很久没有更新文章了,在YOLO v3之后,目标检测方向又相继出现很多好文章,为了方便回顾以及大家相互学习,今天总结一下YOLO v4。在此之前,我总结过yolo系列的文章与代码解析,有兴趣的同学可以查看YOLO v3。
Yolov4论文名:《Yolov4: Optimal Speed and Accuracy of Object Detection》
Yolov4论文地址:https://arxiv.org/pdf/2004.10934.pdf
1.网络结构
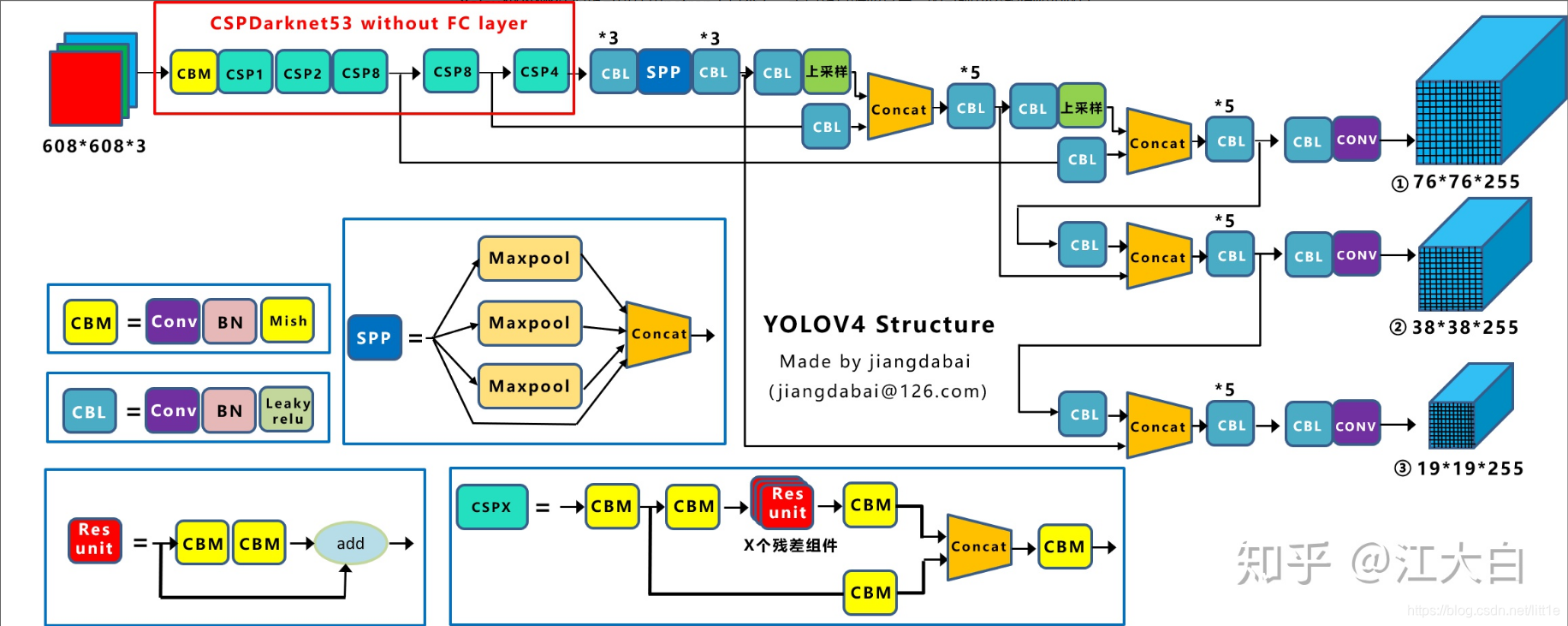
从这儿偷张图,这个图可以很直观地展示yolov4的网络结构。与yolov3相比,backbone采用了CSPNet的基础卷积模块以及Mish激活,Neck则在FPN的基础上增加了PAN结构,既在自上而下的特征生成方式下融合了自下而上的特征。
CBM:Conv+BN+Mish的卷积组合。
CBL:Conv+BN+Leaky_relu的卷积组合。
SPP:与yolov3相同,采用了5×5,9×9,13×13的Max_pooling的concat。
CSPX:采用CSPNet的卷积模块(本质是将不同分组生成的卷积concat与densenet相似),并结合Bottleneck形式融入残差。
在Backbone上,作者使用Dropblock来缓和过拟合,提高模型的泛化能力,使用CSPdarkent53作为Backbone,并结合FPN,PAN作为Neck,提高特征提取的效率与性能。anchor机制与yolov3相同,训练时采用CIOU_Loss来提高bbox的坐标定位性能。
Dropblock
Dropblock和dropout原理相似,dropout一般对全连接的作用比较大,对卷积层效果甚微,原因可能是在随机删除部分特征后,对激活函数影响不大。
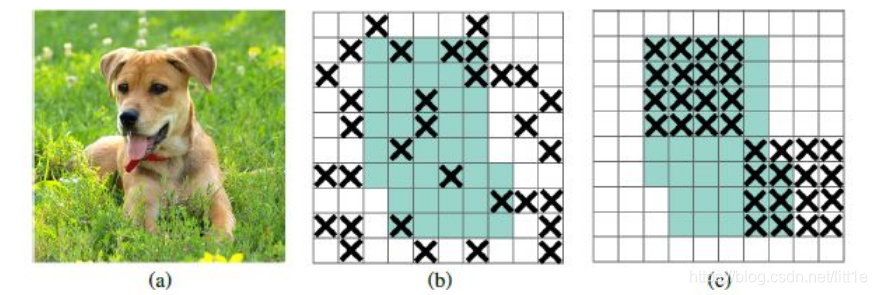
如上图所示,绿色区域主要蕴含了图像的语义信息,也就是狗所在的主要区域,通过图b的方式随机dropout效果并不好,因为相邻单元也包含了相关信息。按照图C的方式,移除整块区域,例如整个头或者脚,这样可以强制剩余单元学习到用于分类的特征。
DropBlock有两个参数,block_size,是我们要drop 的模块的大小,当block_size=1时,就是常用的dropout。另一个参数,γ 控制要丢弃的特征的数量。,假设keep_prob为我们想要保存特征的概率,则γ等于
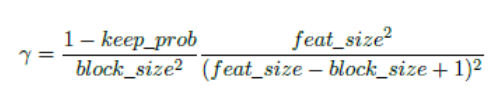
使用dropblock可以有效提高检测性能,是一个很有效的涨点trick。
CSPdarkent53
在yolov4中CSPX的stride均为2,即CSP模块起到下采样的作用,将608×608的输入下采样至304->152->76->38->19。网络最终的输出层size为76,38,19.

上图展示了CSP的卷积模块,将特征一分为二,每次对新concat的特征进行卷积,并将产生的新特征concat,由transition layer输出最终特征。这样做的好处是,减少bp时梯度信息的重复,降低计算量,提高CNN的学习能力。
FPN+PAN
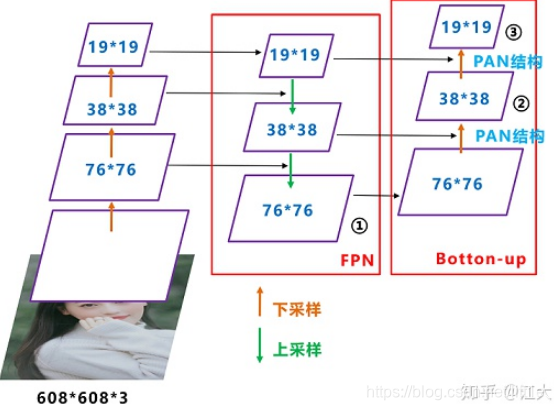
YOLOv4采用FPN+PAN的结果作为Neck,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。YOLOv4将FPN生成的76×76的特征作为输出,同时,将PAN生成的38×38,19×19的特征作为输出,结合anchor,完成不同尺度目标的检测。
本人这里有疑惑,这样的结构增加了很多卷积层,到底是参数量的变化带来的涨点还是结构本身的优势呢,而且这样融合应该会对原有信息造成一定的污染,如何定位并更好的传递信息让Neck大放异彩也许值得我们思考。
CIOU_loss
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)。这个文章总结IOU很棒所以直接引用这块内容。
a.IOU_Loss
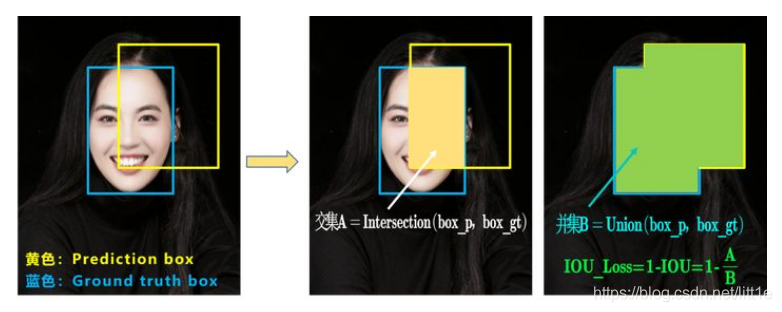
可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。
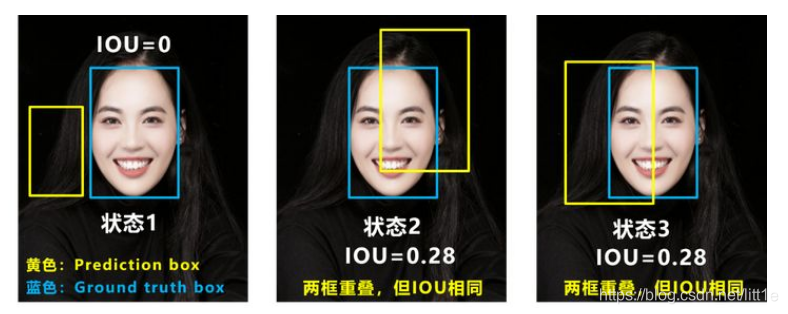
问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
因此2019年出现了GIOU_Loss来进行改进。
b.GIOU_Loss
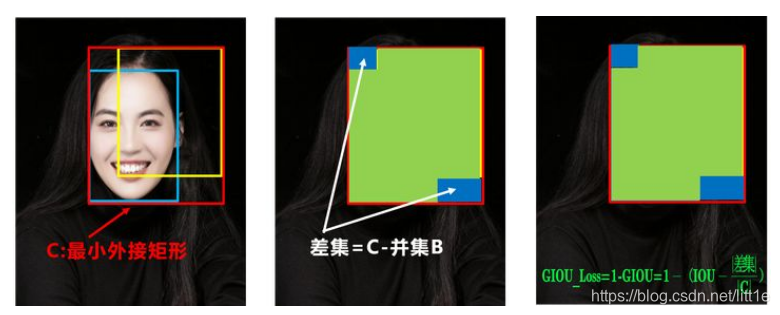
可以看到右图GIOU_Loss中,增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时的尴尬。
但为什么仅仅说缓解呢?
因为还存在一种不足:

问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
基于这个问题,2020年的AAAI又提出了DIOU_Loss。
c.DIOU_Loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,作者从两个方面进行考虑
一:如何最小化预测框和目标框之间的归一化距离?
二:如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,提出了DIOU_Loss(Distance_IOU_Loss)

比如上面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。
但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
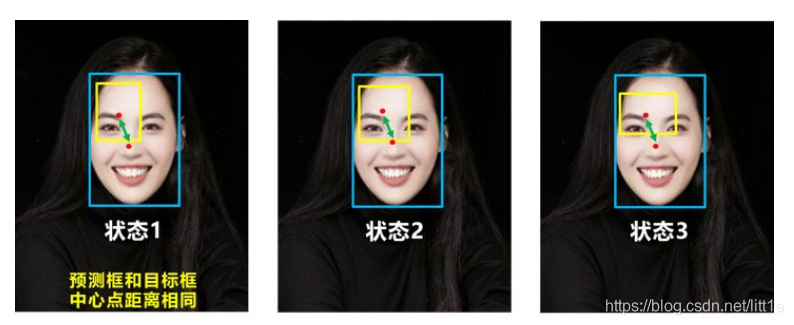
针对这个问题,又提出了CIOU_Loss,不对不说,科学总是在解决问题中,不断进步!!
d.CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。

其中v是衡量长宽比一致性的参数,我们也可以定义为:
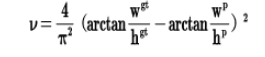
这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
再来综合的看下各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
2.数据增广

Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。我们知道目标检测难点一直是对小目标的检测定位,主要原因是,第一,coco数据集中大中小目标占比不均衡,小目标的数量很多,但出现的频率却很低,这导致bp时对小目标的优化不足。第二,小目标本身检测难度就高于大目标,容易出现误检与漏检。
作者提出Mosaic,随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。与此同时,Mosaic可以减少GPU的投入,使得小的bachsize也能训练出好的模型。