前言
本文中所使用的cGAN模型为上篇论文的main idea,这里再进行一下相关介绍。
题目
Image-to-Image Translation with Conditional Adversarial Networks
使用条件对抗网络实现图片到图片的翻译
摘要
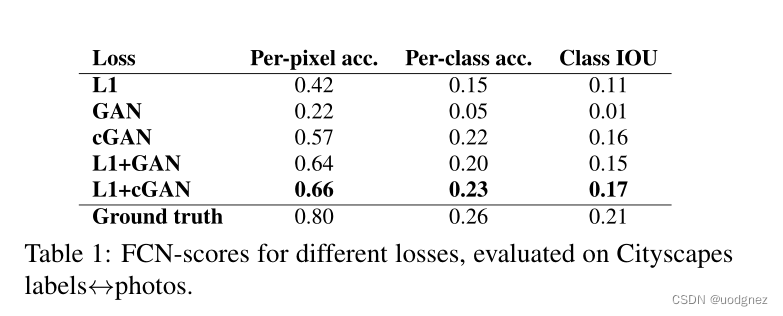
我们研究了条件对抗网络作为图像到图像翻译问题的通用方案。这些网络不仅学习从输入图像到输出图像的映射,而且还学习一个损失函数来训练这种映射。这使得我们有可能将同样的通用方法应用于传统需要非常不同的损失公式的问题上。我们证明了这种方法在从标签图合成照片、从边缘图重建物体和给图像着色等任务中是有效的。
引言
图像处理、计算机图像学和计算机视觉中的许多问题都可以被设定为将输入图像“翻译”成相应的输出图像。就像一个观点可以用英语或法语表达,或一个场景可以被渲染成一个RGB图像,一个梯度场,一个边缘图,一个语义标签图等等。与自动语言翻译类似,我们将自动图像到图像的翻译定义为:在给定足够的训练数据的情况下将场景的一种可能表示翻译成另一种可能表示翻译成一种可能表示问题,如下图所示。
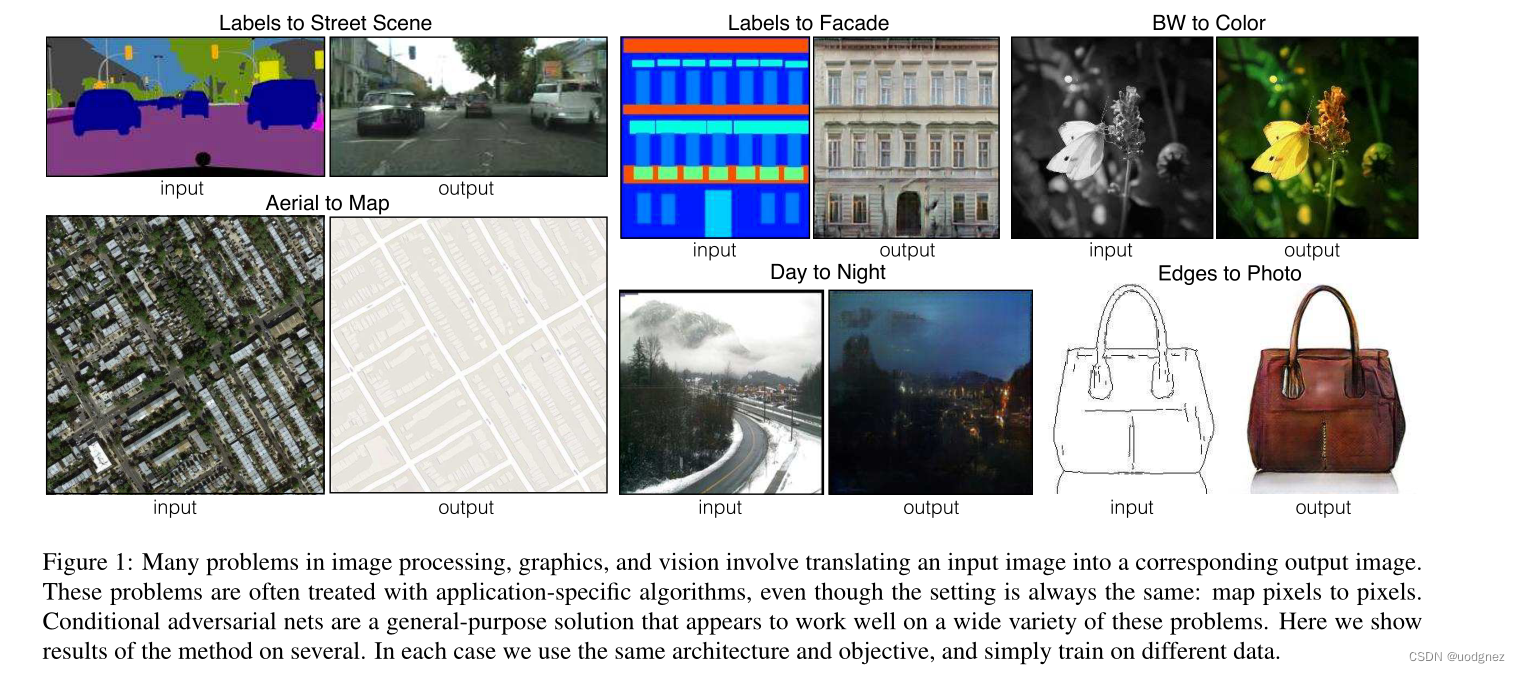
本文的目标就是为这些问题制定一个共同的框架。
方法
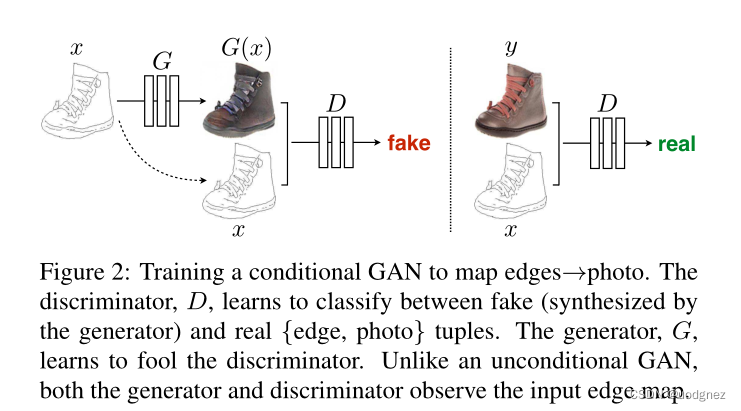
训练一个cGAN来实现从边缘到图像的映射。鉴别器学会在假的(生成器合成)和真的{边缘,图像}图元之间进行分类。生成器学会如何欺骗鉴别器。与无条件的GAN不同的是,生成器和鉴别器都观察输入的边缘图。
损失函数:
L c G A N ( G , D ) = E x , y [ log D ( x , y ) ] + E x , z [ log ( 1 − D ( x , G ( x , z ) ) ) ] \mathcal{L}_{cGAN}(G,D)= \mathbb{E}_{x,y}[\log D(x, y)] + \mathbb{E}_{x,z}[\log (1-D(x,G(x,z)))] LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
另外对于生成器,还考虑了L1损失。
L L 1 ( G ) = E x , y , z = [ ∥ y − G ( x , z ) ∥ 1 ] \mathcal{L_{L1}}(G) = \mathbb{E}_{x,y,z}=[\lVert y- G(x,z) \rVert_1] LL1(G)=Ex,y,z=[∥y−G(x,z)∥1]
可以帮助输出更接近ground truth。
最终的目标函数为:
G ∗ = arg min G max D L c G A N ( G , D ) + λ L L 1 ( G ) G^* = \arg \min_G \max_D \mathcal{L}_{cGAN}(G, D) + \lambda \mathcal{L}_{L1}(G) G∗=argGminDmaxLcGAN(G,D)+λLL1(G)
尽管没有 z z z,网络仍然可以学习从 x x x到 y y y的映射,但会产生确定的输出,因此无法匹配除 delta函数以外的任何分布。过去的cGAN已经认识到这一点,除了 x x x之外,还提供高斯噪声 z z z作为发生器的输入。
相反,对于本文的最终模型,我们提供的是dropout形式的噪声。
生成器架构:使用了带有“编码器-解码器”结构的U-Net框架。具体来说,在每个层 i i i和层 n − i n-i n−i之间添加skip结构, n n n为总层数。每个skip结构只是将第 i i i层和第 n − i n-i n−i层的结果通过通道数连接起来,即concat。
鉴别器架构:patchGAN。这个鉴别器试图对图像中的每个 N × N N \times N N×N补丁进行分类,以确定是真是假。我们在整个图像上卷积地运行整个鉴别器,对所有的反应进行平均,以提供最终的输出 D D D。
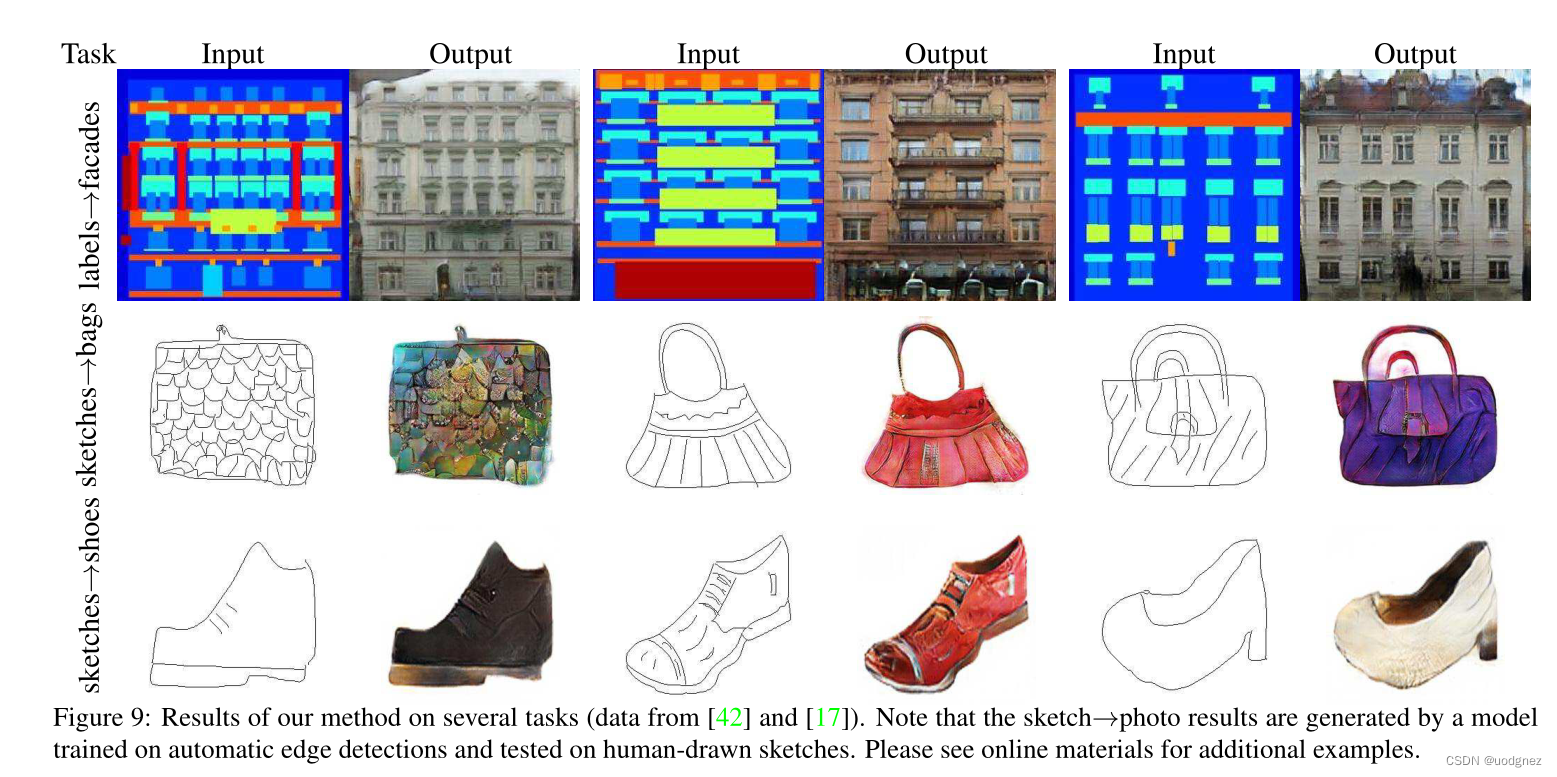
实验