Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
源码链接:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
论文链接:源码链接里有
1.创新
针对非成对的数据集,提出了一种通用型的image-to-image 的训练模式,并且提出了结合循环一致损失和对抗网络损失来进行模型的训练,通过采集图像,提取其中的特性,使得应用在其他图像集上,在缺少完成数据对的数据结构上。实验表明,这种方式能够解决没有成对数据集的问题,并且通用性更加强。
2.综述
1.提出 input-output 非对应的训练算法
2.表示在这两个非成对的数据集中,存在一定的相关联系

3.单独对抗网络的问题
1.对应的训练好的生成器,在输入和输出中,不能保证有意义的映射,并且单独的对抗损失容易出现很多问题,难以优化并且会出现多个输入映射成相同的输出。
4.解决
1.认为对应的映射应该是双射关系,如语言的来回翻译。
2.提出对抗损失和循环一致损失的结合。
3.相关工作
提出一种更一般的方法:
1.不基于特定的任务
2.不预设输入和输出的相似方法
3.不认为输入和输出具有相似的低维嵌入空间
4.提出是基于两个数据集合进行训练的,不同于一般把两张特定的图片进行训练的方式,目的是为了获得两个结合对应的高层表现结构(highter-level appearance structures)
4.公式
1.对抗网络损失 公式

其中Dy表示判断生成的Y是否是real or fack,其中也是一个最大最小化问题,G表示X->Y的映射生成器,X,Y分别表示两个数据集。这本质上也是一个最大最小化问题,![]() 首先把G的参数定住,然后更新Dy,目的是为了让Dy中产生的损失竟可能大,因为这样子就表示判别器的能力更强,更容易找茬。然后定住Dy,来更新G的参数,在这个情况下,要让损失尽可能小,因为这样可以使得生成器朝着减小 fack 和 real 之间的差别前进。
首先把G的参数定住,然后更新Dy,目的是为了让Dy中产生的损失竟可能大,因为这样子就表示判别器的能力更强,更容易找茬。然后定住Dy,来更新G的参数,在这个情况下,要让损失尽可能小,因为这样可以使得生成器朝着减小 fack 和 real 之间的差别前进。
同时,因为考虑到双射关系,本文还进行了Y->X的生成器的训练
本质上和,生成器X->Y的形式是一样的,其中F为Y->X的生成器模型,Dx表示判断 X是否为 real or fack,X和Y还是跟上面一样也是对应的数据集,只不过这里是反向的生成,迭代优化过程也和上面一样。
2.循环一致顺损失(Cycle Consistency Loss)
在只使用gan 的对抗损失时,在足够大的容量的情况下,网络可以将同一组输入图像映射到目标域中的图像的任何随机排列,其中任何学习的映射可以引起与目标分布匹配的输出分布。为了减少可能的映射空间,提出了循环一致损失:
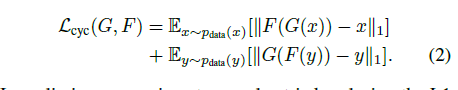
其中上面一行是前向循环一致,下面一行是反向循环一致,对应的也是使用L1损失进行损失计算

循环一致的理解可以如图来理解,文中认为,其中对应的转化,应该要保证前向转化之后,反向转化依然能够保持和原图的相似新,也可以理解为距离偏差应该尽可能的小。

效果图如图所示。
并且文中曾尝试使用对抗损失尽心替换,但是效果没有提升。
3.最终的目标函数:
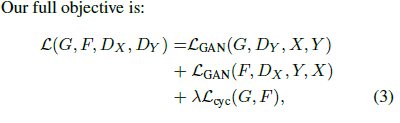
也就是将 G和F的对抗网络进行结合并加上循环一致损失。
最终的优化,也就是下公式

跟上面的优化步骤一样,最大最小化的优化顺序。
文中的目标是学习得到Y领域的高级表现结构,实验证明上述的目标函数是最总要且效果最好的,缺一不可,本质上,对于这个非对应数据集的训练问题,是一个约束过少的问题,所以必须要保证循环一致网络的双向(前向和后向)都要有,否则将会大大影响效果。
5.具体实现
1.最终的对抗损失的最后输出,是使用了patchgan的损失思想,将最后生成的图片,进行缩放成N*N大小的patch,其中每一个值都表示对于对应原图块是否是real or fack 的判断,你可以理解为,一张图片,分割成N*N 大小,对每一块,进行判断是否是real的一部分,可以说是对每一个块,使用了二分交叉熵,使得这个每个单元都是在0-1之间。另外其中的网络设计还是看源码比较实在。
2.最终使用的Gan 损失,最终的损失函数没有使用二分交叉熵损失,而是使用了以下公式,且效果更好:

其实际上还是逃不过本质就是让判别器和生成器在各自优化的时候都变得更强。
3.在训练时注意的细节
为了防止在训练的时候出现震荡,在跟新D的时候,使用历史的生成图片而不仅仅使用最新的生成图片。其他的超参数细节详见论文。
6.评估
使用了两种评估方式:
1.AMT评估
AMT感知评估,就是Amazon Mechanical Turk (AMT) 一个众包公司,让参与者来进行对图的识别。
25个参与者每次对一个算法进行测试,且每次测试只测以对图片,一张真图,一张假图,让其选择一张认为是真的图。首次10张是热身测试,让参与者回复是真还是假,然后40此之后,来进行算法真实性的评估。
2.FCN score
FCN 是一个现有的算法,通过这个算法来评估本算法生成的语义标签图,并拿这个和真实样本进行比较,产生一定的评估说明数据。
7.应用
文中介绍了诸多应用
1.风格迁移,基于非成对数据
2.目标变换
3.季节变换
4.从绘图中还原照片
其中说明了,从绘图中还原照片,会出现颜色失真的问题,所以在这里引入了一致性损失,保持了颜色的一致性。

公式如下:

文中的直观解释是:
例如,在学习莫奈的绘画和Flickr照片之间的映射时,生成器经常将白天的绘画映射到日落期间拍摄的照片,因为这种映射在对抗性损失和循环一致性损失下可能同样有效。
所以需要对应的一致性损失对颜色进行约束。
8.限制和讨论
1.图像目标变换任务中,对于颜色和纹理改变容易取得成功
2.难点在于几何图形的变换上有较大问题。

3.针对最右边一列的人骑马图片的问题,在于由于训练的分布特征性,存在了很大的影响,因为训练中没有存在人骑着马的照片,导致最终的效果会出现这样的情况。
4.本文方法在由于 使用 unpair method ,所以有时会长生不明确的结果 如 photo->label ,这个label不一定就是确定的,可能会有所偏差,为了解决这种问题,可能需要简单的语义监督 。当然有监督的环境当然在转移是最有效的。本文拓展了在这种“无监督”环境中可能实现的边界。