达观杯数据竞赛系列(一)
1,下载数据,读取数据,观察数据:
压缩的数据近1个G,解压后的数据也是2.6个G,分为两个csv文件。
数据包含2个csv文件:
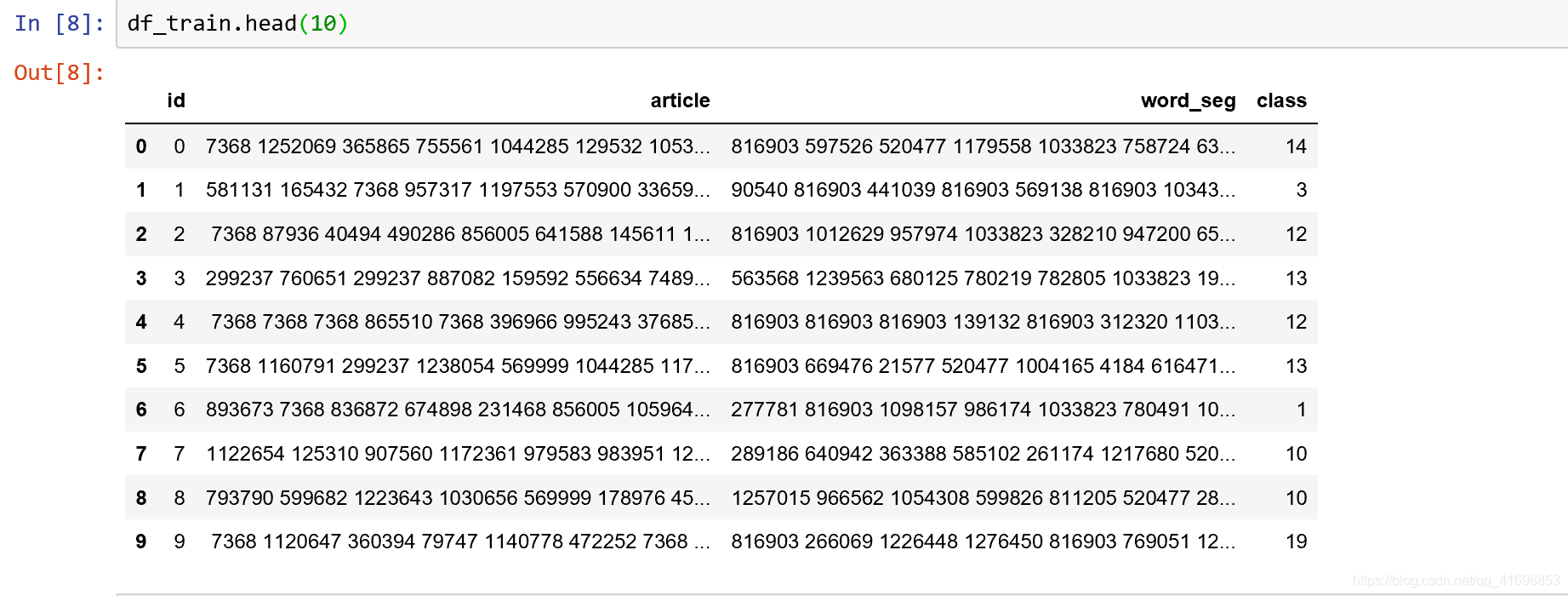
》train_set.csv:此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列:
第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的!
》test_set.csv:此数据用于测试。数据格式同train_set.csv,但不包含class。
注:test_set与train_test中文章id的编号是独立的。
2,将训练集拆分为训练集和验证集:
利用Python语言的pandas包可以分别读取训练集和测试集:
代码如下:
df_train = pd.read_csv(‘Data/001daguan/train_set.csv’)
若内存不足可添加参数:nrows=1000
df_test = pd.read_csv(‘Data/001daguan/test_set.csv’)
3,对数据以及赛题的理解:
读取训练集的前十行数据,可见数据的columns分别为:id,article,word_seg,class,其中class即为label属性,需要正确分类的属性。