机器学习中有监督的学习,通过标注data训练model时,通常采用交叉验证的方法选择模型参数。
将有标注的data分为训练集,(交叉)验证集,测试集三份:
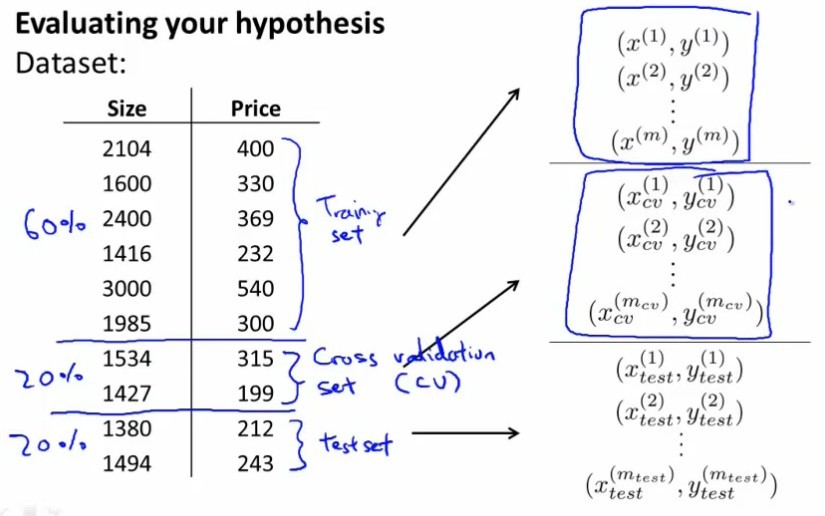
机器学习的model中,有些模型参数是需要事先指定的,在training之前就是一个常量(与在training过程中通过minimize目标函数求得的参数不同),根据经验指定参数不一定靠谱,所以需要在training之前,做一个交叉验证来选择这个常量的值。
在做模型选择时,更确切的说做模型参数选择时,而(这里以多项式kernel的SVM为例,我们需要选择的参数是多项式的阶数k):
1 训练:先用Training Set在一次模型、二次模型、三次模型(几次指的是的z=Zθ(x) 阶数)情况下跑一下,然后用数值优化的算法求得在指定阶数情况下,使Training error最小的参数θ分别是多少
2 参数寻优:用Cross Validation Set在1中得到的每个模型M(1,θ1)...M(k,θk)...M(n,θn)跑一下,计算出Cross Validation error,选择使这个error最小的模型次数k
3 最终训练:给定阶数k,训练得出在Training Set+CV Set上,使Training error最小的参数θ,得到模型M(k,θk’)
效果评估:
用Test Set在3中得到的模型M(k,θk’)(此时所选模型已经固定了,不能再改参数了)跑一下,计算出Test error,作为对于模型泛化能力的评估,也就是对于未知数据的预测准确率。
重要的一点是,Test Set中的数据必须是训练出来的模型之前所没有见过的,这样才能预测模型对于新来的未知数据的预测能力。所以Test Set不能参与模型选择的过程,只能在模型固定后作为一个效果评估,来看看训练出来的模型如果遇到新的数据效果怎么样,能不能上线。

上面这种是基本的交叉验证,有一种效果和时间开销都适中的变体,也就是n-fold交叉验证,是现在做机器学习实验最常用的做法:
1 数据按比例划分为(广义)训练集A、测试集B
2 使用(广义)训练数据A进行n-fold验证,(广义)训练集分为a1~an共n份,n份中的每一份ai轮流做CV set,其余n-1份作为Training set,这样训练n次,取n次所得CV error平均值作为一个模型最终的CV error,以此选出最优模型参数。
3 再用整个(广义)训练集A在选出的最优模型参数下训练出一个模型。
4 最后在测试集B上测试给出结果。