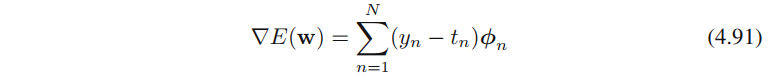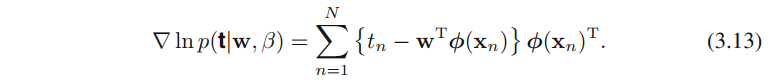本节小结
本节介绍了概率判别式模型,即直接对
进行建模。与4.2节的概率生成式模型相比,概率判别式⽅法通常有更少的可调节参数需要确定;预测表现也会提升,尤其是当类条件概率密度的假设没有很好地近似真实分布时。
在做分类之前,会使⽤⼀个固定基函数变换
先对x做下非线性变换,这也与第3章中讨论的回归模型类似。
logistic回归模型是典型的概率判别式模型。二分类情形下,在4.2节⽣成式⽅法的讨论中,我们看到在⼀些相当⼀般的假设条件下,类别
的后验概率可以写成作⽤在特征向量
的线性函数上的logistic sigmoid函数的形式,即
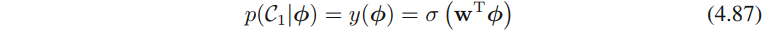
其中,σ(·)是公式(4.59)定义的logistic sigmoid函数。这个模型被称为logistic回归,需要强调的⼀点是,这是⼀个分类模型⽽不是回归模型。直接对公式4.87建模即可求的w的解(比如利用最大似然方法)。
类似的,多分类请向下根据公式4.62-4.63、4.68-4.70,可得
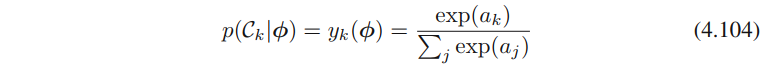
其中
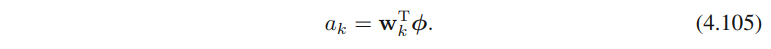
互动话题
- 对比4.3.2节的最大似然与4.2.2节的最大似然?
根据公式4.71,再结合4.2节的笔记,4.2.2节的最大似然 是针对t,X的联合概率分布。
根据公式4.89,4.3.2节的最大似然 是针对t的分布的。 - 公式4.91(logistic回归下的负对数似然的梯度)、公式4.109(多分类logistic回归下的负对数似然的梯度)、公式3.13的形式完全一样,这个很有意思,值得深入对比分析。