1、测试数据的真正意义是什么?
在上篇博客中,我们看到测试集和训练集在同一个模型上会表现不同的结果。我们通过学习曲线可以直观的看到具体是过拟合还是欠拟合,从而调整参数,进行不断验证,直到找到一个在训练集表现好的数据。 总结一句话,就是通过测试数据进行对模型的调优。
2、 依靠测试数据来调优模型,会不会存在模型对测试数据形成过拟合?
会存在,因为我们是围绕测试数据集来验证模型的。所以要介绍一种新的验证方法,就是交叉验证(cross validation)。
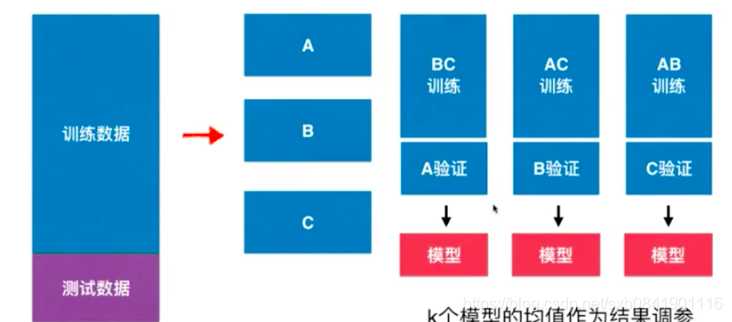
通过上图可以查看,交叉验证是原来数据分为训练数据和测试数据,然后把训练数据分为K份(k=3,5,10)然后用其中1份作为验证、其余K-1份作为训练,从而得到K个模型,然后针对K的模型均值作为调参,记下来我们看看用Sklearn中的代码如何实现。
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666)
def test_using_split():
"""
这里直接使用网格的方式去搜索
:return:
"""
best_k, best_p, best_score = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(n_neighbors=k, p=p, weights='distance')
knn_clf.fit(X_train, y_train)
scores = knn_clf.score(X_test, y_test)
if scores > best_score:
best_score = scores
best_k = k
best_p = p
print 'best_k:', best_k
print 'best_p:', best_p
print 'best_score:', best_score
# best_k: 3
# best_p: 4
# best_score: 0.9860917941585535
def test_using_cross_validation():
"""
用交叉验证的方法获取最佳参数
:return:
"""
best_k, best_p, best_score = 0, 0, 0
for k in range(2, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=k, p=p)
scores = cross_val_score(knn_clf, X_train, y_train)
score = np.mean(scores)
if score > best_score:
best_k, best_p, best_score = k, p, score
print 'best_k:', best_k
print 'best_p:', best_p
print 'best_score:', best_score
# best_k: 2
# best_p: 2
# best_score: 0.9823599874006478通过两种方法搜索,会发现找到最佳参数是不一样的, 用了交叉验证方法找到KNN分类方法的最佳参数都是2,并且最高评分是0.98。 但此刻要注意,利用交叉验证的方法,0.98不能代表模型在测试集上的分数,而真正意义是在3个交叉验证的模型评分的平均值。
要获取最好模型在测试集上的数据应该按照下面方式:
best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors=2, p=2)
best_knn_clf.fit(X_train, y_train)
print best_knn_clf.score(X_test, y_test)把获取到的最佳参数初始化分类器,然后用分类器再验证测试集。
这个结果是:0.980528511821975
通过对比就会发现,这个分数其实比没有用交叉验证获取的分数(0.9860917941585535)要低。 但是这里要注意,利用交叉验证的数据在其他测试集上有更好的效果。
最后我们稍微总结一下:
1、交叉验证用来寻找最好的超参数,它有时在测试数据集上表现没有其他好,但它的泛化能力强
2、cross_val_score这个方法默认的cv=3,表示把训练集分为3份,但是可以通过设置为更高。设置越高,则找到的模型泛化能力更强,但是同样计算复杂度会越高。