RCNN系列
1)RCNN
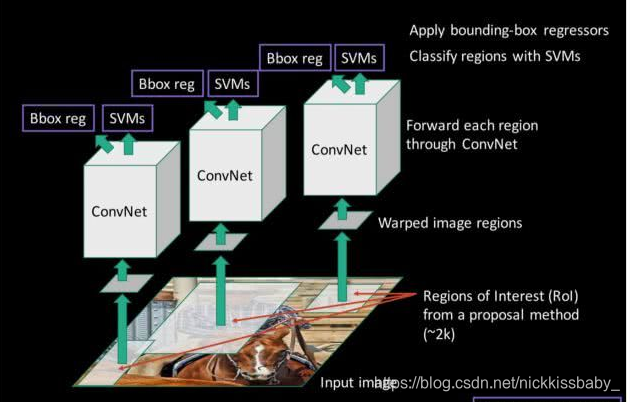
- 候选框提取:使用selective search来提取类别独立的object proposals
- 特征提取:使用一个预训练的模型进行finetune。由于在ImageNet上预训练模型输出是1000类,而VOC只需要21类(加上后景),因此需要替换掉最后一层。将SS提取的候选框统一到同一size放入网络进行finetune,候选框跟ground truth box的IoU大于0.5即可被认为是正类,否则为后景。
- 训练SVM(每个类别一个SVM):由于训练SVM的样本量比训练CNN的样本量少,且为了提升SVM的性能,将负样本定义为与Ground truth box的IoU小于0.3的样本,正样本定义为与Ground truth box的IoU大于0.7的样本
- 边框回归:使用NMS(极大值抑制)来筛选候选框,然后丢进线性回归模型进行回归。回归输入是CNN的输出特征,输出则是位移以及尺度放缩。
- 首先先做平移
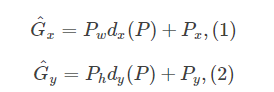
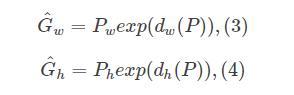
其中P就是CNN的特征,输入为原候选框的中心x,y以及高和宽h,w即 。因此回归的ground truth为
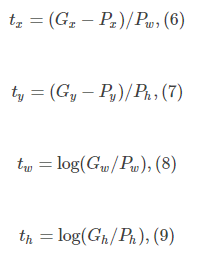
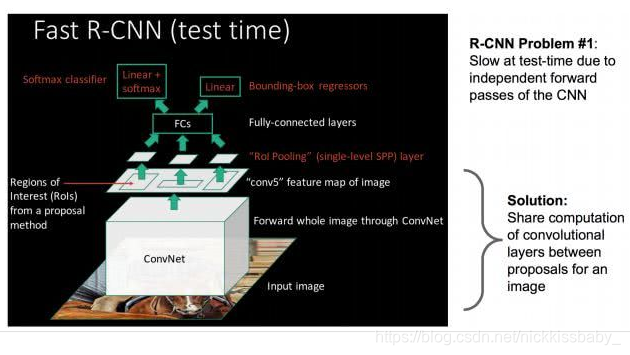
2)fast rcnn
- 与RCNN的两个主要不同之处在于
- 不需要rcnn那样每个框都需要独立地提取特征。使用ROI Pooling,直接提取将每个候选框对应的feature map上的区域进行pooling得到固定大小的特征再进行分类以及bounding box回归。
- 多任务loss function:
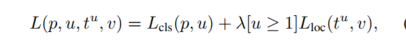
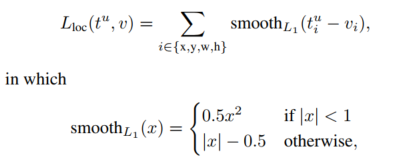
smooth L1 损失函数相比L2 loss,对于outliers更加鲁棒。其中 代表scale-invariant translation and log-space height/width shift,说白就是跟rcnn计算位移以及尺度变换的方法一致。其中,论文提到,在实验中采用 。
3)faster rcnn
faster rcnn速度达到5-17fps,主要创新点在于RPN
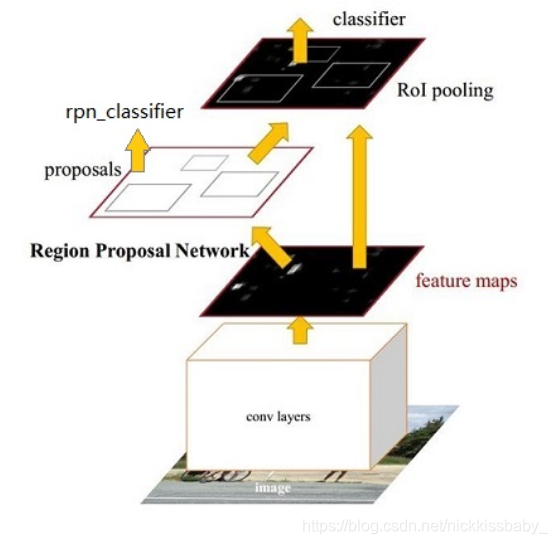
- 使用预训练的CNN进行提取特征,CNN的特征被后面的FPN以及fast rcnn共享。
- 使用RPN生成proposals,在RPN的特征图上,每一个像素映射到9个anchor boxs,包括3中尺寸以及3种长宽比,在原文中映射到原图的三种尺寸分别为128,256,512),三种尺寸包括1,0.5,2。
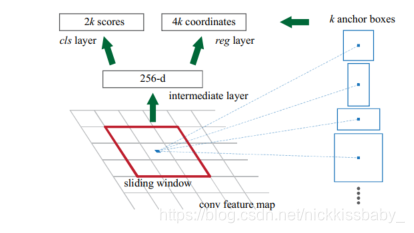
每个anchor box对应2个分类输出(是否是box,ground truth的设定与前边一致,都是大于0.7IoU为正,小于0.3IoU为负)以及四个回归输出。 - 对rpn生成的anchor box使用NMS进行筛选,筛选过后大概剩下2000个box,将筛选过后的box经过roi pooling层以后提取映射特征进行多分类以及box回归,操作与fast rcnn基本一致。
- loss function:
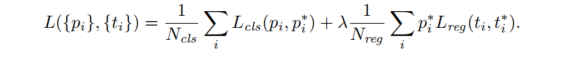
在训练rpn的时候,随机抽取256个正负样本比例为1:1的anchor box进行训练 - 训练过程:
- 首先使用Image-Net上的预训练模型,然后对候选框生成任务进行fine-tune
- 然后使用上一步产生的proposals对fast rcnn部分进行训练。(前两步属于预训练)
- 此前RPN与fast rcnn并未共享参数。现在用上一步fast rcnn产生的参数来初始化共享卷积层,然后fine-tune只属于RPN的部分
- 固定共享卷积层,fine-tune只属于fast r-cnn的部分
4)Mask R-CNN(200ms per frame)
- Mask R-CNN相比Faster RCNN,我觉得最大三个不同之处在于:
- 使用了FPN来提取不同尺寸的特征,从而预测不同大小的anchor box。在语义分割的任务中,U-Net是一个非常厉害的模型,而FPN看起来简直是U-Net的一个翻版…U-Net有一个上采样的过程,逐步将低层的特征融入当前层,融合高层的语义特征以及低层的空间特征。在我看来,高层的语义特征确定下来了分割目标的粗略模型或者说定位问题,当找到大概位置以后再逐步利用上采样的高层特征加上低层的空间特征(高分辨率),从而实现对目标的分割,低层的高分辨率特征对于细分割非常重要,当确定下来位置以后,一些底层的特征如梯度、轮廓就会变得非常重要。FPN在这里同样利用了类似的思想,使用高层的语义信息结合低层的高分辨率特征进行融合,帮助低层特征找到目标定位。假如要检测大的物体,直接使用高层的低分辨率特征(具有高度语义)即可,因为大的物体相比小物体需要更大的感受野,且大的物体在低分辨率特征图下依然有一席之地(而小物体就会被稀释到快看不到了…)
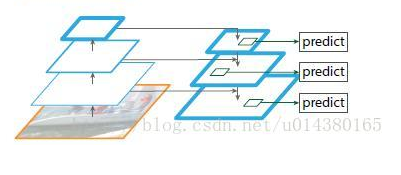
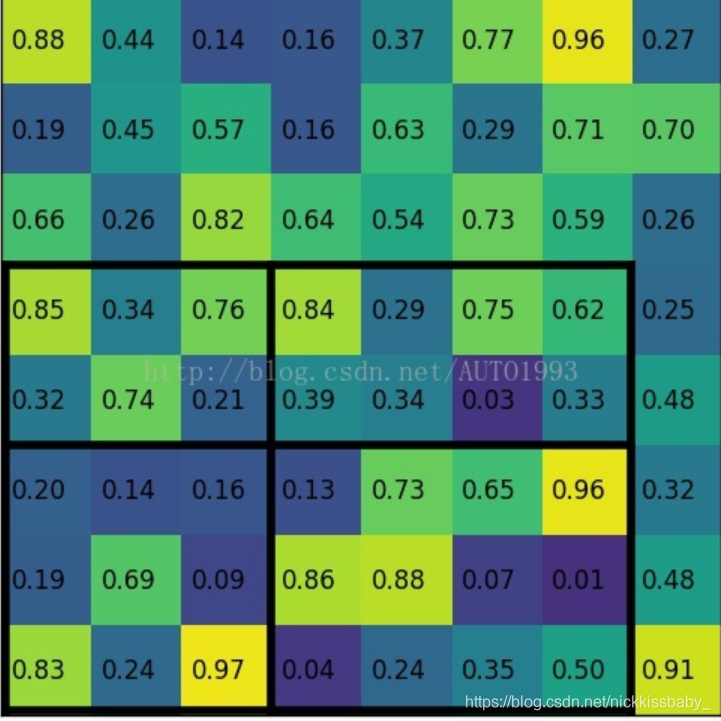
- 第二不同的地方在于ROI Align。faster rcnn使用了ROI Pooling将不同大小不同尺寸的anchor box的特征统一到一个大小,从而才能输入到全连接层进行分类以及回归。而上边的图可以看出,ROI Pooling进行量化的时候进行了四舍五入,这种处理对于detection这种任务而言并没有太大的影响,然而对于语义分割这种逐像素进行分类的任务而言,就会带来没有align的后果导致最后输出的mask不够精准,这对于分割而言是比较致命的。为了解决这个问题,将不同大小的特征图映射到FPN特征上的时候不进行任何量化操作,采用了双线性插值去采样然后再进行pooling。
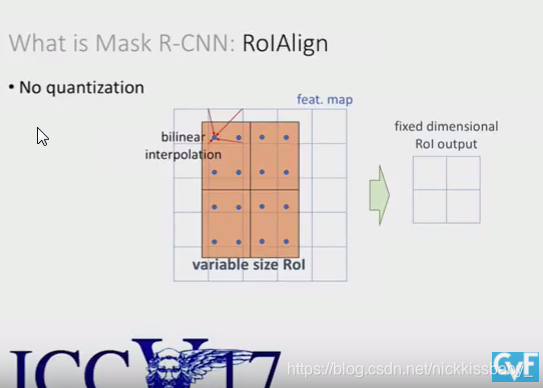
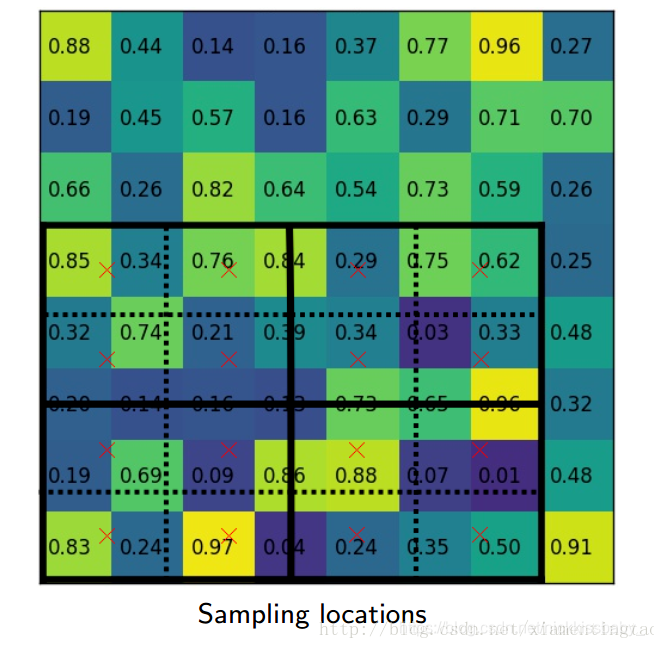
- 与faster rcnn一样,在进行最后的分类回归以及分割之前,要采用NMS进行筛选proposals。多出来了一个做实例分割的分支,有两种。第二种的backbone包括了resnet的5th stage即res5,最后进入分割的特征包含的通道数更少,效率更高。

- Loss Function: 。损失函数定义被分类的loss加上box回归的loss再加上mask的loss。使用sigmoid作为mask的归一化函数,对于分割任务采用BCE作为 。由于是多类别分割任务,每一个proposal都会产生K个mask(对应K个类),但是进行计算loss的时候,只计算ground truth所在的那一类所在mask的损失。
接下来我还会对YOLO系列进行一次总结。