首先我们有一组医疗数据,以有无心脏疾病为标准记录各个患者的特征。

然后给出一名新患者的特征信息,判断他是否得心脏疾病。
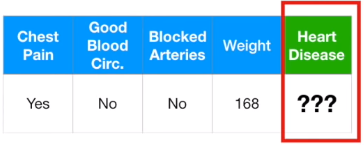
接着我们要选出一种最合适的机器学习方法。然而方法有许多种,包括logistics regression(逻辑回归)、K-nearest neighbors(最近邻算法)、support vector machine(支持向量机、SVM)等等,我们该如何从中挑选?
Cross Validation(交叉验证)允许我们比较不同的机器学习方法,并且认识到它们在实践中的表现。
对于上述中收集到的医疗数据,我们需要做两件事情:
- 估算机器学习方法需要使用的参数(在机器学习的术语中被称为“算法训练(Training the Algorithm)”)
- 评估机器学习方法的工作成果(在机器学习的术语中被称为“算法测试(Testing the Algorithm)”)
换句话说,我们需要将源数据集划分为两个部分,一部分用于训练,另一部分用于测试。
顺带一提,75%用于训练,25%用于测试效果更佳。
交叉验证法并不关心是哪75%或是哪25%,因为它会尝试各种组合。曾作为训练数据的数据集也可用作测试数据,反之亦然。
在极端情况下,我们甚至可以把每个个体作为一部分,这种方法称为“留一交叉验证(leave one out cross validation)”。
在实际应用中,比较常见的是将数据集划分为10个部分,这种方法被称为“十折交叉验证(ten-fold cross validation)”。
扩展:有些机器学习方法(如岭回归Ridge Regression)会包含一个“调整参数(tuning parameter)”,在这种情况下,可以使用十折交叉验证来帮助寻找最佳的调整参数值。
最后,将各个机器学习方法中的所有组合结果分别叠加,进行比较,从而挑选出最合适的机器学习方法。

