对数据集的划分
机器学习中训练模型中,我们通常要将数据分成训练集、测试集,有时还有验证集。
训练集用来训练模型,验证集用来训练模型的超参数,最终测试集用于评估模型预测的好坏。
误差估计
验证的关键在于衡量误差,常见的误差衡量标准是均方差和方根均方差, 分别为交叉验证的方差和标准差。
验证策略
虽然大体对数据就只有这三种分法,但分完之后怎么用还是一个问题,这就是验证策略,常用的有如下方法:
验证集方法(The Validation Set Approach)
最简单的方法,把整个数据集固定地分成训练集和测试集。
缺点
-
最终模型与参数的选取将极大程度依赖于你对训练集和测试集的划分,如果划分的好误差就会很小,如果划分的不好误差就会很大
-
该方法只用了部分数据进行模型的训练,意味着我们无法充分利用手头的数据,适用于数据量比较大的情况下(浪费一些也无所谓)。
交叉验证(Cross-Validation)
基于此,有人就提出了 交叉验证(Cross-Validation) 方法。交叉验证,顾名思义,就是重复地使用数据,把得到的样本数据进行切分,组合为多组不同的训练集和测试集。所谓“交叉”,就是这次训练集中的样本在下次可能成为测试集中的样本。
这是目前最主流的一种验证策略,据切分的方法不同,交叉验证分为下面三种:
简单交叉验证
随机地将样本数据分为两部分(比如: 70% 的训练集,30% 的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。可见这是最简单的一种交叉验证。
⭐️K 折交叉验证 (K-Fold Cross Validation)
是简单交叉验证的升级版,K 折交叉验证会把样本数据随机的分成 K 份,每次随机的选择 K-1 份作为训练集,剩下的 1 份做测试集。当这一轮完成后,重新随机选择 K-1 份来训练数据。若干轮(小于 K)之后,选择损失函数评估最优的模型和参数。
目前这种方法最为常用。
留一交叉验证 (Leave-one-out Cross Validation,LOOCV)
它是第二种情况的特例,只用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复 N 次(N 为数据集的数据数量)。
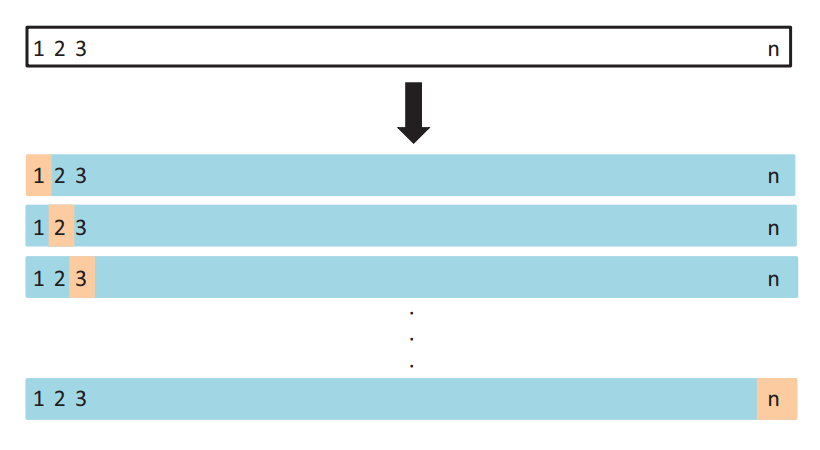
自助法(bootstrapping)
有 m 个样本(m 很小),每次在这 m 个样本中随机采集一个样本,放入训练集,采样完后把样本放回。重复采集 m 次,得到 m 个样本组成的训练集。当然,这 m 个样本中很有可能有重复的样本数据。同时,用没有被采样到的样本做测试集。这样接着进行交叉验证。由于我们的训练集有重复数据,这会改变数据的分布,因而训练结果会有估计偏差,因此,此种方法不是很常用,除非数据量真的很少,比如小于 20 个。
何时使用哪种方法?
交叉验证用在数据不是很充足的时候,一般来将数据样本量小于一万时采用交叉验证。如果样本大于一万,最基础的方法就足够用了
对于交叉验证的使用,如果我们只是对数据做一个初步的模型建立,不是要做深入分析的话,简单交叉验证就可以了。否则一般就用 S 折交叉验证。留一交叉验证主要用于样本量非常少的情况,比如 N 小于 50 时一般采用 LOOCV 方法。如果数据量极其小,比如小于 20 个,则用自助法。