_csv(path,sep=’;’,low_memory=False)
#日期、时间、有功功率、无功功率、电压、电流、厨房用电功率、洗衣服用电功率、热水器用电功率
names1 = df.columns
print(names1)
names = [“Date”,“Time”,“Global_active_power”,“Global_reactive_power”,“Voltage”,“Global_intensity”,“Sub_metering_1”,“Sub_metering_2”,“Sub_metering_3”]
#数据清洗
df.replace(’?’,np.nan,inplace=True)
datas = df.dropna(axis=0,how=‘any’)
#构建数据
X = datas[names[0:2]]
X = X.apply(lambda x:pd.Series(date_format(x)),axis=1)
Y = datas[names[4]]
X = X.astype(np.float)
Y = Y.astype(np.float)
#将数据划分为训练集和测试集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=0)
#1.构建一个管道流对象,定义数据处理的顺序
“”"
Ridge参数说明:alpha = 1.0 PPT上的lamada,正则化系数
fit_intercept = True,:模型是否训练截距项,默认为训练(True)
normalize = False,:在训练之前,是否做归一化操作,一般不改动。
copy_X = True,
max_iter = None,
random_state = None
“”"
model = Pipeline(steps = [
(‘Poly’,PolynomialFeatures()),
(‘Linear’,Ridge(alpha=0.1,fit_intercept=False))
])
#1.2 Pineline设置管道的参数
model.set_params(Poly__degree = 4)
model.set_params(Linear__normalize = True)
#2.模型训练(先调用第一步进行数据处理,然后调用第二步做模型训练。)
#假设是n步操作,前n-1步操作是:fit + transform,最后一步操作是fit
model.fit(X_train,Y_train)
print(“多项式模型:{}”.format(model.get_params()[‘Poly’]))
print(“线性回归模型:{}”.format(model.get_params()[‘Linear’]))
#3.预测值产生(先调用第一步的transform对数据进行转换,再调用predict对数据进行预测。)
#假设是n步操作,前n-1步操作是:transform,最后一步操作是predict
y_predict = model.predict(X_test)
#模型效果
linear_model = model.get_params()[‘Linear’]
print(“线性回归的各个特征属性对应的权重参数theta:{}”.format(linear_model.coef_))
print(“线性回归的截距项的值:{}”.format(linear_model.intercept_))
print(“在训练集上的模型效果:{}”.format(model.score(X_train,Y_train)))
print(“在测试集集上的模型效果:{}”.format(model.score(X_test,Y_test)))
print(“在测试集上的MSE的值:{}”.format(mean_squared_error(y_true = Y_test,y_pred=y_predict)))
print(“在测试集上的RMSE的值:{}”.format(np.sqrt(mean_squared_error(y_true=Y_test,y_pred=y_predict))))
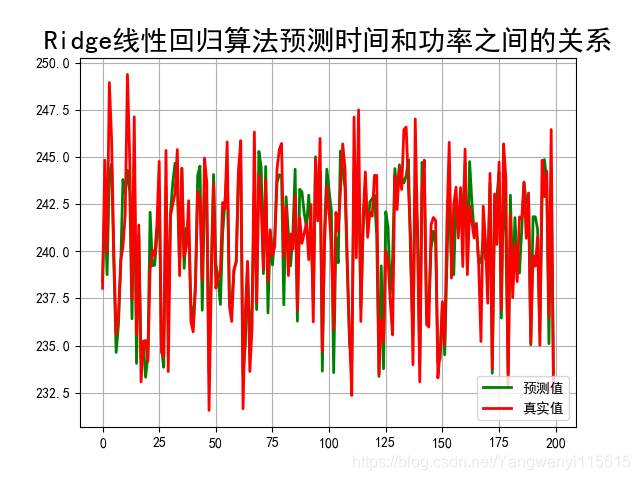
#画图查看一下效果
t = np.arange(len(X_test))
plt.figure(facecolor=‘w’)
plt.plot(t,y_predict,‘g-’,linewidth = 2, label = u’预测值’)
plt.plot(t,Y_test,‘r-’,linewidth = 2,label = u’真实值’)
plt.legend(loc=‘lower right’)
plt.title(‘线性回归(管道)预测时间和功率之间的关系’,fontsize = 20)
plt.grid(b = True)
plt.savefig(‘Ridge.png’)
plt.show()
运行的结果: