一、TF-IDF的主要思想
1、计算词频
词频(TF) = 某个词在文章中的出现次数
文章有长短之分,为了便于不同文章的比较,做"词频"标准化。
词频(TF) = 某个词在文章中的出现次数 / 文章总词数
或者 词频(TF) = 某个词在文章中的出现次数 / 拥有最高词频的词的次数
2、某个词在文章中的出现次数
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
逆文档频率(IDF) = log(语料库的文档总数/包含该词的文档总数+1)
3、计算TF-IDF
TF-IDF = 词频(TF) * 逆文档频率(IDF)
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。
所以,自动提取关键词的算法就是计算出文档的每个词的TF-IDF值,
然后按降序排列,取排在最前面的几个词。
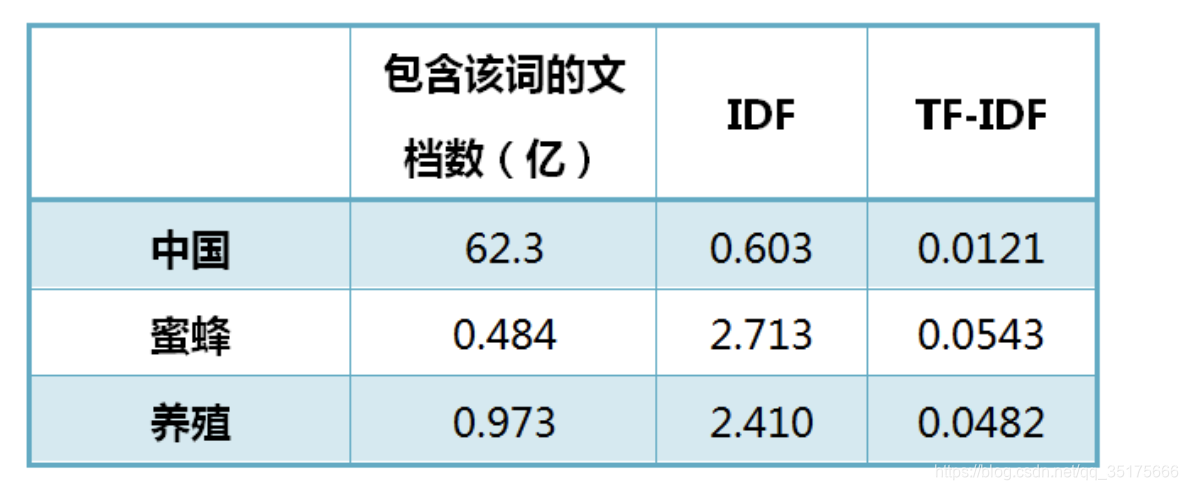
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)
所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
总结:
TF-IDF算法的优点是简单快速,结果比较符合实际情况。
缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。
(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
二、TF-IDF的代码实现
sklearn中TfidfVectorizer函数的参数说明:
https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
代码运行截图:
参考博客:
https://www.cnblogs.com/cppb/p/5976266.html
https://blog.csdn.net/devcy/article/details/89071572