0. 前言
说到深度学习的目标检测,就要提到传统的目标检测方法。
传统的目标检测流程:
1)区域选择(穷举策略:采用滑动窗口,且设置不同的大小,不同的长宽比对图像进行遍历,时间复杂度高)
2)特征提取(SIFT、HOG等;形态多样性、光照变化多样性、背景多样性使得特征鲁棒性差)
3)分类器(主要有SVM、Adaboost等)
基于深度学习的目标检测问题从2014年至今已经经历过RCNN,Fast-RCNN,Faster-RCNN,Mask-RCNN 等版本的演变,性能和准确率也在不断的提升,本篇博客旨在将这些网络的结构和改进之处做一个总结回顾。认识粗浅,欢迎指正。
1. RCNN(2014)
流程:
输入图像Selective Search(挑选2000和候选框)
AlexNet网络提取特征
SVM分类
Selective search方法来生成候选区域,这是一种启发式搜索算法。它先通过简单的区域划分算法将图片划分成很多小区域,然后通过层级分组方法按照一定相似度合并它们,最后的剩下的就是候选区域(region proposals),它们可能包含一个物体。示意图如下:
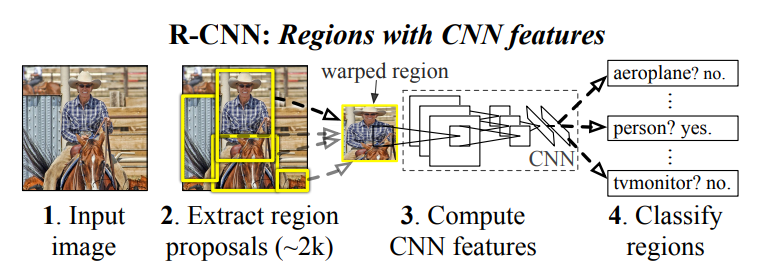
对于一张图片,R-CNN基于selective search方法大约生成2000个候选区域,然后每个候选区域被resize成固定大小(227×227)并送入一个CNN模型中,使用AlexNet来提取图像特征,最后得到一个4096维的特征向量。然后这个特征向量被送入一个多类别SVM分类器中,预测出候选区域中所含物体的属于每个类的概率值。每个类别训练一个SVM分类器,从特征向量中推断其属于该类别的概率大小。为了提升定位准确性,R-CNN最后又训练了一个边界框回归模型。训练样本为(P,G),其中P=(Px,Py,Pw,Ph)为候选区域,而G=(Gx,Gy,Gw,Gh)为真实框的位置和大小。G的选择是与P的IoU最大的真实框,回归器的目标值定义为:
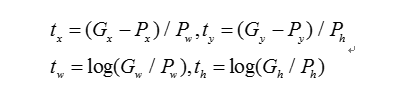
在做预测时,利用上述公式可以反求出预测框的修正位置。R-CNN对每个类别都训练了单独的回归器,采用最小均方差损失函数进行训练。
R-CNN是非常直观的,就是把检测问题转化为了分类问题,但是,由于R-CNN使用计算复杂度极高的selective search提取候区域,并使用SVM来进行分类,并不是一个端到端的训练模型。R-CNN模型在统一候选区的大小后才能进行特征提取和特征分类。并且提取的候选框会在特征提取的时候会进行重复计算。
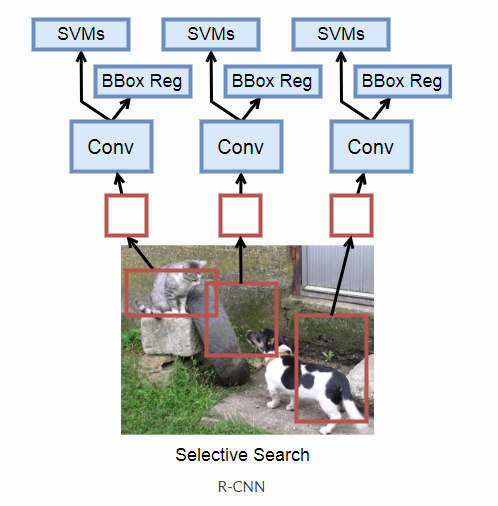
Selective Search介绍
step0:生成区域集R,具体参见论文《Efficient Graph-Based Image Segmentation》
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
论文中伪代码:

相似度计算
在做物体识别(Object Recognition)过程中,不能通过单一的策略来区分不同的物体,需要充分考虑图像物体的多样性(diversity)。另外,在图像中物体的布局有一定的层次(hierarchical)关系,考虑这种关系才能够更好地对物体的类别(category)进行区分。如下图,(a)中的场景是一张桌子,桌子上面放了碗,瓶子,还有其他餐具等等。比如要识别“桌子”,我们可能只是指桌子本身,也可能包含其上面的其他物体。这里显示出了图像中不同物体之间是有一定的层次关系的。(b)中给出了两只猫,可以通过纹理(texture)来找到这两只猫,却又需要通过颜色(color)来区分它们。(c)中变色龙和周边颜色接近,可以通过纹理(texture)来区分。(d)中的车辆,我们很容易把车身和车轮看做一个整体,但它们两者之间在纹理(texture)和颜色(color)方面差别都非常地大。

所以相似度计算时候论文考虑了颜色,纹理,尺寸和空间交叠这4个参数。
1)颜色相似度(color similarity)
将色彩空间转为HSV,每个通道下以bins=25计算直方图,这样每个区域的颜色直方图有25*3=75个区间。 对直方图除以区域尺寸做归一化后使用下式计算相似度:
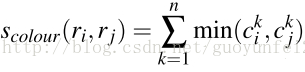
2)纹理相似度(texture similarity)
论文采用方差为1的高斯分布在8个方向做梯度统计,然后将统计结果(尺寸与区域大小一致)以bins=10计算直方图。直方图区间数为8*3*10=240(使用RGB色彩空间)。

其中, 是直方图中第
是直方图中第 个bin的值。
个bin的值。
3)尺寸相似度(size similarity)

保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域。
例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh。
4)交叠相似度(shape compatibility measure)


5) 最终的相似度

关于Selective Search的代码:https://github.com/AlpacaDB/selectivesearch
RCNN的缺陷:
1)耗时的Selective search,每一帧图像,需要花费2s。
2)耗时的串行式CNN网络,每一个ROI都要经过一个CNN提取特征,所有的ROI提取特征大约47s。
3)三个模块分开训练,存储空间消耗大
2. Fast RCNN(2015)
Fast-RCNN先用Selective Search找出候选框,’而后整张图过一次CNN,然后用RoI Pooling,将对应候选框的部分做采样,得到相同长度的特征,又经过两层全连接层之后得到最终的特征。接着产生两个分支,一个分支给此特征分类,另一个分支回归此特征的候选框偏移。Fast-RCNN将分类和回归任务融合在一个模型中。
针对RCNN的改进:
1)取代RCNN串行特征提取方式,直接用一个神经网络对全图提取特征。
2)除了Selective search,其他部分可以一起训练
核心算法:RoI Pooling
3. Faster RCNN(2016)
改进:
提出Region Proposal Network(RPN)生成待检测网络,取代了原来的Selective Search,真正实现了端到端的训练(end-to-end training)。
核心算法:RPN
4. Mask RCNN(2017)
此部分较多参考网址:https://blog.csdn.net/WZZ18191171661/article/details/79453780
Mask RCNN是一个实例分割(Instance segmentation)算法。
实例分割(Instance segmentation)和语义分割(Semantic segmentation)的区别和联系
联系:两者都是目标分割中的两个小领域,用来对输入的图片进行分割处理。
区别:实例分割对对象更加细化,如对于图像中不同的人,语义分割给了它们相同的颜色,而在实例分割中却给了不同的颜色。即实例分割需要在语义分割的基础上对同类物体进行更精细的分割。

Mask RCNN预期达到的效果:高速和高准确率,简单直观且以便于使用。
高速和高准确率:
为了实现这个目的,作者选用了经典的目标检测算法Faster-rcnn和经典的语义分割算法FCN。Faster-rcnn可以既快又准的完成目标检测的功能;FCN可以精准的完成语义分割的功能,这两个算法都是对应领域中的经典之作。Mask R-CNN比Faster-rcnn复杂,但是最终仍然可以达到5fps的速度,这和原始的Faster-rcnn的速度相当。由于发现了ROI Pooling中所存在的像素偏差问题,提出了对应的ROIAlign策略,加上FCN精准的像素MASK,使得其可以获得高准确率。
简单直观且以便于使用:
整个Mask R-CNN算法的思路很简单,就是在原始Faster-rcnn算法的基础上面增加了FCN来产生对应的MASK分支。即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN。
整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务,具有很好的扩展性和易用性。
1)Mask R-CNN算法步骤
- 首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
- 然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 接着,对这个feature map中的每一点设定预定个的ROI,从而获得多个候选ROI;
- 接着,将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
- 接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后将feature map和固定的feature对应起来);
- 最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
2)Mask R-CNN的核心架构分解(ROIAlign和FCN)
ROIPooling和ROIAlign的分析与比较
ROI Pooling和ROIAlign最大的区别是:前者使用了两次量化操作,而后者并没有采用量化操作,使用了线性插值算法,具体的解释如下所示
ROI Pooling技术:
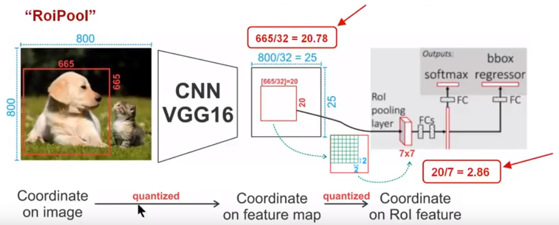
为了得到固定大小(7X7)的feature map,我们需要做两次量化操作:1)图像坐标 — feature map坐标,2)feature map坐标 — ROI feature坐标。我们来说一下具体的细节,如图我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,经过VGG16网络后,我们可以获得对应的feature map,如果我们对卷积层进行Padding操作,我们的图片经过卷积层后保持原来的大小,但是由于池化层的存在,我们最终获得feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关。在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,但是我们的像素值可没有小数,那么作者就对其进行了量化操作(即取整操作),即其结果变为20 x 20,在这里引入了第一次的量化误差;然而我们的feature map中有不同大小的ROI,但是我们后面的网络却要求我们有固定的输入,因此,我们需要将不同大小的ROI转化为固定的ROI feature,在这里使用的是7x7的ROI feature,那么我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,我们采取同样的操作对其进行取整吧,在这里引入了第二次量化误差。其实,这里引入的误差会导致图像中的像素和特征中的像素的偏差,即将feature空间的ROI对应到原图上面会出现很大的偏差。原因如下:比如用我们第二次引入的误差来分析,本来是2,86,我们将其量化为2,这期间引入了0.86的误差,看起来是一个很小的误差呀,但是你要记得这是在feature空间,我们的feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52。这个差距不小吧,这还是仅仅考虑了第二次的量化误差。这会大大影响整个检测算法的性能,因此是一个严重的问题。
ROIAlign技术:
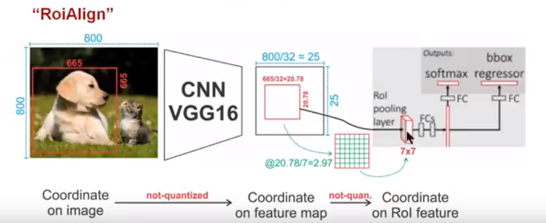
为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,即我们不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。这就是ROIAlign的初衷。那么我们如何处理这些浮点数呢,我们的解决思路是使用“双线性插值”算法。双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。厉害哈。如图11所示,蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些蓝点是2x2Cell中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。
we propose an RoIAlign layer that removes the harsh quantization of RoIPool, properly aligning the extracted features with the input. Our proposed change is simple: we avoid any quantization of the RoI boundaries or bins (i.e., we use x=16 instead of [x=16]). We use bilinear interpolation [22] to compute the exact values of the input features at four regularly sampled locations in each RoI bin, and aggregate the result (using max or average), see Figure 3 for details. We note that the results are not sensitive to the exact sampling locations, or how many points are sampled, as long as no quantization is performed。
双线性插值:

3)LOSS计算与分析
由于增加了mask分支,每个ROI的Loss函数如下所示:
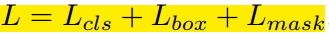
其中Lcls和Lbox和Faster r-cnn中定义的相同。对于每一个ROI,mask分支有Km*m维度的输出,其对K个大小为m*m的mask进行编码,每一个mask有K个类别。我们使用了per-pixel sigmoid,并且将Lmask定义为the average binary cross-entropy loss 。对应一个属于GT中的第k类的ROI,Lmask仅仅在第k个mask上面有定义(其它的k-1个mask输出对整个Loss没有贡献)。我们定义的Lmask允许网络为每一类生成一个mask,而不用和其它类进行竞争;我们依赖于分类分支所预测的类别标签来选择输出的mask。这样将分类和mask生成分解开来。这与利用FCN进行语义分割的有所不同,它通常使用一个per-pixel sigmoid和一个multinomial cross-entropy loss ,在这种情况下mask之间存在竞争关系;而由于我们使用了一个per-pixel sigmoid 和一个binary loss ,不同的mask之间不存在竞争关系。经验表明,这可以提高实例分割的效果。
一个mask对一个目标的输入空间布局进行编码,与类别标签和BB偏置不同,它们通常需要通过FC层而导致其以短向量的形式输出。我们可以通过由卷积提供的像素和像素的对应关系来获得mask的空间结构信息。具体的来说,我们使用FCN从每一个ROI中预测出一个m*m大小的mask,这使得mask分支中的每个层能够明确的保持m×m空间布局,而不将其折叠成缺少空间维度的向量表示。和以前用fc层做mask预测的方法不同的是,我们的实验表明我们的mask表示需要更少的参数,而且更加准确。这些像素到像素的行为需要我们的ROI特征,而我们的ROI特征通常是比较小的feature map,其已经进行了对其操作,为了一致的较好的保持明确的单像素空间对应关系,我们提出了ROIAlign操作。
FCN回顾
3)Mask R-CNN的主要贡献
- 分析了ROI Pool的不足,提升了ROIAlign,提升了检测和实例分割的效果;
- 将实例分割分解为分类和mask生成两个分支,依赖于分类分支所预测的类别标签来选择输出对应的mask。同时利用Binary Loss代替Multinomial Loss,消除了不同类别的mask之间的竞争,生成了准确的二值mask;
- 并行进行分类和mask生成任务,对模型进行了加速。
5. YOLO(2016)
以下写贴一些别人对YOLO的评价吧
- YOLO是我见过的最elegant的方法(直接回归bounding boxes coordinates和all C class probabilities)。具体如下:先将图片resize成448*448(L*L)大小,将图片划分成S*S个grid(S=7,所以每个64*64大小的sub-image属于一个grid)。然后每个grid负责propose B个bounding box(B=2),每个bounding box对应4个coordinates、1个confidence(表示P(object)*对应的bounding box和any ground truth box的intersection of union(IOU)大小,即P(Object)*IOU^{truth}_{pred}),另外,每个grid还要生成C个conditional class probabilities(表示该grid内部的sub-image包含object时,这个object属于各个类别上的概率,即P(C_{i}|Object);因为总共有20个类别,所以C=20)。这样,一个image最终产生S*S*(B*5+C)个输出(7*7*(2*5+20)=1470个输出)。然后就是找ground truth进行训练,要考虑不同任务的权重。预测时,使用P(C_{i}|Object)*P(Object)*IOU^{truth}_{pred}找到最大的C_{i}即可。可以看到,YOLO模型非常简单,所以最大的好处是,时间快,做到了实时;另外,由于看到的context信息比较多,多以background很少分错。缺点是特征粒度太粗,small object容易分错,accuracy相对较低(主要错误在于localization,这个也是显而易见的)。===》本人查看并修改了YOLO的源码,确实很经典,而且实现起来很简单,效果也不错。===》据说YOLO-V2版本中,将每个grid生成C个conditional class probabilities(然后让该grid对应的所有bounding boxes共享这C个conditional class probabilities)改成了为每个bounding boxes生成各自独立的C个conditional class probabilities,此时效果有明显提升!!
- YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑窗或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。当然,YOLO在提升检测速度的同时牺牲了一些精度。下图所示是YOLO检测系统流程:1.将图像Resize到448*448;2.运行CNN;3.非极大抑制优化检测结果。
6.SSD(2015)
- SSD。有人说SSD相当于YOLO(直接回归bounding boxes coordinates和all C class probabilities) + RPN的anchor(每个feature map用一个小窗口扫描,对每个扫描位置生成k个default的bounding boxes) + multi-scale的prediction。个人感觉SSD最大的特点是multi-scale的prediction,从一个image中生成多个不同scale、spatial_ratio的feature maps(具体实现时,就是把网络的最后几层设计成不同的scale,全部作为feature maps),然后在每个feature map上生成需要的数据(bounding boxes、class probabilities等),然后联合训练。具体的,仍然用3*3的窗口对每个feature map进行扫描,在每个扫描位置生成k个不同大小的default bounding boxes,每个boxes对应4个coordinates和C个class probabilities(和YOLO一样,直接是C个类别对应的概率;不同于Faster-R-CNN的2个输出,只能代表是不是object的概率,还需后续classification)。然后就是找ground truth进行训练,要考虑不同任务的权重。可以看到对于M*N的feature map,输出节点数为M*N*K*(C+4),另外因为有F个feature map,所以还要再乘以F。
参考网址
1. 基于CNN目标检测方法(RCNN,Fast-RCNN,Faster-RCNN,Mask-RCNN,YOLO,SSD)行人检测,目标追踪,卷积神经网络
3. R-CNN,Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列,深度学习object detection梳理
推荐阅读
4. R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD, R-FCN系列深度学习检测方法梳理