Image-to-Image Translation with Conditional Adversarial Networks
(基于条件gan的图像转图像)
作者:Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
全文链接:https://arxiv.org/abs/1611.07004
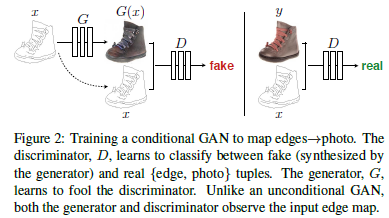
GANs是一种生成模型,它学习从随机噪声向量z到输出图像y的映射。条件GAN学习从观测图像x和随机噪声向量z到y的映射。生成器G经过训练后产生的输出不能通过反向训练的判别器D从“真实”图像中分辨出来,D经过训练以尽可能好地检测生成的“赝品”。这个训练过程如图2所示。
条件GAN的目标可以表示为:

在对抗中,G试图将这个目标最小化,D试图使它最大化,G* = arg minG maxD LcGAN(G;D).
鉴别器的工作保持不变,但生成器的任务不仅是欺骗鉴别器,而且在L2意义上接近真值输出。基于这个需求,使用L1距离而不是L2作为参数。L1鼓励减少模糊。
目标函数变为:
生成器和鉴别器都使用卷积-BN处理- relu格式的模块。Pix2pix网络能够让图像和目标图像的像素值一一对应。
生成器采用Unet结构,跳层连接的方式。

马尔可夫链的鉴别器(PatchGAN):给高频信息更高的关注,关注局部图像块。将判别器设计为对块进行单独判别的结构。判别器对于每张图片的判断,都将图片分割为N*N的块,判断这个N*N的图形块是生成的图形或者是真实图像。我们通过对图像进行卷积来运行这个鉴别器,对所有响应进行平均,从而得到D的最终输出。一个较小的PatchGAN的参数更少,运行速度更快,可以应用于任意大的图像。
假设像素之间的独立距离大于一个patch的直径,这种鉴别器可以有效地将图像建模为一个马尔可夫随机场。
为了优化网络,遵循标准方法:在D上的梯度下降步骤和G上的梯度下降步骤之间交替进行。