A paper a day keeps trouble away
论文地址:https://arxiv.org/pdf/1703.10593.pdf
论文Github:https://junyanz.github.io/CycleGAN
收录于:ICCV 2017

这篇文章讲的就是大名鼎鼎的CycleGAN,它可以实现再无配对数据的情况实现不同域(domain)之间图像的互相转换。它的基本思想和前面讲过的DiscoGAN和DualGAN是一致的,同样只看一下它精髓的地方。
首先直观上看一下它的效果怎么样

在这篇文章之前,已经有很多方法来处理无配对样本的图像转换问题,比如Bayesian framework、CoGAN等,相比于这些方法,CycleGAN有如下的优点:
- 它的通用性更强,不依赖于具体的任务
- 它不需要预先定义输入和输出之间的相似性函数
- 它不依赖于输入和输出位于相同的低维嵌入空间的假设
下面我们再看一下它的架构

它使用两个生成器、两个判别器,通过构成环状的结构来实现两个域的图像之间相互转换,和DualGAN、DiscoGAN没什么本质的区别。
在CycleGAN中主要是包含两个损失项对抗损失(Adversarial loss)和循环一致性损失(Cycle Consistency loss)。
Adversarial loss
这部分和标准GAN的损失项是一致的,它们的数学表达如下所示:
LGAN(G,DY,X,Y)=Ey∼pdata(y)[logDY(y)]+Ex∼pdata(x)[log(1−DYG(x))]LGAN(F,DX,Y,X)=Ex∼pdata(x)[logDX(x)]+Ey∼pdata(y)[log(1−DxF(y))]
那么自然所有的G都希望生成的样本尽可能的接近于真实,而所有的D 都希望尽最大努力判别出真实样本和生成样本,所以我们的目标自然就是如下的形式:
GminDYmaxLGAN(G,DY,X,Y)FminDXmaxLGAN(G,DX,Y,X)
Cycle Consistency loss
这里同时使用的是
L1 度量,我们希望重构后的样本接近于输入,所以定义Cycle Consistency loss为如下的形式:
Lcyc(G,F)=Ex∼pdata(x)[∣∣F(G(x))−x∣∣1]+Ey∼pdata(y)[∣∣G(F(y))−y∣∣1]
将上面的两个损失项整合起来得到我们最终的目标函数是
L(G,F,DX,DY)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+λLcyc(G,F)
其中
λ 是一个常数,控制两项损失的的相对重要性,在后面的实验中作者令
λ=10。
那么通过对目标函数的最大最小化就可以得到最优的G和F:
G∗,F∗=argG,FminDX,DYmaxL(G,F,DX,DY)
训练技巧
-
使用最小二乘损失(least-square loss)代替负的对数似然,这样做可以加强训练过程的稳定性,同时生成的结果更好。对于G来说,我们最小化的是
Ex∼pdata(x)[(D(G(x))−1)2]
对于D来说,我们需要最小化的是
Ey∼pdata(y)[(D(y)−1)2]+Ex∼pdata(x)[D(G(x))2]
-
使用生成图像的历史数据来更新判别器而不是最新生成的图像,所以开辟了一个存放50张历史图像的缓冲区
-
使用学习率初始化为0.0002,在训练的前100轮保持不变,在后100轮逐渐线性减小到0
实验
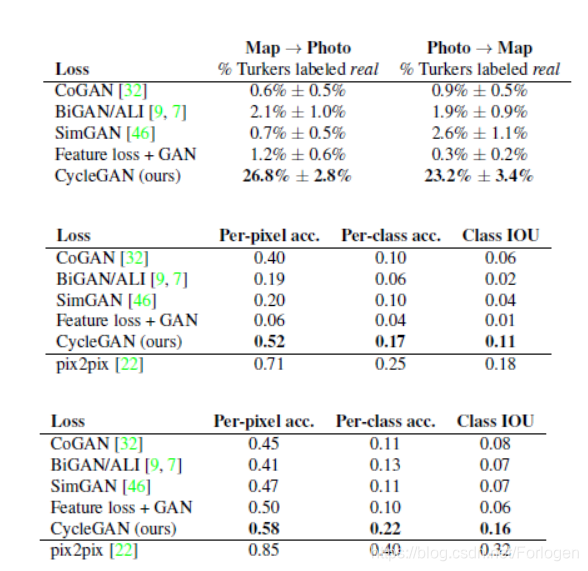
在实验的评估手段上同样使用的是AMT和FCN score,在Map->Photo和Photo->Map两个数据集上比较不同的GAN的变种之间的效果差异,结果如下所示
定性评估的结果,从中可以看出CycleGAN和pix2pix效果要优于其他的模型。

定量评估来看,无论是AMT的结果、FCN-scores还是分类的表现,CycleGAN都优于除pix2pix以外的模型,并且和pix2pix效果最为接近。
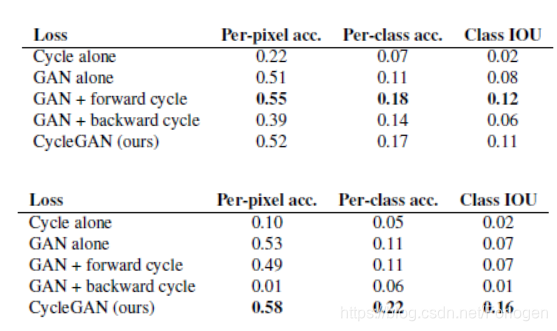
同样在评估两个损失向的重要性时发现,移除任何一个都会造成效果的大幅下降。另外如果只使用GAN+forward cycle或是GAN + backward cycle都会出现模式崩溃的问题,而且会影响训练过程的不稳定性。
在重构数据的质量方面,CycleGAN也取得不错的效果,重构后的图像很接近于输入的样本图像

此外作者还在有关图像的其他方面做了实验,证实了CycleGAN的效果要由于其它的模型。其中在从绘画中生成照片这项实验中,作者发现,当引进一个额外的损失项
Lidentity 后,输出图像的颜色部分更接近于输入图像。
Lidentity 的定义如下所示:
Lidentity(G,F)=Ey∼pdata(y)[∣∣G(y)−y∣∣1]+Ex∼pdata(x)[∣∣F(x)−x∣∣1]
效果如下所示

总结
最后作者提出,CycleGAN适合于涉及纹理、颜色变化的图像的转换任务,但是在涉及几何变化的方面效果并不好。所以在未来的工作中,如何处理更多样和更极端的转换任务是一个值得思考的问题。
此外如何想办法减小配对数据和非配对数据对于模型训练的影响,作者提出可以通过集成弱或半监督的数据的方法,可能会生成更强大的翻译器,但仍然需要监督训练方式下一小部分的标注成本。
更多
https://hardikbansal.github.io/CycleGANBlog/
http://www.sohu.com/a/139796566_297288
https://github.com/wiseodd/generative-models