2023年,YOLO系列已经迭代到v8,v8与v5均出自U神,为了方便理解,我们将通过与v5对比来讲解v8。想了解v5的可以参考文章yolov5。接下来我将把剪枝与蒸馏的工作集成到v8中,大家可以期待一下。如果有什么不理解的地方可以留言。
首先,回归一下yolov5:
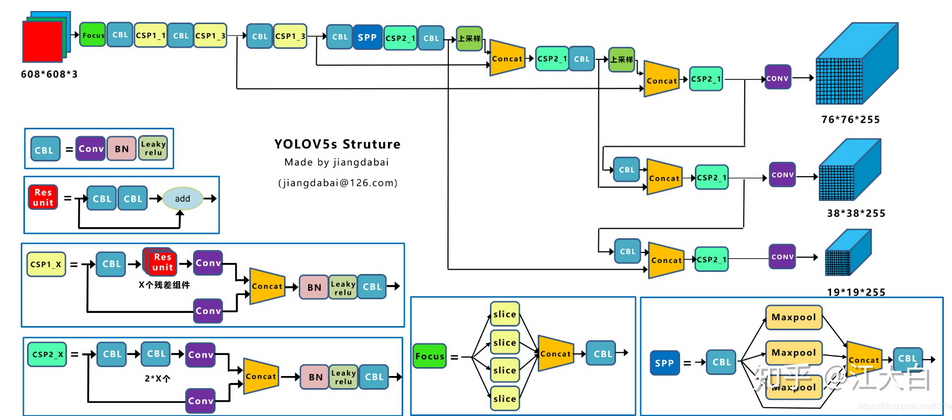
- Backbone:CSPDarkNet结构,主要结构思想的体现在C3模块,这里也是梯度分流的主要思想所在的地方;
- PAN-FPN:双流的FPN,这里除了上采样、CBS卷积模块,最为主要的还有C3模块;
- Head:Coupled Head+Anchor-base,YOLOv3、YOLOv4、YOLOv5、YOLOv7都是Anchor-Base的
- label assignment:多正样本参考点,采用shape匹配规则,分别将GT的宽高与anchor宽高求比值,比值小于阈值,认定为正样本点;
- Loss:分类用BEC Loss,回归用CIoU Loss。还有一个存在物体的置信度损失,总损失为三个损失的加权和。
yolov8具体改进如下:
- Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的CBS 1*1的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:YOLOv8使用了Decoupled-Head;即通过两个头分别输出cls与reg的输出;
- Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- Loss:YOLOv8使用VFL Loss作为分类损失(实际训练中并未使用),使用DFL Loss+CIOU Loss作为分类损失;
- label assignmet:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
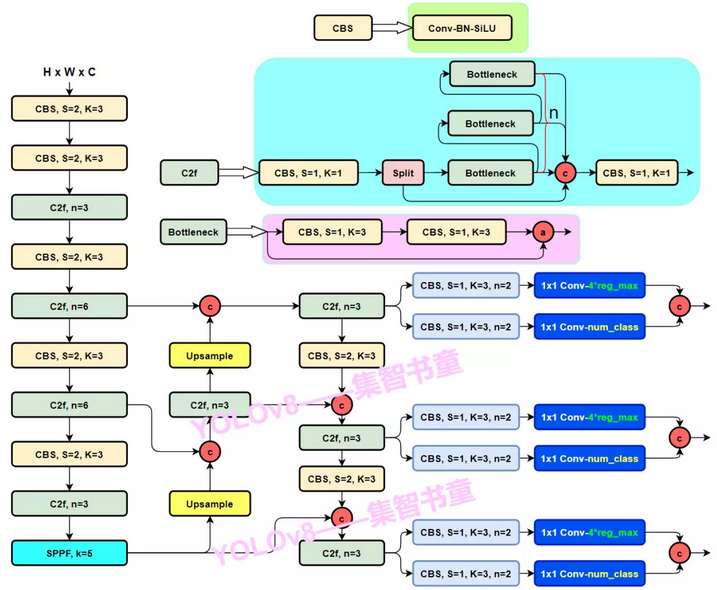
了解yolo的朋友看完上面的对比应该对v8的结构有了大致的了解,最主要的更新就是c2,c2f结构,以及在Detect中将cls与reg解耦,并使用dfl的积分求取reg。dfl是GFL的一部分,不理解的可以参考GFL。
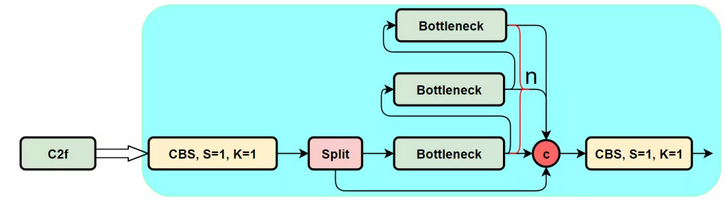
c2f
C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是残差模块。结构如下图所示。

为了进一步轻量化,v8设计了c2f结构,与c3相比,少了一层conv,采用split将特征分层,而不是conv。
class C2(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), 1)
return self.cv2(torch.cat((self.m(a), b), 1))
Decoupled-head
而YOLOv8则是参考了YOLOX和YOLOV6,使用了Decoupled-Head,即使用两个卷积分别做分类和回归,同时由于使用了DFL 的思想,因此回归头的通道数也变成了4*reg_max:
如代码所示,其中reg是由cv2输出,cls由cv3输出,yolov8与v5一样有3个特征层(8,16,32倍下采样),通过for x in ch 遍历特征层。gfl在coco中做了实验,一般instance距离中心点的距离在8,16,32下采样下不会超过16个像素,因此self.reg_max设置为16。
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
label-assignment
v8最重要的更新是采取anchor-free的方式,并学习TOOD使用Task-Alignment learning对齐cls与reg任务,那么下面我们对tood的label assignment进行详细解读。
正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;于此Tood设计了一个新的Anchor alignment metric ,Anchor alignment metric是cls得分以及预测框与GT的IOU相乘得来,将其作为任意anchor的质量评估,在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里来动态的优化每个 Anchor 的预测。
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
self.bs = pd_scores.size(0)
self.n_max_boxes = gt_bboxes.size(1)
if self.n_max_boxes == 0:
device = gt_bboxes.device
return (torch.full_like(pd_scores[..., 0], self.bg_idx).to(device), torch.zeros_like(pd_bboxes).to(device),
torch.zeros_like(pd_scores).to(device), torch.zeros_like(pd_scores[..., 0]).to(device),
torch.zeros_like(pd_scores[..., 0]).to(device))
mask_pos, align_metric, overlaps = self.get_pos_mask(pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points,
mask_gt)
target_gt_idx, fg_mask, mask_pos = select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
# assigned target
target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
# normalize
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(axis=-1, keepdim=True) # b, max_num_obj
pos_overlaps = (overlaps * mask_pos).amax(axis=-1, keepdim=True) # b, max_num_obj
# norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
norm_align_metric = (align_metric / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
target_scores = target_scores * norm_align_metric
return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
在v8中,label assignment分为3个步骤。首先,根据self.get_pos_mask()计算出正样本的mask,GT与pred_bboxes的iou以及align_metric,其中
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
mask_pos(即正样本的mask)需要通过mask_topk * mask_in_gts * mask_gt相乘获得。mask_in_gts表示在GT内部的mask,GT左上角与右下角的坐标分别与anchor的中心点做差获得bbox_deltas, 当bbox_deltas的值均大于0则说明该点在GT内,即可获得mask_in_gts。
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
mask_topk 这个很好理解,就是align_metric的topk。align_metric同时考虑了cls与reg,因此可以更好的对齐cls与reg两个任务。cls与reg是模型预测值,两者结合可以很好的估计出该GT在哪些grid表现优秀,用align_metric的topk来选正样本点更为合理。
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
# get anchor_align metric, (b, max_num_obj, h*w)
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes)
# get in_gts mask, (b, max_num_obj, h*w)
mask_in_gts = select_candidates_in_gts(anc_points, gt_bboxes)
# get topk_metric mask, (b, max_num_obj, h*w)
mask_topk = self.select_topk_candidates(align_metric * mask_in_gts,
topk_mask=mask_gt.repeat([1, 1, self.topk]).bool())
# merge all mask to a final mask, (b, max_num_obj, h*w)
mask_pos = mask_topk * mask_in_gts * mask_gt
return mask_pos, align_metric, overlaps
此时,我们已经获得正样本的mask,但是GT存在交叠的情况,因此一个点可能对应多个GT,我们需要杜绝这种情况,将面积最大的GT赋值给有歧义的点。select_highest_overlaps函数可以完成这样的任务。
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
# (b, n_max_boxes, h*w) -> (b, h*w)
fg_mask = mask_pos.sum(-2)
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).repeat([1, n_max_boxes, 1]) # (b, n_max_boxes, h*w)
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
is_max_overlaps = F.one_hot(max_overlaps_idx, n_max_boxes) # (b, h*w, n_max_boxes)
is_max_overlaps = is_max_overlaps.permute(0, 2, 1).to(overlaps.dtype) # (b, n_max_boxes, h*w)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos) # (b, n_max_boxes, h*w)
fg_mask = mask_pos.sum(-2)
# find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos
将mask_pos在n_max_boxes维度上叠加,当fg_mask.max() > 1时,说明存在歧义点。找到歧义点的索引mask_multi_gts 以及每个预测框对应的面积最大GT的索引max_overlaps_idx ,将max_overlaps_idx变成onehot形式,将有歧义点的值换成is_max_overlaps就可以祛除歧义。通过mask_pos.argmax(-2)能够获得target_gt_idx ,即可以找到每个点对应的哪个GT。
最后,我们根据target_gt_idx 可以获得计算loss的targets,get_targets逻辑较为清晰不赘述。至此,v8的label assignment讲解完毕。
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
Args:
gt_labels: (b, max_num_obj, 1)
gt_bboxes: (b, max_num_obj, 4)
target_gt_idx: (b, h*w)
fg_mask: (b, h*w)
"""
# assigned target labels, (b, 1)
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
# assigned target boxes, (b, max_num_obj, 4) -> (b, h*w)
target_bboxes = gt_bboxes.view(-1, 4)[target_gt_idx]
# assigned target scores
target_labels.clamp(0)
target_scores = F.one_hot(target_labels, self.num_classes) # (b, h*w, 80)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores
Loss
对于YOLOv8,其分类损失为VFL Loss,其回归损失为CIOU Loss+DFL的形式,这里Reg_max默认为16。
VFL主要改进是提出了非对称的加权操作,FL和QFL都是对称的。而非对称加权的思想来源于论文PISA,该论文指出首先正负样本有不平衡问题,即使在正样本中也存在不等权问题,因为mAP的计算是主正样本。VFL则为了突出正样本,因此正样本采用bce而负样本采用FL来衰减loss。
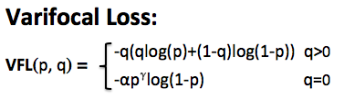
如上图公式所示,p是label,正样本时候q为norm_align_metric计算出的值,负样本时候p=0,当为正样本时候其实没有采用FL,而是普通的BCE,只不过多了一个自适应norm_align_metric加权,用于突出主样本。而为负样本时候就是标准的FL了。可以明显发现VFL比QFL更加简单,主要特点是正负样本非对称加权、突出正样本为主样本。
DFL(Distribution Focal Loss将坐标回归的单个值更改成输出n+1个值,每个值表示对应回归距离的概率,然后利用积分获得最终的回归距离。针对这里的DFL,其主要是将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布。
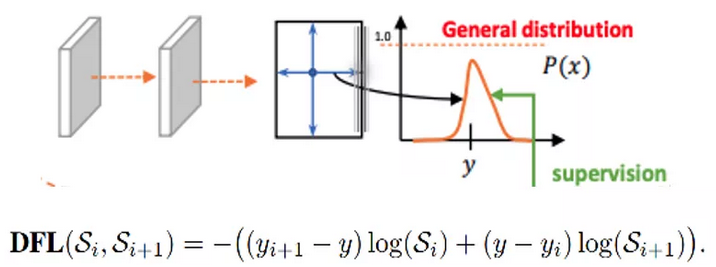
DFL 能够让网络更快地聚焦于目标 y 附近的值,增大它们的概率;
DFL的含义是以交叉熵的形式去优化与标签y最接近的一左一右2个位置的概率,从而让网络更快的聚焦到目标位置的邻近区域的分布;也就是说学出来的分布理论上是在真实浮点坐标的附近,并且以线性插值的模式得到距离左右整数坐标的权重。
思考
相对于v5,v8主要的更新是label assignment以及相应loss的迭代,即正负样本采用动态策略(选取metric topk)提高输出cls与reg的一致性,loss则采用metric作为soft label。为了探究soft label对于od性能的增益,我做了相关消融实验。
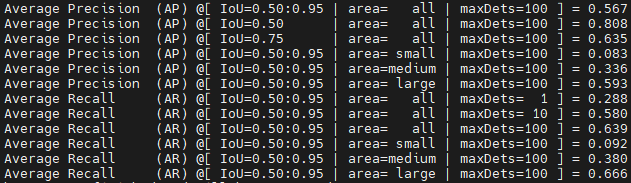
上图称为label 1,将v8选取的正样本点的label设置为hard label,即全部设置为1。
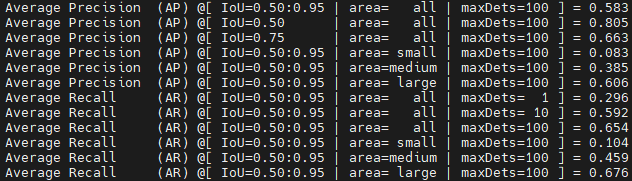
上图称为label 2,采用metric作为soft label,并使用vfl作为分类loss。
从label1,2中可以发现,soft label与hard label在AP50的表现差异不大,但是,soft label的mAP比hard label高了1.6%。同时soft label的AP75,AR均高于hard label,这表明soft label在hard samples的cls与reg的一致性较高,即cls得分高的anchor,其坐标回归也准,在post process后保留的结果与GT的IOU较大。但是,soft label为什么会有这样的作用呢?我们可以看一下他们的得分与回归的热力图。
hard label iou heatmap |
soft label iou heatmap |
|---|---|
hard label cls heatmap |
soft label cls heatmap |
hard label iou heatmap |
soft label iou heatmap |
|---|---|
hard label cls heatmap |
soft label cls heat map |
我将最后输出的每个anchor的cls与reg与GT的iou可视化,可以发现,soft label相比于hard label置信度略低,总体呈现高斯分布,且热力图会覆盖困难样本,而hard label虽然置信度较高,但是其热力图不规则,置信度max index可能会漂离中心。同时,soft label iou的热力图总体比hard label热力图覆盖范围大,且与GT的iou较高。因此,soft label Map会高于hard label,同时,对于困难样本也是有益的。