摘要
车道检测是检测道路上的车道线,提供车道线的精确位置和形状。它在现代高级辅助驾驶系统(ADAS)和自动驾驶系统中是非常关键的技术。但是,车道检测的一些特性使它充满了挑战。缺乏显著的特征使车道检测算法往往很容易混淆其他具有相似外观的物体。而且还有不一致的车道数量,多种多样的车道线样式,比如实线、残缺的车道线、单线、双线、并线和叉线,这些都阻碍了系统性能的提升。在这篇论文中,我们提出了一种深度神经网络LaneNet, 把车道检测分为两个阶段:车道边缘提议和车道定位。第一个阶段使用车道边缘提议网络来完成逐像素的车道边缘分类;第二阶段在车道边缘提议上来完成车道定位。注意到我们的目标如果仅仅只是检测车道的话,会给减少错误检测如检测到了马路上的箭头和字符带来很大的困难。尽管有这么多的困难,我们的车道检测依然对高速和城区道路检测具有非常好的鲁棒性,不依赖车道数量和车道模式的任何假设。较高的计算速度和较低的计算开销使我们的LaneNet可以部署到实际车辆系统中。试验证明我们的LaneNet在真实的交通场景中表现出了非常好的性能。
1.介绍
用于车道检测的光学图像在现代驾驶辅助系统中是重要的组成。但是,因为一些原因车道检测依然充满挑战。一,车道的外观往往非常简单,没有给检测提供复杂显著的特征,反而急剧增加了false positive检测的风险。另外,多种多样的车道线样式,比如实线、残缺的车道线、单线、双线、并线和叉线使得单独的车道建模非常困难。基于特征工程的算法只能解决有限场景下的车道检测。大多数结果比较好的方法都对车道有非常强的假设,比如车道线平行【1,8,14,3】、车道笔直或近似于直线【11,15】,这些假设并不总是有效的尤其在城区场景下。在最近一些年,一些方法【20,6】被提出来解决少量车道数假设下的车道检测,但是对于多样化的真实场景,这些方法依然有很大需要提升的地方。基于深度神经网络的方法【7,10,4】,尤其是卷积神经网络促发了一个非常有前景的研究方向,也激发我们的LaneNet的创意。另外,考虑到运行在实车系统上的车道检测,往往计算资源非常有限,车道检测的计算开销也应该是整体性能的一个重要指标。
在这篇论文中,为了具有通用性,低计算开销,实时真车检测,我们提出了一个叫做LaneNet的车道检测方法。我们提出的LaneNet把车道检测分为两个阶段,分别是车道边缘提议和车道定位。在车道边缘提议的阶段,为了生成车道边缘提议把它作为第二阶段车道定位的输入,提议网络在输入图像每个像素上进行一个二分类。
两个阶段的神经网络都要求高精度、低计算开销、高运行速度。因此,一个轻量化的编码解码架构被车道边缘提议网络所采用,其中不断堆叠了depthwise separable convolution层和1×1卷积层,来实现快速的特征编码。非参数化的解码层是为了实现快速的feature resolution recovery。获得的提议map再被转化为车道边缘坐标,输出到第二阶段。第二阶段一个高速的车道定位网络,包含一个点特征编码器和一个LSTM解码器,用来在多种场景下完成稳定性比较高的车道定位。
LaneNet如此的二阶段设计带来我们所期待的特性。首先,通过提议网络产生的车道边缘map作为可理解的中间特征,在一定层度上减轻了神经网络的黑箱特性,使检测失败更容易被追溯。二阶段的过程可以使车道定位网络的参数可以在一种弱监督的方式下进行调整,减轻了对良好标注的训练样本的要求。 另外,当车道边缘提议转换为车道边缘坐标的时候,也进行了一种有效的降维,这进一步减少了复杂度和定位网络的大小,在没有牺牲准确率的情况下提升了检测速度。还有一点车道边缘提议网络的功能可以进一步整合到实例分割网络中去,进一步减少了驾驶辅助系统的开销。
所有上面提到的的这些优点构成了自动驾驶系统和辅助驾驶系统中的一个鲁棒可靠的车道检测系统。大量的试验和比较也证明了我们LaneNet作为具有非常好的准确率、速度、有效性。
论文的剩余部分结构如下:Section2 简要描述我们模型的结构,Section3提供了了训练数据和训练过程的细节,Section4展示了实验和结果,Section5提供了一个对其它车道检测方法简短的总结,Section6论文总结。
2.车道提议和定位网络
在这部分,我们首先简要描述两种一起在多样化场景下完成车道检测的神经网络。第一个提议网络检测车道边缘,产生一个逐像素的车道边缘proposal map。第二个定位网络基于车道边缘提议检测车道位置和形状。在【1】的工作之后,我们的LaneNet只用输入图像的Inverse Perspective Mapping作为输入,它可以帮我们避免减少图像的perspective effect,因此看起来水平相交的车道线现在变得垂直和平行。我们的LaneNet不依赖任何车道平行的假设,所以鲁棒性得到保证。这两个网络在车道检测中扮演着不同的角色,但是它们却有相似的设计原则。首先,不同于那些运行在计算中心和服务器上的网络,车道检测运行在在车辆上,所以计算开销要尽可能小,而且检测时应该满足实时决策的要求。另外,在多样化的场景中预测准确率和鲁棒性非常重要。LaneNet的性能和如何满足上述提到的这些要求在这部分中提到了。
2.1 车道边缘提议网络
为了过滤光学图像中不相干的信息,我们首先通过一个车道边缘提议网络将图片生成一个binary lane edge proposal map指出位于车道边缘区域像素的位置。我们使用深度神经网络而不是特征工程来生成proposal maps 是因为难以找到一个或一组鲁棒的人为设计好的特征来从输入图像中过滤车道线。Figure 2展示了一个典型的车辆前向视角的IPM 图像。为了在每个像素上得到准确的车道边缘提议,纹理信息包括整体外观应该被充分考虑以减少因为相似外观造成的false positive detection。深度卷积神经网络成为了一个理想的工具,因为它强大的特征提取能力。
Encoder-Decoder结构被广泛使用在密集检测任务上,比如实例分割【12,17, 2】,它充分利用了卷积层和反卷积层(transpose convolution layer)来进行特征编码和解码。为了达到更高的效率,我们的车道提议网络采用了一个轻量化的Encoder-decoder结构。解码器逐步地恢复了特征图的分辨率,产生了逐像素的车道边缘proposal map。
Encoder 提议网络的编码器通过depthwise separable convolutions 和pointwise convolutions(1×1卷积)代替了标准的卷积操作,显著降低了计算开销【5】。3×3的卷积核的Depthwise separable convolutional layers堆叠来完成逐步的特征提取。每一个depthwise separable convolutional layer 后面跟着一个1×1卷积层来完成逐通道的信息聚合。图像上存在很多与车道线具有相似局部外观的物体,为了防止false positive detections, 在编码阶段纹理信息应该被合适地提取和保存。为了增大编码器的感受野同时保证较低的计算开销,我们在Encoder layers采用dilated convolutional kernel。在这三个depthwise separable convolution层,第一个膨胀率为1,是一个标准的separable convolution,其余两层膨胀率为2和4,增大了感受野。引入dilated kernels成功地提高了有效感受野,没有产生额外的参数和计算开销,合理地平衡了效率和功能性。
Decoder 为了恢复特征分辨率和产生输入图像的逐像素的车道边缘map,我们在编码器后面设计了一个解码器结构。反卷积层(transpose convolutions layers)在现在的深度神经网络中被广泛地使用在增大中间特征。但是,计算开销和训练难度使反卷积层在我们的模型中成为一个不合适的选择。受到在图像超分辨率中亚像素(sub-pixel)卷积层的启发【18】,我们这里在我们的模型中为了逐步恢复特征分辨率采用了亚像素卷积。它有一系列的好处:包括完全没有参数和计算开销,正是我们的车道检测所想要的。Skip connections被用来提供高分辨率的特征,以完成高分辨率的车道边缘定位。最后的高分辨率的特征图再用来生成逐像素的属于车道边缘的概率,每个像素点的值指出了网络预测输入图像中这一个像素点位于车道边缘区域的置信度。
2.2车道定位网络
车道边缘提议网络将一幅图像映射到与之相联系的车道边缘提议map(带有车道边缘的二值图像)。从车道边缘提议map检测车道仍然具有一定的复杂性。我们的车道线定位网络依然采用了编码解码结构。它用车道边缘的坐标作为输入,用一系列的1维卷积和池化操作将输入编码成一个低维的整体表示。一个基于长短期记忆网络(LSTM)的解码器被用来不断地将表示解码成图像里每一个车道的参数。
给定一个二值化的车道边缘map,我们使用车道边缘点的坐标而不是直接输入车道边缘map到车道定位网络中。如此的设计给我们带来两个好处:一输入的尺寸从w×h减少为n×2,n是二值图像车道边缘map中车道边缘点的个数。这种减少使得我们网络模型变得紧凑,预测变得快速;二输入中的坐标使得车道定位网络的弱监督训练方法成为可能,这一点在Section3.2中讨论。
除了这些好处,使用坐标而不是车道边缘map作为模型输入带来了一个额外的要求,那就是输入顺序不变性(?)。因为车道边缘点是从2维图像中进行采样,很难找到一个合适合理的规则去给这些点排序。考虑到在大部分情况中车道边缘点的位置可以决定车道数量和车道形状,我们模型的预测应该相对输入点的顺序是不变的,只有这样预测才能在输入点的顺序打乱时保持一致。受到最近点云神经网络模型PointNet(用来分析点云数据)的启发,在我们的车道定位网络中设计了一个输入顺序不敏感的编码器,将输入点编码成一个车道边缘的低维整体表示。为了实现对输入顺序的不变性,一个共享全连接层同时被用来实现对每个点特征的非线性映射。这可以通过一系列的1维卷积操作来实现,卷积核的尺寸与每一点的特征尺寸相同。最大池化层被用来整合所有点的特征,实现一个对输入顺序不敏感的全局信息融合。不同于PointNet网络的模型,我们没有使用任何针对输入或特征的变换,最大池化层使用了很多次,完成多个语义层下所有点的信息交流。我们对每一个点运用了一系列非线性特征提取,基于特征整合的池化,如编码器网络Figure 1b所展示的阶段。为了实现所有点之间有效的信息交流,这样的操作做了多次。对最终特征使用平均池化,可以展示出最终的表示。
在输入点的坐标被编码成一个低维的表示,我们采用了一个LSTM,作用是可以解决uncertain number of lanes和解码每一车道的参数。从图像的左边到图像的右边,我们用一个二次函数拟合图像中的每一车道,使用LSTM不断预测描述每一车道的参数和一个参数的置信度。当置信度低于某一个预先设置的阈值(指出没有车道了),预测结束。
3.训练
3.1车道边缘提议网络
在我们的模型中,采用一个车辆前向拍摄图片作为输入,输出一个与输入图片尺寸相同的车道边缘概率map。所有的参数完全在监督训练的方式下完成。对于每一个训练图片,我们提供一个标记map,用1指出这个像素点是一个位于车道边缘区域,0则表示相反。整个网络用随机梯度下降的方法进行优化。注意在每一个标记map中,正样本点的数量远少于负样本点的数量。所以在训练过程中,我们动态对正样本点和负样本点的损失根据它们相对数量的关系进行加权,损失函数如下:

在训练完成之后,网络直接产生一个输入的车道边缘map,每一个像素点的值指出该像素点位于车道边缘区域的置信度。
3.2车道定位网络
在我们的数据中,每一个车道线用一个二次函数来表示,如车道形状用三个连续数字来标记。实际当中,训练网络来预测每一个二次函数的参数效果很差,因为每一个参数的数量级数量级通常都是不同的。如一个车道线的二次项可能近似于0,但是常数项比二次项大数千倍,这会使损失函数的构造非常困难。简单地归一化这些参数可能会导致比较差的性能。因此为了解决这个问题,我们训练一个网络预测点的位置,这些位置包括车道与图像的底部,顶部,中线的交点。Figure3展示了我们构造一个车道训练目标。输入图像尺寸h×w,所以我们训练我们的网络预测这三个车道线与图片交点x坐标的值,因为已经知道它们的Y=0,Y=h/2,Y=h。通过将训练目标从二次函数的参数转换为三个交点x坐标的值,预测值的数量级将会比较接近,也因此训练变得比较平稳,也防止收敛到bad local minimum。一个简单的矩阵乘法可以直接将二次函数的参数转换为三个交点x坐标的值(??):

尽管是在一种完全监督训练方式下训练一个车道定位网络,我们可以平均一下预测关键值(三个x坐标值)和实际关键值的L2距离作为每一车道的损失函数,使用随机梯度下降最小化L2距离。
更进一步,使用车道边缘坐标作为网络输入带来一个额外重要的好处。考虑到使用二次函数标注每一车道的较大的成本,任何不准确的标注都会影响训练结果,我们给车道定位网络设计了一个弱监督训练的方法,只要求图像中车道数量作为真实值,我们这种形式的损失为the min-distance loss。当使用min-distance loss,损失函数是通过计算每一个输入点和最近估计线的距离和。
当使用min-distance loss训练网络时,网络输出依然是车道的关键值。在我们预测车道关键值之后,我们把它转换与之想联系的二次函数代表估计的车道:
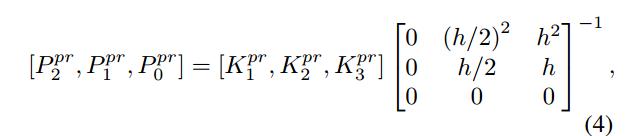
这给我们一系列的估计出来的二次函数。正如上面所提到的,网络的输入是车道边缘点的坐标。现在我们把X点的坐标值变成要估计的二次函数,这将让我们得到由此得到的车道点的Y 坐标。真实的Y值和映射得到的Y值的绝对距离使我们估计车道点上水平距离。理想上我们把所有点到离它最近的车道线的水平距离最为损失,最小化损失函数可以使预测的车道线变成真实车道线的中心。
这种弱监督的训练方式仅仅需要车道数最为一种监督,所以它显著地减少了标注的成本。实践中只使用min-distance loss从零开始训练会导致模型陷入局部最小值。所以我们不得不在一开始使用监督学习的方式。我们提出两种方式采用min-distance loss 来训练模型。一当训练模型的时候,我们训练网络去最小化L2 loss和min-distance loss:

根据我们的观察,同时最小化两种损失函数成功地克服了标注的不准确性,使得估计的车道可以准确地拟合图像中的车道,不管标记车道和真实车道是否存在较小地不对齐现象,也提高了泛化能力。
在网络被标注的很好的样本训练之后,我们可以进一步通过只有车道数量的弱标注样本来调整我们的网络。因为网络已经开始被优化了,只使用min-distance loss来调整网络不会导致我们学习模型性能变坏,也可以进一步对我们网络参数进行调优。
4.试验
我们在真实的交通数据中测试我们的LaneNet。我们比较我们的方法和其它的车道检测方法,评估网络性能。我们的数据包含超过5000个标注好的在高速路和城区道路采集到的前景图像。对于数据集中的每一张图片,我们标注所有车道区域的边缘,通过一个二次函数拟合每一个车道。我们从数据集中选出600个样本作为测试集,然后使用剩余的数据来训练我们的LaneNet网络。特别地,测试集根据难度分为两个子集。
我们采用广泛使用的评估性能和两种标准:the true positive rate(TPR), TPR=(the number of detect lanes)/(the number of target lanes), false positive rate(FPR), FPR=(the number of false positives) / (the number of target lanes)。每一个车道应该被检测到一次,所以总车道数的over estimation和under estimation不是我们想要的,比如多次检测到虚线车道导致一个高的FPR,将叉线检测为一条线将会降低TPR。我们选择【6】中车道检测方法来与我们的方法进行比较,因为它也依赖少量假设,【6】的代码可以在1中公开利用。表1显示了比较结果。

我们LaneNet的监督训练设置:车道边缘提议网络使用完全监督训练方式训练在所有训练数据熟练。弱监督训练是在训练车道定位网络中引入。额外的弱标注训练样本(大约1000图像中只有车道数标注的样本)被用来对车道定位网络的参数进行调优。
Figure4展示了检测结果,所有的预测从IPM图片转换回原始图片。我们转换所有在IPM图片上的预测结果为原始图片上为了更清晰地说明。车道边缘提议网络对所有道路上的其他物体都具有鲁棒性,比如车道标识和其它车辆,我们把这归功于基于车道边缘提议网络的深度神经网络环境信息提取能力,如对每一个样本,没有针对高速路上箭头的false positive检测,这表明我们的检测神经网络是基于较大的周围环境区域来做出决策,所以它对那些具有相似外观的物体具有鲁棒性。车道定位较为准确,不管车道的形状和车道数量是什么,这进一步证实了我们针对多样化场景的车道定位网络是有效的。虚线车道被合理地估计出来了,我们认为这归功于我们车道定位网络从一个全局角度估计车道边缘提议,而不是监督地对相邻的点进行聚类。
我们也进行了一个额外试验,通过运用弱监督损失函数和额外的弱标注样本来验证网络性能的提升。结果展示在表2。我们可以看到弱监督损失也同样地提升了简单和困难子数据集的检测性能。使用弱标注样本数据进一步调整网络可以使得困难子数据集上的检测性能明显提升。这种调优使得我们的模型在极端情况下的检测性能提升了,同时却没有产生太大的开销。
使用NVIDIA Titan Xp GPU,我们的车道边缘提议网络运行速度可以达到330帧每秒,车道定位网络是车道边缘提议网络的4倍,这使LaneNet处理图片的速度达到250帧每秒。当运行在一个嵌入式GPU平台,比如NVIDIA Jetson TX1,没有经过任何特定的修改速度可以达到26帧每秒,这已经可以满足实时检测要求。整个LaneNet模型大小被限定小于1GB。如此紧凑的模型和快的运行速度使我们可以将LaneNet部署在真车上。
5.相关工作
作为自动驾驶系统的关键环节,车道检测在近些年已经越来越被广泛使用了。尽管有真实强烈的需求,车道检测依然充满挑战。一个重要的原因就是缺乏显著的特征。为了解决这个,很多工作尝试去利用车道结构特征。Vanishing point被认为是车道检测的一个重要特征,已经在【9,16,19】中使用了。至于局部特征,车道边缘的梯度对于定位车道来说是一个很有利的工具,比如【6】中使用两个滤波器检测左右车道边缘,可以发现图片中非常明显的车道边缘。但是,这种基于检测梯度的检测方法是对于有复杂不相关物体的场景是很不可靠的。我们观察发现,当大量其它车辆出现在图片中,基于梯度的方法性能急剧下降,但是这在真实场景中却不可避免。
Alexandru Gurghian等提出了一个DeepLanes模型使用深度神经网络估计车辆两侧车道位置。Jun Li等使用了一个多任务卷积神经网络同时在一张图片的子块中检测车道标识是否存在和它的几何属性,但是这种基于子块的检测方法很难推断出马路上车道线的全局结构,因此不能给导航提供决策信息,所有他们提出进一步联合卷积神经网络和循环神经网络去引入周围环境信息,做出结构化的预测。与我们的方法相似,Xue Li等提出使用神经网络检测车道线的边缘,再使用霍夫变换检测不同的车道,这样做针对不同复杂场景比如弯曲特别大的车道鲁棒性可能比较差。
一个全面的车道检测的最近进展的综述在【13】中可以找到。
6.结论
在这篇文章中,我们提出一种车道检测方法,它包含两个深度神经网络。车道边缘提议网络用车辆前向的IPM图片作为输入,生成一个车道边缘提议map。得到车道边缘map后,车道定位网络再被用来推断图片中每一车道的位置。我们的车道检测方法不用依赖任何先验假设,也可以应用到多种不同场景。使用深度神经网络使我们的方法鲁棒性非常好,两阶段的检测减少了计算开销,我们的网络也可以联合监督和弱监督训练的方式一起训练,这极大地减少了标注训练数据的成本。进一步的工作将会引入车道跟踪到我们的LaneNet,形成一个更稳定的基于视频的车道检测方法。