前言:YOLO V3作为YOLO系列文章的第三篇,是YOLO系列文章的巅峰,也是现在使用最为广泛的YOLO系列算法,完全比肩SSD系列算法,yolo的v1和v2都不如SSD算法,原谅这么直白,原因是v1版本的448和v2版本的416都不如SSD的300,当然以上结论都是实验测的,v3版本的416应该比SSD512好,可见其性能。那么现在来看一看YOLO V3在原来的YOLO系列上究竟有哪些改变呢?
一、YOLO V3的背景
二、YOLO V3的改进点
2.1 类别预测方面主要是将原来的单标签分类改进为多标签分类(softmax->logistic)
2.2 YOLO v3采用多个scale融合的方式做预测——predictions across scales
2.3 backbone网络架构完全不一样(darknet-19->darknet-53)
三、YOLO V3的网络架构
3.1 YOLO V3的架构概览
3.2 YOLO V3和YOLO V2的 backbone3.3 YOLO V3的输出——predictions across scales(即多尺度预测)
3.4 为什么要用逻辑回归——为了找寻objectness score(目标性评分)最大的那个box
四、YOLO系列和RCNN系列的简单对比
一、YOLO V3的背景
YOLO V3出自论文《YOLOv3: An Incremental Improvement 》
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
1.1 YOLO系列算法的基本思想
(1)首先通过特征提取网络对输入图像提取特征,得到一定size的feature map,比如13*13;
(2)然后将输入图像分成13*13个grid cell,接着如果ground truth中某个object的中心坐标落在哪个grid cell中,那么就由该grid cell来预测该object;
需要注意的是每个grid cell都会预测固定数量的bounding box(YOLO v1中是2个,YOLO v2中是5个,YOLO v3中是3个,这几个bounding box的初始size是不一样的),那么这几个bounding box中最终是由哪一个来预测该object?答案是:这几个bounding box中只有和ground truth的IOU最大的bounding box才是用来预测该object的。
有上面的分析可得,在最后的feature map上面,比如13*13,每一个cell的输出为:B*(5+C),注:YOLO v1中是(B*5+C),其中B表示每个grid cell预测的bounding box的数量,比如YOLO v1中是2个,YOLO v2中是5个,YOLO v3中是3个,C表示bounding box的类别数(没有背景类,所以对于VOC数据集是20),5表示4个坐标信息和一个置信度(objectness score/confidence score)。
二、YOLO V3的改进点
2.1 类别预测方面主要是将原来的单标签分类改进为多标签分类(softmax->logistic)
网络结构上就将原来用于单标签多分类的softmax层换成用于多标签多分类的逻辑回归层。首先说明一下为什么要做这样的修改,原来分类网络中的softmax层都是假设一张图像或一个object只属于一个类别,但是在一些复杂场景下,一个object可能属于多个类,比如你的类别中有woman和person这两个类,那么如果一张图像中有一个woman,那么你检测的结果中类别标签就要同时有woman和person两个类,这就是多标签分类,需要用逻辑回归层来对每个类别做二分类。逻辑回归层主要用到sigmoid函数,该函数可以将输入约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就表示属于该类。
YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个:
- Softmax使得每个框分配一个类别(score最大的一个),而对于
Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。 - Softmax可被独立的多个logistic分类器替代,且准确率不会下降。
分类损失采用binary cross-entropy loss.
2.2 YOLO v3采用多个scale融合的方式做预测——predictions across scales
原来的YOLO v2有一个层叫:passthrough layer,假设最后提取的feature map的size是13*13,那么这个层的作用就是将前面一层的26*26的feature map和本层的13*13的feature map进行连接,有点像ResNet。当时这么操作也是为了加强YOLO算法对小目标检测的精确度。
有一个概念叫做:bounding box prior,其实就是实现聚类得到的几个检测边框,YOLO V2和YOLO V3均采用了这种方式,但是又有所不同。
关于bounding box的初始尺寸还是采用YOLO v2中的k-means聚类的方式来做,这种先验知识对于bounding box的初始化帮助还是很大的,毕竟过多的bounding box虽然对于效果来说有保障,但是对于算法速度影响还是比较大的。作者在COCO数据集上得到的9种聚类结果:(10*13); (16*30); (33*23); (30*61); (62*45); (59*119); (116*90); (156*198); (373*326),这应该是按照输入图像的尺寸是416*416计算得到的。
回顾前面的YOLO V2是怎么做的,YOLO V2一共有13*13个cell,每一个cell预测5个候选框,故而总的Box数目为:
13*13*5.
但是由于YOLO V3采用了多个不同的尺度的特征图,每一张特征图上均采用3个候选框,
对于13*13的特征图,有13*13*3;
对于26*26的特征图,有26*26*3;
对于52*52的特征图,有52*52*3;
很明显,YOLO V3的措施单从数量上来说就已经比V2版本多了很多,不仅如此,由于V3版本特征图的尺度是不一样的,而且应用在每一个特征图上的候选框的大小也是不一样的,这样对于不同尺寸的目标的适应能力自然更强了。
补充,YOLO V3的精简版tiny-darknet采用的 bounding box prior是6个。
2.3 backbone网络架构完全不一样(darknet-19->darknet-53)
YOLO V2采用的是darknet-19,而YOLO V3采用的是darknet-53,二者的设计也有很多不一样的点,主要特现在以下几个方面:
(1)darknet-53中无池化层,全连接层,特征图的缩小是通过增加卷积核的步长实现的;一方面基本采用全卷积(YOLO v2中采用pooling层做feature map的sample,这里都换成卷积层来做了)
(2)darknet-53中 CNN Kernel+BN+LeakyRelu 成为了标准组件;
(3)darknet-53采用了残差的设计思想;
三、YOLO V3的网络架构
3.1 YOLO V3的架构概览
下面的这张图来自于一位大神的博客,博客地址如下:
https://blog.csdn.net/leviopku/article/details/82660381
个人感觉这张图对于理解YOLO V3的结构非常有帮助,所以拿过来了。
上面的结构图中,有三个基本的组件
(1)DBL: 如图左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
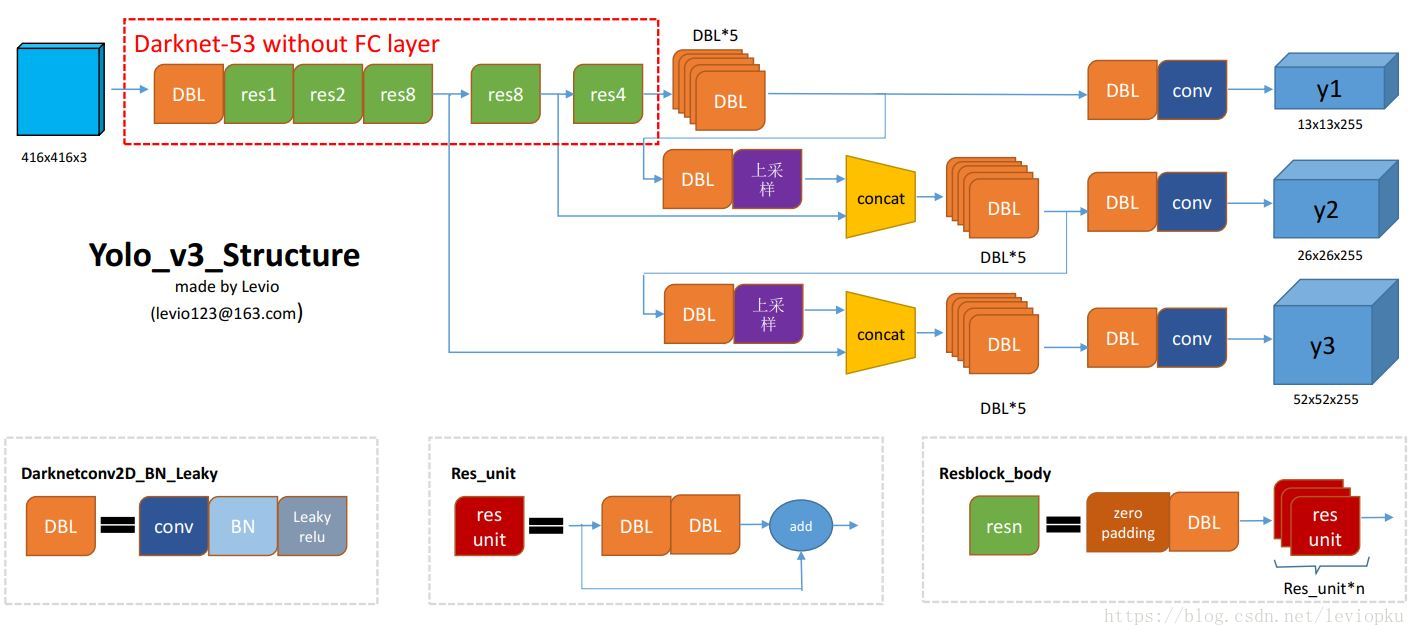
(2)resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,其基本组件也是DBL,DBL也是其中的一个小组件。
(3)concat:张量拼接。将darknet中间层和后面的某一层经过上采样之后进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
至于为什么要进行拼接,这里在前面的改进地方已经给出了解释,就是为了对不同尺寸的目标进行特征提取,从而增大对小目标的识别能力,这也是YOLO V3相较于V2版本的一大改进。
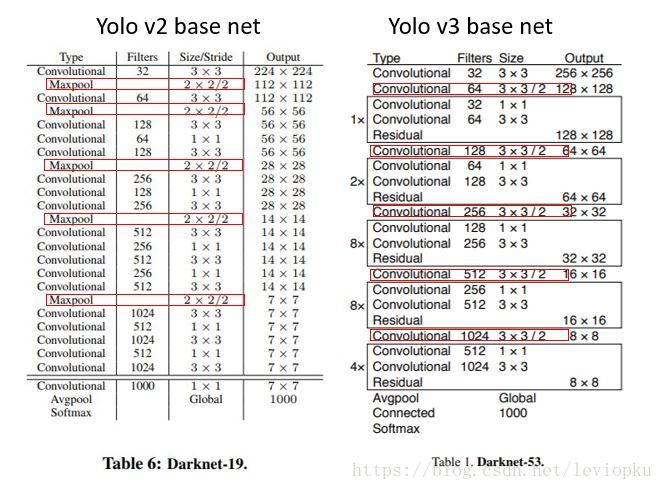
3.2 YOLO V3和YOLO V2的 backbone
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的2的5次方分之一,即1/32.若输入为416x416,则输出为13x13(416/32=13)。
yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32。所以,通常都要求输入图片是32的倍数。可以对比v2和v3的backbone看看:(DarkNet-19 与 DarkNet-53)
从上面的backbone中发现,yolo_v2中对于前向过程中张量尺寸变换,都是通过最大池化来进行,一共有5次。而v3是通过卷积核增大步长来进行,也是5次。(darknet-53最后面有一个全局平均池化,在yolo-v3里面没有这一层,所以张量维度变化只考虑前面那5次)。
这也是416x416输入得到13x13输出的原因。从上图可以看出,darknet-19是不存在残差结构(resblock,从resnet上借鉴过来)的,和VGG是同类型的backbone(属于上一代CNN结构),而darknet-53是可以和resnet-152正面刚的backbone。
补充:YOLO V3的结构稍微显得复杂,除此之外,还有一个更加轻量化的版本tiny-darknet作为backbone可以替代darknet-53,在官方代码里用一行代码就可以实现切换backbone。搭用tiny-darknet的yolo,也就是tiny-yolo在轻量和高速两个特点上,tiny-yolo模型非常小,大约只有4M左右,基本上和SqueezeNet不分上下。
3.3 YOLO V3的输出——predictions across scales(即多尺度预测)
上面的结构图中所显示出来的YOLO V3的输出为:
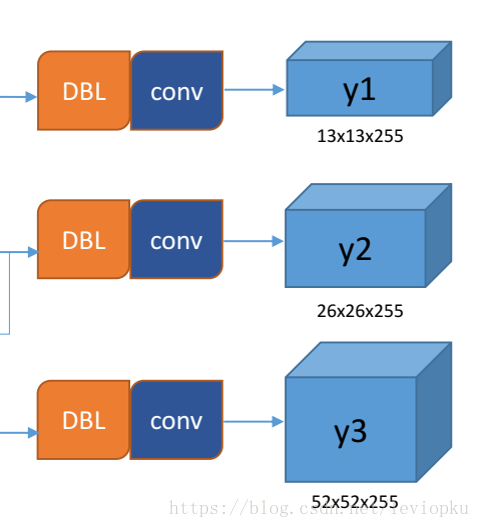
从上面yolo v3输出了3个不同尺度的feature map,如上图所示的y1, y2, y3。这也是v3版本中相较于V2版本最大的一个改进点之一,也正是这个改进点,使得V3在小目标的检测中有了更好的进展。
什么是predictions across scales(多尺度预测)?
这个借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
y1,y2和y3的深度都是255,边长的规律是13:26:52。对于COCO类别而言,有80个种类,所以每个box应该对每个种类都输出一个概率。
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3*(5 + 80) = 255。这个255就是这么来的。(还记得yolo v1的输出张量吗? 7x7x30,只能识别20类物体,而且每个cell只能预测2个box)
yolo v3用上采样的方法来实现这种多尺度的feature map,可以结合上面的结构图来看,图中concat连接的两个张量是具有一样尺度的(两处拼接分别是26x26尺度拼接和52x52尺度拼接,通过(2, 2)上采样来保证concat拼接的张量尺度相同)。作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为feature map。为什么这么做呢? 这个地方也不明确缘由,但是有一点可以确定的是,这样做的检测效果确实是更好了。
3.4 为什么要用逻辑回归——为了找寻objectness score(目标性评分)最大的那个box
每个anchor prior(名字叫anchor prior,但并不是用anchor机制)就是两个数字组成的,一个代表高度另一个代表宽度。
yolo v3对b-box进行预测的时候,采用了logistic regression。这一波操作sao得就像RPN中的线性回归调整b-box。v3每次对b-box进行predict时,输出和v2一样都是(tx,ty,tw,th,to ),然后通过公式1计算出绝对的(x, y, w, h, c)。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
如果模板框不是最佳的即使它超过我们设定的阈值,我们还是不会对它进行predict。不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模。
四、YOLO系列和RCNN系列的简单对比
(1)统一网络
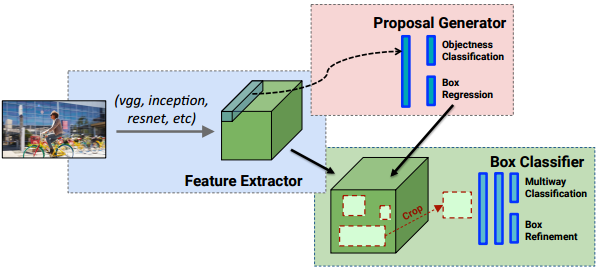
YOLO没有显示求取region proposal的过程。Faster R-CNN中尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络.相对于R-CNN系列的"看两眼"(候选框提取与分类,图示如下),YOLO只需要Look Once.
(2)YOLO统一为一个回归问题
而R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。